Tag Archives: generative ai
Supplier Relationship Management & Machine Learning / AI

Supplier relationship management (SRM) is the process of managing supplier relationships to develop and maintain a strategic procurement partnership. SRM includes focus areas such as supplier selection, procurement strategy development, procurement negotiation, and performance measurement and improvement. SRM has been around for over 20 years but we are now seeing new technologies such as machine learning come into play. What exactly does advanced analytics such as artificial intelligence (AI) / machine learning (ML) have to do with SRM? And how will AI/ML technologies transform procurement? What are some real-world machine learning use cases related to supplier relationships management? What are a few SRM KPIs/metrics which can be tracked by leveraging …
Artificial Intelligence (AI) for Telemedicine: Use cases, Challenges

In this post, you will learn about different artificial intelligence (AI) use cases of Telemedicine / Telehealth including some of key implementation challenges pertaining to AI / machine learning. In case you are working in the field of data science / machine learning, you may want to go through some of the challenges, primarily AI related, which is thrown in Telemedicine domain due to upsurge in need of reliable Telemedicine services. What is Telemedicine? Telemedicine is the remote delivery of healthcare services, using digital communication technologies. It has the potential to improve access to healthcare, especially in remote or underserved communities. It can be used for a variety of purposes, including …
Scatter plot Matplotlib Python Example
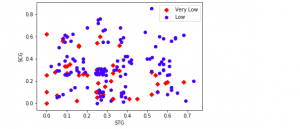
If you’re a data scientist, data analyst or a Python programmer, data visualization is key part of your job. And what better way to visualize all that juicy data than with a scatter plot? Matplotlib is your trusty Python library for creating charts and graphs, and in this blog we’ll show you how to use it to create beautiful scatter plots using examples and with the help of Matplotlib library. So dig into your data set, get coding, and see what insights you can uncover! What is a Scatter Plot? A scatter plot is a type of data visualization that is used to show the relationship between two variables. Scatter …
Weight Decay in Machine Learning: Concepts
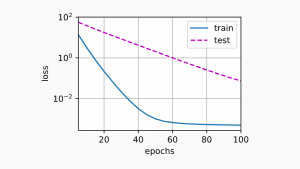
Weight decay is a popular technique in machine learning that helps to improve the accuracy of predictions. In this post, we’ll take a closer look at what weight decay is and how it works. We’ll also discuss some of the benefits of using weight decay and explore some possible applications. As data scientists, it is important to learn about concepts of weight decay as it helps in building machine learning models having higher generalization performance. Stay tuned! What is weight decay and how does it work? Weight decay is a regularization technique that is used to regularize the size of the weights of certain parameters in machine learning models. Weight …
Softmax Regression Explained with Python Example
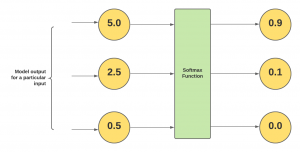
In this post, you will learn about the concepts of what is Softmax regression/function with Python code examples and why do we need them? As data scientist/machine learning enthusiasts, it is very important to understand the concepts of Softmax regression as it helps in understanding the algorithms such as neural networks, multinomial logistic regression, etc in a better manner. Note that the Softmax function is used in various multiclass classification machine learning algorithms such as multinomial logistic regression (thus, also called softmax regression), neural networks, etc. Before getting into the concepts of softmax regression, let’s understand what is softmax function. What’s Softmax function? Simply speaking, the Softmax function converts raw …
Information Theory, Machine Learning & Cross-Entropy Loss

What is information theory? How is information theory related to machine learning? These are some of the questions that we will answer in this blog post. Information theory is the study of how much information is present in the signals or data we receive from our environment. AI / Machine learning (ML) is about extracting interesting representations/information from data which are then used for building the models. Thus, information theory fundamentals are key to processing information while building machine learning models. In this blog post, we will provide examples of information theory concepts and entropy concepts so that you can better understand them. We will also discuss how concepts of …
Tensor Broadcasting Explained with Examples
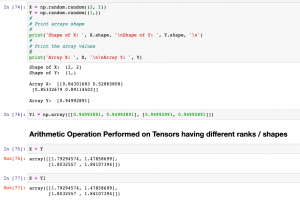
In this post, you will learn about the concepts of Tensor Broadcasting with the help of Python Numpy examples. Recall that Tensor is defined as the container of data (primarily numerical) most fundamental data structure used in Keras and Tensorflow. You may want to check out a related article on Tensor – Tensor explained with Python Numpy examples. Broadcasting of tensor is borrowed from Numpy broadcasting. Broadcasting is a technique used for performing arithmetic operations between Numpy arrays / Tensors having different shapes. In this technique, the following is done: As a first step, expand one or both arrays by copying elements appropriately so that after this transformation, the two tensors have the …
Regularization in Machine Learning: Concepts & Examples
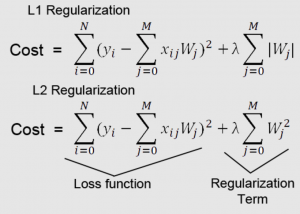
In machine learning, regularization is a technique used to avoid overfitting. This occurs when a model learns the training data too well and therefore performs poorly on new data. Regularization helps to reduce overfitting by adding constraints to the model-building process. As data scientists, it is of utmost importance that we learn thoroughly about the regularization concepts to build better machine learning models. In this blog post, we will discuss the concept of regularization and provide examples of how it can be used in practice. What is regularization and how does it work? Regularization in machine learning represents strategies that are used to reduce the generalization or test error of …
SVM Classifier using Sklearn: Code Examples
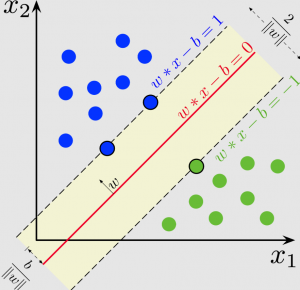
In this post, you will learn about how to train an SVM Classifier using Scikit Learn or SKLearn implementation with the help of code examples/samples. An SVM classifier, or support vector machine classifier, is a type of machine learning algorithm that can be used to analyze and classify data. A support vector machine is a supervised machine learning algorithm that can be used for both classification and regression tasks. The Support vector machine classifier works by finding the hyperplane that maximizes the margin between the two classes. The Support vector machine algorithm is also known as a max-margin classifier. Support vector machine is a powerful tool for machine learning and has been widely used …
Stochastic Gradient Descent Python Example
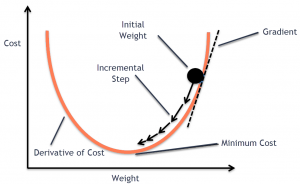
In this post, you will learn the concepts of Stochastic Gradient Descent (SGD) using a Python example. Stochastic gradient descent is an optimization algorithm that is used to optimize the cost function while training machine learning models. The most popular algorithm such as gradient descent takes a long time to converge for large datasets. This is where the variant of gradient descent such as stochastic gradient descent comes into the picture. In order to demonstrate Stochastic gradient descent concepts, the Perceptron machine learning algorithm is used. Recall that Perceptron is also called a single-layer neural network. Before getting into details, let’s quickly understand the concepts of Perceptron and the underlying learning …
Dummy Variables in Regression Models: Python, R
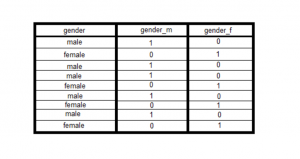
In linear regression, dummy variables are used to represent the categorical variables in the model. There are a few different ways that dummy variables can be created, and we will explore a few of them in this blog post. We will also take a look at some examples to help illustrate how dummy variables work. We will also understand concepts related to the dummy variable trap. By the end of this post, you should have a better understanding of how to use dummy variables in linear regression models. As a data scientist, it is important to understand how to use linear regression and dummy variables. What are dummy variables in …
Linear regression hypothesis testing: Concepts, Examples
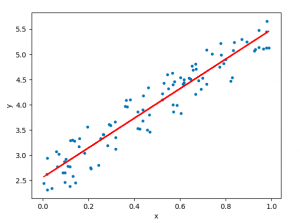
In relation to machine learning, linear regression is defined as a predictive modeling technique that allows us to build a model which can help predict continuous response variables as a function of a linear combination of explanatory or predictor variables. While training linear regression models, we need to rely on hypothesis testing in relation to determining the relationship between the response and predictor variables. In the case of the linear regression model, two types of hypothesis testing are done. They are T-tests and F-tests. In other words, there are two types of statistics that are used to assess whether linear regression models exist representing response and predictor variables. They are …
Correlation Concepts, Matrix & Heatmap using Seaborn
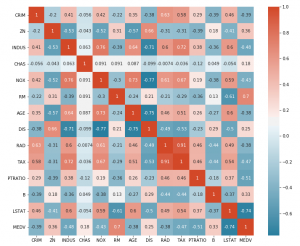
In this blog post, we’ll be discussing correlation concepts, matrix & heatmap using Seaborn. For those of you who aren’t familiar with Seaborn, it’s a library for data visualization in Python. So if you’re looking to up your data visualization game, stay tuned! We’ll start with the basics of correlation and move on to discuss how to create matrices and heatmaps with Seaborn. Let’s get started! Introduction to Correlation Correlation is a statistical measure that expresses the strength of the relationship between two variables. The two main types of correlation are positive and negative. Positive correlation occurs when two variables move in the same direction; as one increases, so do …
When to Use Which Clustering Algorithms?
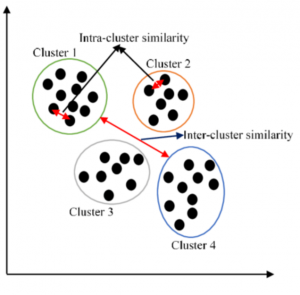
There are many clustering machine learning algorithms to choose from when you want to cluster data. But which one should you use in a particular situation? In this blog post, we will explore the different clustering algorithms and explain when each one is most appropriate. We will also provide examples so that you can see how these algorithms work in practice. What clustering is and why it’s useful Simply speaking, clustering is a technique used in machine learning to group data points together. The goal of clustering is to find natural groups, or clusters, in the data. Clustering algorithms are used to automatically find these groups. Clustering is useful because …
Steps for Evaluating & Validating Time-Series Models
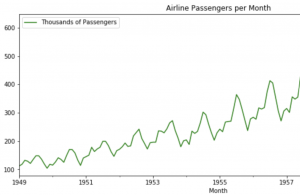
Time-series machine learning models are becoming increasingly popular due to the large volume of data that is now available. These models can be used to make predictions about future events, and they are often more accurate than traditional methods. However, it is important to properly evaluate (check accuracy by performing error analysis) and validate these models before you put them into production. In this blog post, we will discuss the different ways that you can evaluate and validate time series machine learning models. We will also provide some tips on how to improve your results. As data scientists, it is important to learn the techniques related to evaluating time-series models. …
Machine Learning with Alteryx: Examples
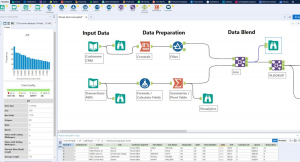
Alteryx is a self-service data analytics software platform that enables users to easily prep, blend, and analyze data all in one place. It is a powerful tool that can be used in a variety of machine learning scenarios. It can be used to clean and prepare data, and develop, evaluate and deploy machine learning (ML) models. It offers a variety of features and tools that can be used to preprocess data, choose algorithms, train models, and evaluate results. In this blog post, we will discuss some of the ways that Alteryx can be used in machine learning. We will also provide examples of how to use Alteryx in machine learning scenarios. …

I found it very helpful. However the differences are not too understandable for me