Tag Archives: Data Science
Outlier Detection Techniques in Python: Examples
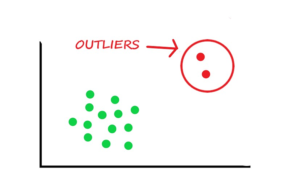
In the realm of data science, mastering outlier detection techniques is paramount for ensuring data integrity and robust machine learning model performance. Outliers are the data points which deviate significantly from the norm. The outliers data points can greatly impact the accuracy and reliability of statistical analyses and machine learning models. In this blog, we will explore a variety of outlier detection techniques using Python. The methods covered will include statistical approaches like the z-score method and the interquartile range (IQR) method, as well as visualization techniques like box plots and scatter plots. Whether you are a data science enthusiast or a seasoned professional, it is important to grasp these …
Boston Housing Dataset Linear Regression: Predicting House Prices
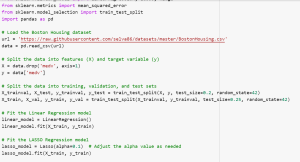
Predicting house prices accurately is crucial in the real estate industry. However, it can be challenging to determine the factors that significantly impact house prices. Without a clear understanding of these factors, accurate predictions are difficult to achieve. The Boston Housing Dataset addresses this problem by providing a comprehensive set of variables that influence house prices in the Boston area. However, effectively utilizing this dataset and building robust predictive models require appropriate techniques and evaluation methods. In this blog, we will provide an overview of the Boston Housing Dataset and explore linear regression, LASSO, and Ridge regression as potential models for predicting house prices. Each model has its unique properties …
ChatGPT Cheat Sheet for Data Scientists

With the explosion of data being generated, data scientists are facing increased pressure to analyze and interpret large amounts of text data effectively. However, this can be a challenging task, especially when dealing with unstructured data. Additionally, data scientists often spend a significant amount of time manually generating text and answering complex questions, which can be a time-consuming process. Welcome ChatGPT! ChatGPT offer a powerful solution to these challenges. By learning different ChatGPT prompts, data scientists can significantly become super productive while generating relevant insights, answer complex questions, and perform machine learning tasks with ease such as data preprocessing, hypothesis testing, training models, etc. In this blog, I will provide …
Python Tesseract PDF & OCR Example
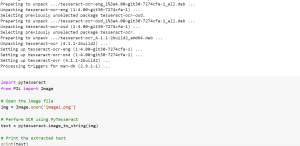
Have you ever needed to extract text from an image or a PDF file? If so, you’re in luck! Python has an amazing library called Tesseract that can perform Optical Character Recognition (OCR) to extract text from images and PDFs. In this blog, I will share sample Python code using with you can use Tesseract to extract text from images and PDFs. As a data scientist, it can be very helpful and useful to be able to extract text from images or PDFs, especially when working with large amounts of data found in receipts, invoices, etc. Tesseract is an OCR engine widely used in the industry, known for its accuracy …
Gaussian Mixture Models: What are they & when to use?
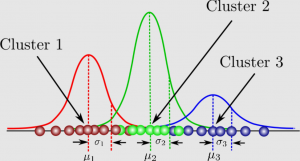
In machine learning and data analysis, it is often necessary to identify patterns and clusters within large sets of data. However, traditional clustering algorithms such as k-means clustering have limitations when it comes to identifying clusters with different shapes and sizes. This is where Gaussian mixture models (GMMs) come in. But what exactly are GMMs and when should you use them? Gaussian mixture models (GMMs) are a type of machine learning algorithm. They are used to classify data into different categories based on the probability distribution. Gaussian mixture models can be used in many different areas, including finance, marketing and so much more! In this blog, an introduction to gaussian …
ChatGPT for Data Science Projects – Examples

Data science is all about turning raw data into actionable insights and outcomes that drive value for your organization. But as any data science professional knows, coming up with new, innovative ideas for your projects is only half the battle. The real challenge is finding a way to turn those ideas into results that can be used to drive business success by doing proper data analysis and building machine learning models using most appropriate algorithms. Unfortunately, many data science professionals struggle with this second step, which can lead to frustration, wasted time and resources, and missed opportunities. That’s where ChatGPT comes in. As a language model trained by OpenAI, ChatGPT …
Sklearn Algorithms Cheat Sheet with Examples

The Sklearn library, short for Scikit-learn, is one of the most popular and widely-used libraries for machine learning in Python. It offers a comprehensive set of tools for data analysis, preprocessing, model selection, and evaluation. As a beginner data scientist, it can be overwhelming to navigate the various algorithms and functions within Sklearn. This is where the Sklearn Algorithms Cheat Sheet comes in handy. This cheat sheet provides a quick reference guide for beginners to easily understand and select the appropriate algorithm for their specific task. In this cheat sheet, I have compiled a list of common supervised and unsupervised learning algorithms, along with their Sklearn classes and example use …
Supervised & Unsupervised Learning Difference
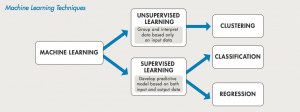
Supervised and unsupervised learning are two different common types of machine learning tasks that are used to solve many different types of business problems. Supervised learning uses training data with labels to create supervised models, which can be used to predict outcomes for future datasets. Unsupervised learning is a type of machine learning task where the training data is not labeled or categorized in any way. For beginner data scientists, it is very important to get a good understanding of the difference between supervised and unsupervised learning. In this post, we will discuss how supervised and unsupervised algorithms work and what is difference between them. You may want to check …
Sklearn Neural Network Example – MLPRegressor
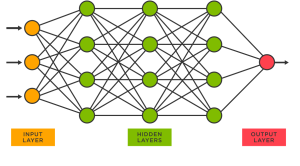
Are you interested in using neural networks to solve complex regression problems, but not sure where to start? Sklearn’s MLPRegressor can help you get started with building neural network models for regression tasks. While the packages from Keras, Tensorflow or PyTorch are powerful and widely used in deep learning, Sklearn’s MLPRegressor is still an excellent choice for building neural network models for regression tasks when you are starting on. Recall that Python Sklearn library is one of the most popular machine learning libraries, and it provides a wide range of algorithms for classification, regression, clustering, dimensionality reduction, and more. In this blog post, we will be focusing on training a …
Neural Networks Interview Questions – Quiz #45

Are you preparing for a job interview in the field of deep learning or neural networks? If so, you’re likely aware of how complex and technical these topics can be. In order to help you prepare, we’ve put together a list of common neural network interview questions and answers in form of multiple-choice quiz. The quiz in this blog post covers basic concepts related to neural network layers, perceptron, multilayer perceptron, activation functions, feedforward networks, backpropagation, and more. We’ve included 15 multiple-choice questions, as well as 5 additional questions specifically focused on the backpropagation algorithm. I will be posting many more quizzes on the neural networks in time to come, …
Google’s Free Machine Learning Courses: Learn from the Best

Machine learning has become a fundamental part of almost every industry today. With the increasing demand for data scientists and machine learning engineers, it has become imperative for professionals to keep themselves updated with the latest tools and techniques. Fortunately, Google offers a range of free machine learning courses that cater to professionals of all expertise levels. In this blog, we will explore the top Google machine learning courses that will help learners enhance their skills and stay ahead of the game. List of Free Machine Learning Courses by Google The following is a list of free machine learning courses from Google which you can take online. These courses can …
KMeans Silhouette Score Python Example
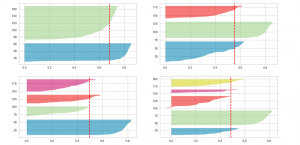
If you’re building machine learning models for solving different prediction problems, you’ve probably heard of clustering. Clustering is a popular unsupervised learning technique used to group data points with similar features into distinct clusters. One of the most widely used clustering algorithms is KMeans, which is popular due to its simplicity and efficiency. However, one major challenge in clustering is determining the optimal number of clusters that should be used to group the data points. This is where the Silhouette Score comes into play, as it helps us measure the quality of clustering and determine the optimal number of clusters. Silhouette score helps us get further clarity for the following …
Why & When to use Eigenvalues & Eigenvectors?

Eigenvalues and eigenvectors are important concepts in linear algebra that have numerous applications in data science. They provide a way to analyze the structure of linear transformations and matrices, and are used extensively in many areas of machine learning, including feature extraction, dimensionality reduction, and clustering. In simple terms, eigenvalues and eigenvectors are the building blocks of linear transformations. Eigenvalues represent the scaling factor by which a vector is transformed when a linear transformation is applied, while eigenvectors represent the directions in which the transformation occurs. In this post, you will learn about why and when you need to use Eigenvalues and Eigenvectors? As a data scientist/machine learning Engineer, one must …
Z-score or Z-statistics: Concepts, Formula & Examples
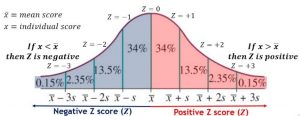
Z-score, also known as the standard score or Z-statistics, is a powerful statistical concept that plays a vital role in the world of data science. It provides a standardized method for comparing data points from different distributions, allowing data scientists to better understand and interpret the relative positioning of individual data points within a dataset. Z-scores represent a statistical technique of measuring the deviation of data from the mean. It is also used with Z-test which is a hypothesis testing statistical technique (one sample Z-test or two samples Z-test). As a data scientist, it is of utmost importance to be well-versed with the z-score formula and its various applications. Having …
Descriptive Statistics – Key Concepts & Examples
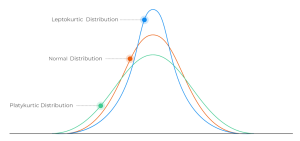
Descriptive statistics is a branch of statistics that deals with the analysis of data. It is concerned with summarizing and describing the characteristics of a dataset. It is one of the most fundamental tool for data scientists to understand the data as they get started working on the dataset. In this blog post, I will cover the key concepts of descriptive statistics, including measures of central tendency, measures of spread and statistical moments. What’s Descriptive Statistics & Why do we need it? Descriptive statistics is used to summarize and describe the characteristics of a dataset in terms of understanding its mean & related measures, spread or dispersion of the data …
Backpropagation Algorithm in Neural Network: Examples
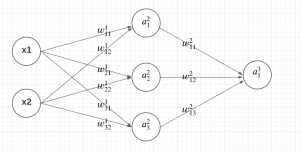
Artificial Neural Networks (ANN) are a powerful machine learning / deep learning technique inspired by the workings of the human brain. Neural networks comprise multiple interconnected nodes or neurons that process and transmit information. They are widely used in various fields such as finance, healthcare, and image processing. One of the most critical components of an ANN is the backpropagation algorithm. Backpropagation algorithm is a supervised learning technique used to adjust the weights of a Neural Network to minimize the difference between the predicted output and the actual output. In this post, you will learn about the concepts of backpropagation algorithm used in training neural network models, along with Python …
I found it very helpful. However the differences are not too understandable for me