
Data science is all about turning raw data into actionable insights and outcomes that drive value for your organization. But as any data science professional knows, coming up with new, innovative ideas for your projects is only half the battle. The real challenge is finding a way to turn those ideas into results that can be used to drive business success by doing proper data analysis and building machine learning models using most appropriate algorithms. Unfortunately, many data science professionals struggle with this second step, which can lead to frustration, wasted time and resources, and missed opportunities. That’s where ChatGPT comes in.
As a language model trained by OpenAI, ChatGPT can help you quickly and easily generate code in Python or any other relevant programming languages for your data science / machine learning projects, saving you time and helping you get to the insights and outcomes you need faster. In this blog, we’ll explore some real-world examples of how ChatGPT can be used in data science projects to help you achieve your goals and drive business success. So buckle up and get ready to see the potential of ChatGPT in action!
Setting up ChatGPT for Data Science Projects
ChatGPT can be leveraged to assist with various aspects of data science projects, such as data preprocessing, exploratory data analysis, model training and evaluation, and even report generation. In this section, we will learn about setting up ChatGPT such that all of the activities mentioned earlier can be performed. The following prompt (in italics) helps ChatGPT get set up. I have obtained the description of data from the page from where I downloaded this data.
Be an expert data scientist.
Help me extract insights from the data. Here is the data set which concerns with city-cycle fuel consumption in miles per gallon, to be predicted in terms of 3 multivalued discrete and 5 continuous attributes.
Here is the detail of the attributes.
- mpg: continuous
- cylinders: multi-valued discrete
- displacement: continuous
- horsepower: continuous
- weight: continuous
- acceleration: continuous
- model year: multi-valued discrete
- origin: multi-valued discrete
- car name: string (unique for each instance)
Here are the 20 records related to above data.
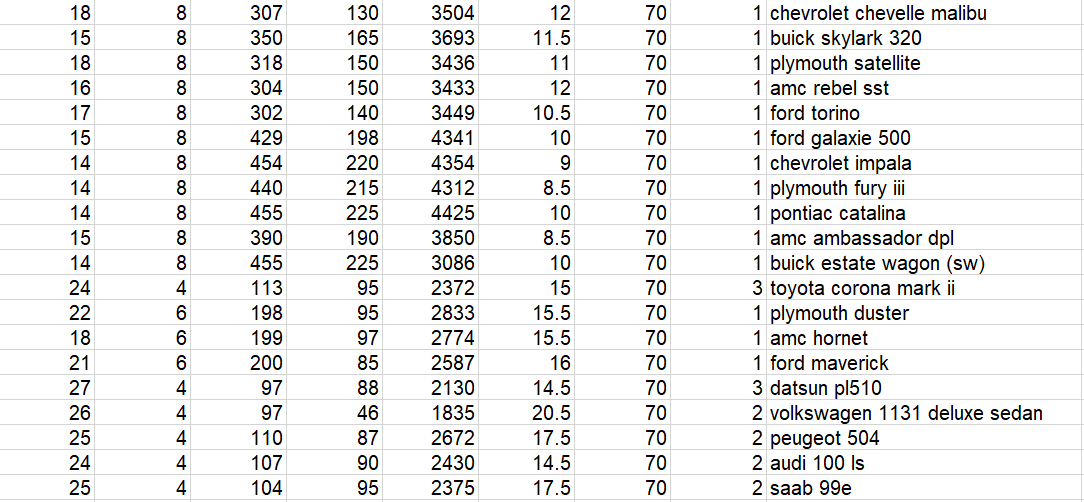
Have you understood the dataset and related information?
I have pasted the above image as I wasn’t having a decent way to copy and paste in the blog. You would however paste the data as part of the current prompt (in italics).
Once the above prompt is executed, the following is the ChatGPT output.

Exploratory Data Analysis with ChatGPT Prompts
In this section, we will learn about how to use ChatGPT prompts for performing exploratory data analysis. Exploratory data analysis (EDA) is a crucial step in any data science project, as it helps to understand the data, detect anomalies, and identify patterns that can inform the next steps of the project.
Get insights from Dataset
First and foremost, lets see if there are any insights we can get from the dataset. Use the following prompt to extract the insight.
Give me top 3 insights from the dataset
The following gets printed as the output from ChatGPT:

Identify different hypotheses
ChatGPT prompts can as well be used for hypothesis formulation and testing, helping data scientists to streamline the process of hypothesis testing and generate new insights from their data. By using ChatGPT prompts to formulate hypotheses, you can ensure that their hypotheses are specific, testable, and relevant to their data, while also saving time and reducing bias in the hypothesis formulation process. With ChatGPT’s ability to generate human-like questions and prompts, you can also test your hypotheses more effectively by generating relevant test cases and identifying potential confounding variables.
Lets look at the following prompt which can be used for hypothesis identification.
What hypothesis do you think can be tested from the data given earlier?
The following is the output by ChatGPT. Note various different hypotheses. We can take each one of them , formulate hypothesis and perform hypothesis testing.

Hypothesis formulation and testing using Python
Take each one of the hypothesis, formulate hypothesis and perform hypothesis testing using Python code. Here is the prompt you can work with:
Create hypothesis formulation for the following hypothesis, identify appropriate hypothesis test, write Python code for performing hypothesis test
Cars with more cylinders have a lower fuel efficiency than cars with fewer cylinders.
The following gets printed by ChatGPT:

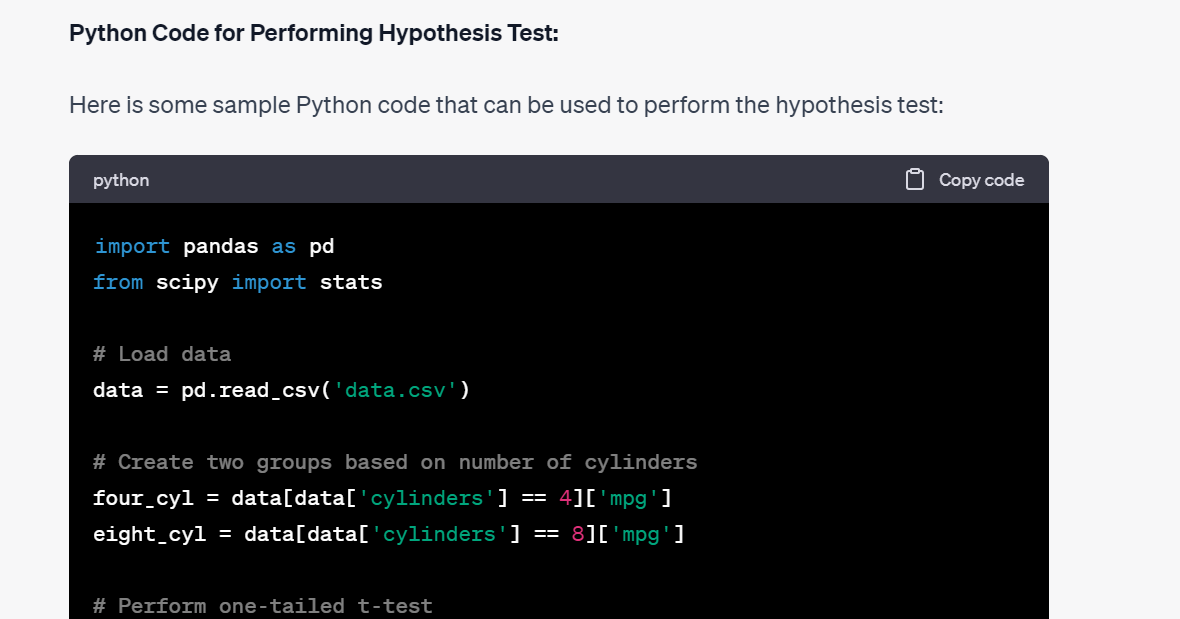
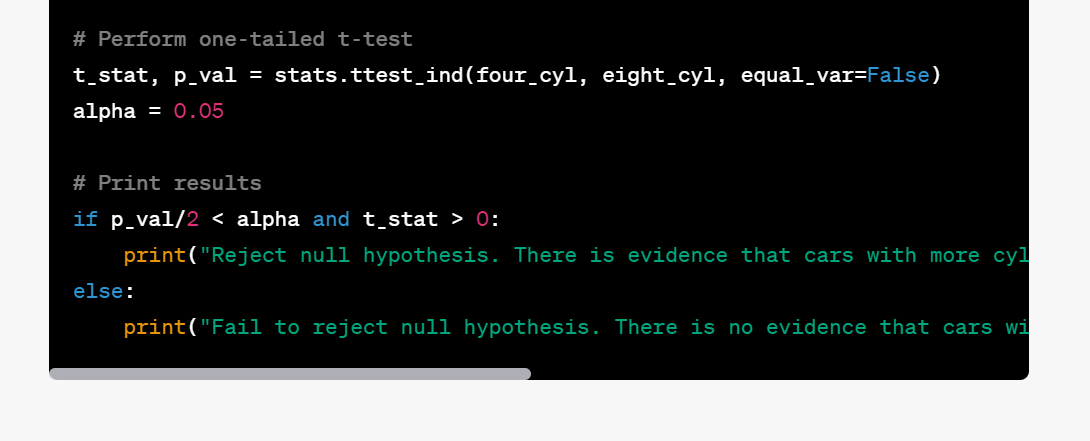
You can execute this prompt for all the hypothesis to identify the relationships that you would work with, while building machine learning models.
Visualizing Relationships using Plots with ChatGPT
You can be more specific and ask to create most appropriate type of plots to visualize the relationship. In case, you are not sure, you can anyways use this prompt:
What Python code can help visualize the relationships existing in the dataset?
The following code will get printed which when you execute will result in creating scatter plots shown ahead.
import pandas as pd
import matplotlib.pyplot as plt
# Load the data from a CSV file
data = pd.read_csv('auto-mpg.csv', delimiter='\s+', header=None, names=['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin', 'car_name'])
# Drop any rows with missing values
data.dropna(inplace=True)
# Create scatterplots of each continuous variable against the target variable
fig, axs = plt.subplots(2, 3, figsize=(15, 10))
axs[0, 0].scatter(data['cylinders'], data['mpg'])
axs[0, 0].set_xlabel('Cylinders')
axs[0, 0].set_ylabel('MPG')
axs[0, 1].scatter(data['displacement'], data['mpg'])
axs[0, 1].set_xlabel('Displacement')
axs[0, 1].set_ylabel('MPG')
axs[0, 2].scatter(data['horsepower'], data['mpg'])
axs[0, 2].set_xlabel('Horsepower')
axs[0, 2].set_ylabel('MPG')
axs[1, 0].scatter(data['weight'], data['mpg'])
axs[1, 0].set_xlabel('Weight')
axs[1, 0].set_ylabel('MPG')
axs[1, 1].scatter(data['acceleration'], data['mpg'])
axs[1, 1].set_xlabel('Acceleration')
axs[1, 1].set_ylabel('MPG')
axs[1, 2].scatter(data['model_year'], data['mpg'])
axs[1, 2].set_xlabel('Model Year')
axs[1, 2].set_ylabel('MPG')
plt.show()
The following plots will get created representing the relationships between response and predictor variables.
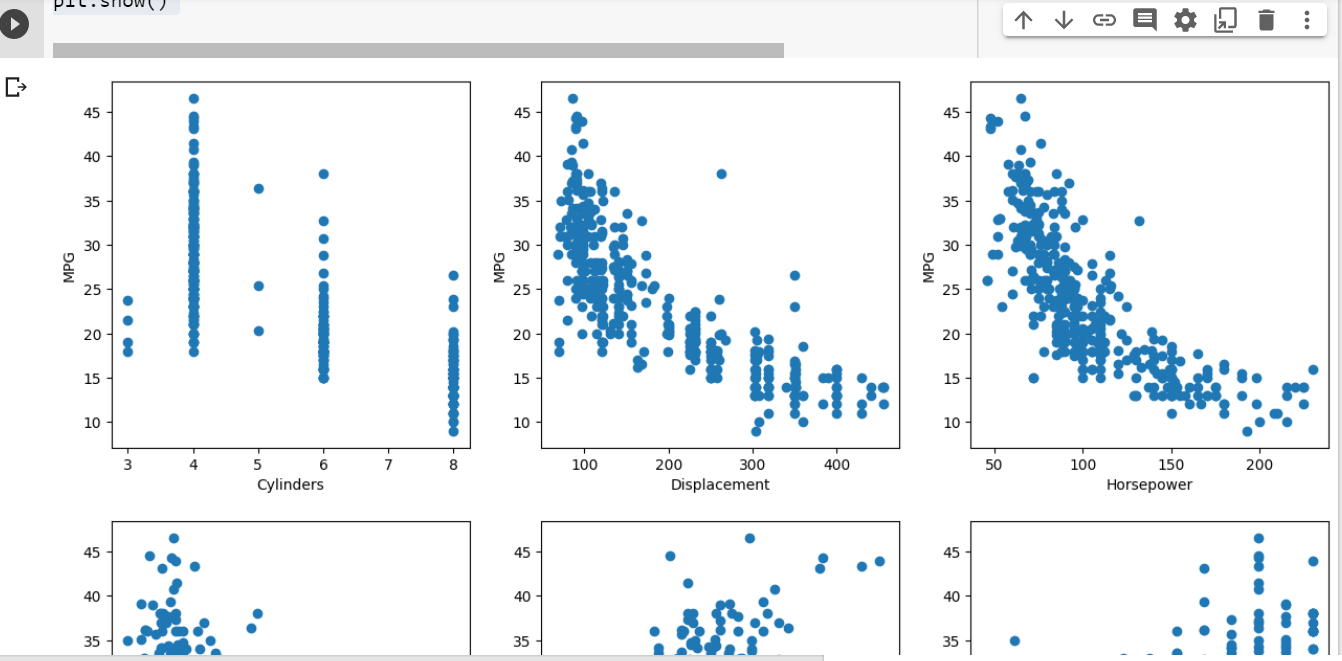
You can do multiple different things using similar prompts. Lets move ahead and train the machine learning models.
Building Predictive / Machine Learning Models using ChatGPT
Lets look into few prompts which will help in building predictive/machine learning models using ChatGPT. By using ChatGPT prompts, data scientists can generate new ideas for features, improve model performance, and optimize the model architecture. ChatGPT can also help in generating synthetic data for training models, thereby reducing the need for large amounts of labeled data.
Lets ask ChatGPT whether we can build predictive model using the data given. Here is the prompt:
Can I build a predictive model using this data? What can I predict?
The following is printed by ChattGPT.

Training the model using ML Algorithms & ChatGPT
You can use the following prompt to instruct ChatGPT to share Python code which can be used for training the model using linear regression. You can as well modify prompt to use random forest and other algorithms.
Create a Python code for linear regression model in which above data can be fed?
The above will output the following Python code.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data
data = pd.read_csv('data.csv')
# Split data into features (X) and target variable (y)
X = data.drop(['mpg', 'car name'], axis=1)
y = data['mpg']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit linear regression model to training data
reg = LinearRegression()
reg.fit(X_train, y_train)
# Evaluate performance on testing data
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# Print results
print("Mean Squared Error (MSE): {:.2f}".format(mse))
print("Root Mean Squared Error (RMSE): {:.2f}".format(rmse))
print("R-squared (R2): {:.2f}".format(r2))
The following prompt uses Random forest algorithm in the Python code.
Create a Python code for random forest regressor model in which above data can be fed?
The following code with Random forest algorithm will get printed. Execute the code and evaluate the model based on the R-squared and other metrics.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# Load data
data = pd.read_csv('data.csv')
# Split data into features (X) and target variable (y)
X = data.drop(['mpg', 'car name'], axis=1)
y = data['mpg']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit random forest regressor model to training data
reg = RandomForestRegressor(n_estimators=100, random_state=42)
reg.fit(X_train, y_train)
# Evaluate performance on testing data
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# Print results
print("Mean Squared Error (MSE): {:.2f}".format(mse))
print("Root Mean Squared Error (RMSE): {:.2f}".format(rmse))
print("R-squared (R2): {:.2f}".format(r2))
ChatGPT can as well be used for regularization and hyperparameter tuning in machine learning models. Regularization is a technique used to prevent overfitting of models by adding a penalty term to the loss function. ChatGPT prompts can be used to generate ideas for regularization techniques and help to identify the most effective regularization hyperparameters for a given model. Similarly, hyperparameter tuning is the process of selecting the optimal hyperparameters for a model to achieve the best performance. ChatGPT prompts can be used to generate ideas for hyperparameter tuning and to identify the most promising hyperparameter combinations for a given model.
Slides / PPT
The following is the slide which has got a list of all the prompts mentioned in this post apart from additional prompts. Enjoy your ride of building machine learning models with these prompts. If you like the slides, please feel free to share.
Conclusion
ChatGPT has a wide range of applications in data science projects, from exploratory data analysis and hypothesis formulation to building predictive and machine learning models. By leveraging the power of natural language processing, ChatGPT prompts can help data scientists to streamline their workflow, generate new insights from their data, and achieve more accurate and robust models. By following best practices and collaborating with other data science professionals, data scientists can harness the potential of ChatGPT to enhance their projects and achieve meaningful insights from their data.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me