Tag Archives: big data
CEP vs Traditional Database Examples
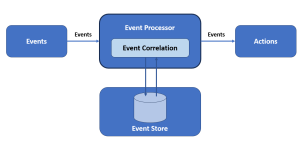
In this blog, we will learn about the differences between complex event processing (CEP) and traditional database querying with the help of examples. We will learn about how these two methodologies tackle data to extract meaningful insights but in fundamentally different ways. In complex event processing, data flows dynamically which is then matched with pre-defined patterns thereby generating insights in real-time. Traditional Database Querying In a conventional database querying scenario, the data is stored first, and then queries are run against this stored data to find patterns or retrieve information. This process is reactive, in that the query is formulated based on a need to find out something specific about …
Hypothesis Testing Steps & Examples
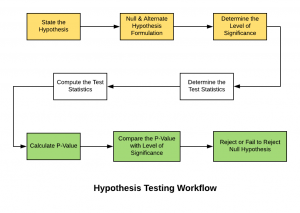
Hypothesis testing is a technique that helps scientists, researchers, or for that matter, anyone test the validity of their claims or hypotheses about real-world or real-life events in order to establish new knowledge. Hypothesis testing techniques are often used in statistics and data science to analyze whether the claims about the occurrence of the events are true, whether the results returned by performance metrics of machine learning models are representative of the models or they happened by chance. This blog post will cover some of the key statistical concepts including steps and examples in relation to what is hypothesis testing, how to formulate them and how to use them in …
85+ Free Online Books, Courses – Machine Learning & Data Science

This post represents a comprehensive list of 85+ free books/ebooks and courses on machine learning, deep learning, data science, optimization, etc which are available online for self-paced learning. This would be very helpful for data scientists starting to learn or gain expertise in the field of machine learning / deep learning. Please feel free to comment/suggest if I missed mentioning one or more important books that you like and would like to share. Also, sorry for the typos. Following are the key areas under which books are categorized: Data science Pattern Recognition & Machine Learning Probability & Statistics Neural Networks & Deep Learning Optimization Data mining Mathematics Here is my post …
HBase Architecture Components for Beginners
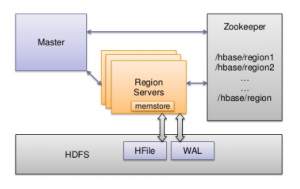
This blog represents high-level concepts on HBase architecture components. Following diagram represents the same: HBase Architecture Components – Key Building Blocks Following diagram represents the same: Pay attention to some of the following in relation to above diagram: HMaster: Responsible for coordinating the region servers including assigning regions on startup as well as recovery, and, monitoring region servers using Zookeeper Region Servers: Manages one or more regions Zookeeper: Zookeeper is used as a distributed coordination service for maintaining the server state of the cluster. Regions: Records in HBase tables are split horizontally based on the key range. Each of these splits can be called as Regions. A region contains all rows in …
When a Spark application starts on Spark Standalone Cluster?
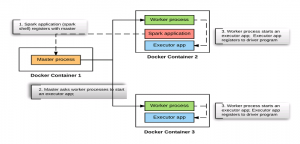
This article represents detailed view on what happens when a driver program (spark application) is started on one of the worker node when working with Spark standalone cluster. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Snapshot into what happens when Spark Standalone Cluster Starts? Snapshot into what happens when a spark application (Spark Shell) starts on one of the worker nodes? Snapshot into what happens when a spark application (Spark Shell) stops on the worker node? Snapshot into what happens when Spark Standalone Cluster Starts? In our …
Hello World with Apache Spark Standalone Cluster on Docker
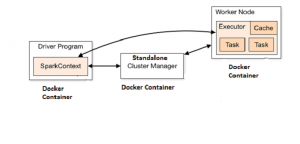
This article presents instructions and code samples for Docker enthusiasts to quickly get started with setting up Apache Spark standalone cluster with Docker containers. Thanks to the owner of this page for putting up the source code which has been used in this article. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Basic concepts on Apache Spark Cluster Steps to setup the Apache spark standalone cluster Code sample for Setting up Spark Code sample for Docker-compose to start the cluster Code sample for starting the Driver program using Spark …
9 Linux Foundation Projects for IOT, Cloud, Big Data
This article represents top Linux foundation projects in relation with IOT, Cloud and Big Data. With the convergence of these three technology domains, it becomes of utmost important to keep a track of news/announcements happening in these areas. The reference of all the projects could be found on this page. Following are the key linux foundation projects in relation with IOT, Cloud and Big Data. IOT (Internet of Things) AllSeen Alliance: A cross-industry consortium dedicated to enabling interoperability of billions of devices, services and apps that comprise the internet of things (IOT). Bookmark announcements and news for latest information. IoTivity: An open-source software framework enabling seamless device-to-device connectivity to address …
Top 5 Pages listing Big Data Conferences in 2016

This article represents top 5 pages listing global big data conferences coming up in 2016. Please feel free to comment/suggest if I missed to mention any other important pages. Also, sorry for the typos. Following are the top 5 pages: Global Big Data Conference KDNuggets List of Meetings/Conferences on Analytics, Big Data, Data Mining, Data Science Important Big Data events coming up in 2016 Big Data conference directory listing big data conferences happening around the world. O’Reilly List of conferences of on various topics including Big Data
Big Data – How Data is Retrieved and Written from/to HDFS?
This blog represents my notes on how data is read and written from/to HDFS. Please feel free to suggest if it is done otherwise. Following are steps using which clients retrieve data from HDFS: Clients ask Namenode for a file/data block Name-node returns data node information (ID) where the file/data blocks are located Client retrieves data directly from the data node. Following are steps in which data is written to HDFS: Clients ask Name-node that they want to write one or more data blocks pertaining to a file. Name-node returns data nodes information to which these data blocks needs to be written Clients write each data block to the data nodes suggested. The …
Top 5 Usecases of Solr to Power Your Web & Mobile Search
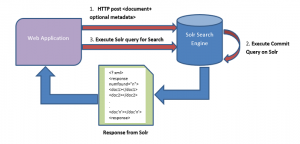
This article represents top 5 usecases for using Solr to power your web and mobile search. Note that in case of mobile search requirements, Solr exposes APIs that could be used to retrieve data from Solr index server and serve to mobile client. It also presents a classification of websites which are using Solr to fulfill their search requirements. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Top 5 Usecases for Solr Search Different Classes of Websites using Solr to Power Search Engines Top 5 Usecases for Solr Search Search Engine: Many …
Key Training Topics for Hadoop Developer

This article represents key topics that one would want to learn in order to become a Hadoop Developer. One may also check these topics against topics provider by the training vendor. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key areas tof focus for learning/training which are described later in this article: Java Essentials Hadoop Essentials Java Essentials As Hadoop is based on Java programming language, one would want to get expertise of at least intermediary level to do good with Hadoop development. Following are some of the key concepts that one would want to …
Dummies Notes on How Distributed Computing Works using Hadoop

This article intends to present dummies notes on how distributed computing works using Hadoop. As Hadoop is inspired by Google GFS/Map-Reduce/BigTable paper,I have tried and refer to GFS/Map-Reduce/BigTable in this article appropriately wherever possible. One must note that distributed computing paradigm has become mainstream given the advent of Big Data related large scale project implementation going on in several companies. Please feel free to shout if you find discrepancies with my understanding and help me correct the mistakes. Simply speaking, distributed computing refers to the computing paradigm in which processing happens on multiple different boxes consisting of data and, the result is, then, aggregated appropriately to display the final result. In traditional …
Document Search Architecture to Search Millions of Documents

This article represents different document search architectural models using which one could create a search architecture that could search through 100s of millions of documents in faster time (milliseconds) with most up-to-date and fresh results. If you are planning to create a document search infrastructure which could search millions of documents, and shows up results in less than a second time, go ahead and explore different models and adopt the one that suits your needs at this stage. Note that the models given below could scale to multiple data centers. In this blog, we shall try and examine different architecture models that could achieve the search timing of less than a …
Machine Learning – Top 16 Learning Resources on Statistics

This article represents some of the top learning resources (webpages, videos etc) on my frequent visit list. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key categories of webpages/videos that are expanded later in this article: Websites Quora Youtube Videos Coursera courses Khan Academy Top 16 Learning Resources on Statistics Folllowing is the list of URLs for these learning resources: Websites on Statistics Stattrek.com Elementary Statistics with R StatsDirect.com Usable Stats Quora.com Statistics Channel Probability & Statistics Statistics (Acacedmic Discipline) Bayesian Inference Youtube Videos Playlists on Statistics Brandon Foltz StatisticsFun JBStatistics Quantitative Specialists Coursera Courses …
Data Science – 175 Probability & Statistics Interview Questions

This article presents URL and short description of around 175 probability & statistics objective questions which could prove very useful and helpful for those who are planning to attend one or more data scientist interviews in time to come. These tests/quizzes were created when I was learning probability and statistics some time back and, found various concepts interesting enough to be converted into quizzes for my future references. As probability & statistics form key to data science, it may be worth spending some time on these tests and check your understanding. You may also use this for your future reference. These questions could also be used for checking your concepts …
Quick Cheat Sheet for Big Data Technologies
This article represents quick details on some of the key open-source technologies (tools & frameworks) associated with Big Data. The objective of this article is to present quick details on open-source tools & frameworks in a well-categorized manner using top-down approach where data engineering and data science aspects of Big Data is associated with relevant tools & framework. Most of these tools and frameworks could be found with commercial Hadoop distributions such as Cloudera, Hortonworks, MapR etc. Please feel free to comment/suggest if I missed to mention one or more important frameworks. Also, sorry for the typos. Following is the key classication of tools/frameworks that have been briefed later in …

I found it very helpful. However the differences are not too understandable for me