This blog represents my notes on how data is read and written from/to HDFS. Please feel free to suggest if it is done otherwise.
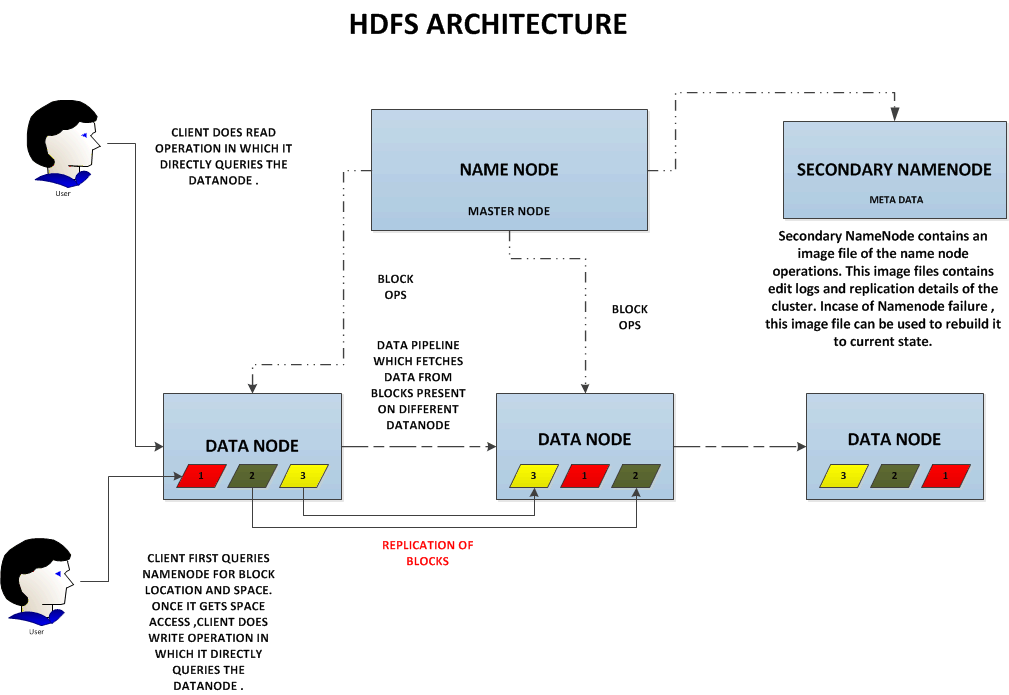
Following are steps using which clients retrieve data from HDFS:
- Clients ask Namenode for a file/data block
- Name-node returns data node information (ID) where the file/data blocks are located
- Client retrieves data directly from the data node.
Following are steps in which data is written to HDFS:
- Clients ask Name-node that they want to write one or more data blocks pertaining to a file.
- Name-node returns data nodes information to which these data blocks needs to be written
- Clients write each data block to the data nodes suggested.
- The data nodes then replicates the data block to other data nodes
- Informs Namenode about the write.
- Name-node commits EditLog
Following diagrams represents the data is read/written from/to HDFS.
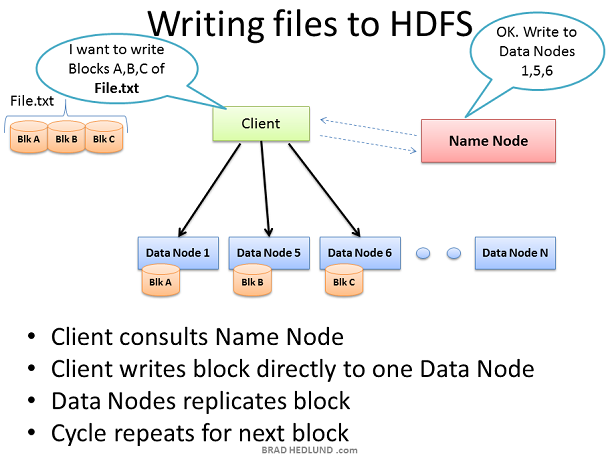
Following depicts how files are written to HDFS.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Latest posts by Ajitesh Kumar (see all)
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me