Category Archives: Python
14 Python Automl Frameworks Data Scientists Can Use
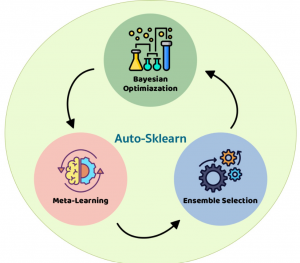
In this post, you will learn about Automated Machine Learning (AutoML) frameworks for Python that can use to train machine learning models. For data scientists, especially beginners, who are unfamiliar with Automl, it is a tool designed to make the process of generating machine learning models in an automated manner, user-friendly, and less time-consuming. The goal of Automl is not just about making it easier for machine learning (ML) developers but also democratizing access to model development. What is AutoML? AutoML refers to automating some or all steps of building machine learning models, including selection and configuration of training data, tuning the performance metric(s), selecting/constructing features, training multiple models, evaluating …
Python Scraper for GoogleNews, Twitter, Reddit & Arxiv

In this post, you will get the Python code for scraping latest and greatest news about any topics from Google News, Twitter, Reddit and Arxiv. This could prove to be very useful for data scientist, machine learning enthusiats to keep track of latest and greatest happening in the field of artificial intelligence. If you are doing some research work, these pieces of code would prove to be very handy to quickly access the information. The code in this post has been worked out in Google Colab notebook. First and foremost, import the necessary Python libraries such as the following for GoogleNews, Twitter and Arxiv. Python Code for mining GoogleNews Here …
Reddit Scraper Code using Python & Reddit API
In this post, you will get Python code sample using which you can search Reddit for specific subreddit posts including hot posts. Reddit API is used in the Python code. This code will be helpful if you quickly want to scrape Reddit for popular posts in the field of machine learning (subreddit – r/machinelearning), data science (subreddit – r/datascience), deep learning (subreddit – r/deeplearning) etc. There will be two steps to be followed to scrape Reddit for popular posts in any specific subreddits. Python code for authentication and authorization Python code for retrieving the popular posts Check the Reddit API documentation page to learn about Reddit APIs. Python code for …
Mining Twitter Data – Python Code Example
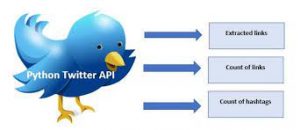
In this post, you will learn about how to get started with mining Twitter data. This will be very helpful if you would like to build machine learning models based on NLP techniques. The Python source code used in this post is worked out using Jupyter notebook. The following are key aspects of getting started with Python Twitter APIs. Set up Twitter dev app and Python Twitter package Establish connection with Twitter Twitter API example – location-based trends, user timeline, etc Search twitter by hashtags Setup Twitter Dev App & Python Twitter Package In this section, you will learn about the following two key aspects before you get started with …
Python Scraper Code to Search Arxiv Latest Papers
In this post, you will learn about Python source code related to search Arxiv for relevant and latest machine learning and data science research papers. If you are looking for a faster way to research on Arxiv papers without really going to the Arxiv website, you may want to get this piece of code in your kitty. You can further automate the Arxiv search to get notified based on some logic. Without further ado, let’s get started. Step 1: Install Python Arxiv Library As a first step, install the Python Arxiv library using the code such as below in your Jupyter notebook or Google colab instance: Step 2: Execute the …
Google News Search Python API Example
In this post, you will learn about how to use GoogleNews search Python library to get or retrieve or scrape news from Google News for last N number of days. This would be very helpful for someone wanting to track new work / projects in relation to machine learning, data science, deep learning or any field including sports, politics etc. Without further ado, lets jump in right away. You can log into Google colab and practise the code. Step 1: First and foremost, lets install GoogleNews python library. Step 2: Instantiate GoogleNews object. One can pass the language and period to instantiate the object. The parameter, period, represents the news …
Python – How to Create Dictionary using Pandas Series
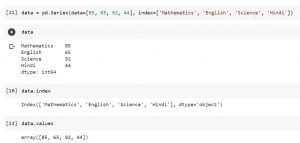
In this post, you will learn about one of the important Pandas fundamental data structure namely Series and how it can be used as a dictionary. It will be useful for beginner data scientist to understand the concept of Pandas Series object. A dictionary is a structure that maps arbitrary keys to a set of arbitrary values. Pandas Series is a one-dimensional array of indexed data. It can be created using a list or an array. Pandas Series can be thought of as a special case of Python dictionary. It is a structure which maps typed keys to a set of typed values. Here are the three different ways in …
Free Online Books – Machine Learning with Python

This post lists down free online books for machine learning with Python. These books covers topiccs related to machine learning, deep learning, and NLP. This post will be updated from time to time as I discover more books. Here are the titles of these books: Python data science handbook Building machine learning systems with Python Deep learning with Python Natural language processing with Python Think Bayes Scikit-learn tutorial – statistical learning for scientific data processing Python Data Science Handbook Covers topics such as some of the following: Introduction to Numpy Data manipulation with Pandas Visualization with Matplotlib Machine learning topics (Linear regression, SVM, random forest, principal component analysis, K-means clustering, Gaussian …
Gradient Boosting Regression Python Examples
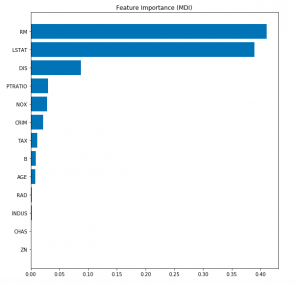
In this post, you will learn about the concepts of Gradient Boosting Regression with the help of Python Sklearn code example. Gradient Boosting algorithm is one of the key boosting machine learning algorithms apart from AdaBoost and XGBoost. What is Gradient Boosting Regression? Gradient Boosting algorithm is used to generate an ensemble model by combining the weak learners or weak predictive models. Gradient boosting algorithm can be used to train models for both regression and classification problem. Gradient Boosting Regression algorithm is used to fit the model which predicts the continuous value. Gradient boosting builds an additive mode by using multiple decision trees of fixed size as weak learners or …
Keras Multi-class Classification using IRIS Dataset
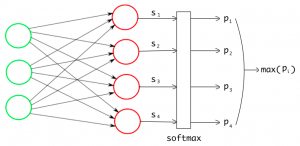
In this post, you will learn about how to train a neural network for multi-class classification using Python Keras libraries and Sklearn IRIS dataset. As a deep learning enthusiasts, it will be good to learn about how to use Keras for training a multi-class classification neural network. The following topics are covered in this post: Keras neural network concepts for training multi-class classification model Python Keras code for fitting neural network using IRIS dataset Keras Neural Network Concepts for training Multi-class Classification Model Training a neural network for multi-class classification using Keras will require the following seven steps to be taken: Loading Sklearn IRIS dataset Prepare the dataset for training and testing …
Python – How to Add Trend Line to Line Chart / Graph

In this plot, you will learn about how to add trend line to the line chart / line graph using Python Matplotlib.As a data scientist, it proves to be helpful to learn the concepts and related Python code which can be used to draw or add the trend line to the line charts as it helps understand the trend and make decisions. In this post, we will consider an example of IPL average batting scores of Virat Kohli, Chris Gayle, MS Dhoni and Rohit Sharma of last 10 years, and, assess the trend related to their overall performance using trend lines. Let’s say that main reason why we want to …
Python Sklearn – How to Generate Random Datasets
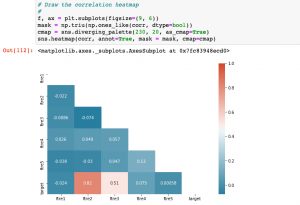
In this post, you will learn about some useful random datasets generators provided by Python Sklearn. There are many methods provided as part of Sklearn.datasets package. In this post, we will take the most common ones such as some of the following which could be used for creating data sets for doing proof-of-concepts solution for regression, classification and clustering machine learning algorithms. As data scientists, you must get familiar with these methods in order to quickly create the datasets for training models using different machine learning algorithms. Methods for generating datasets for Classification Methods for generating datasets for Regression Methods for Generating Datasets for Classification The following is the list of …
Adaptive Linear Neuron (Adaline) Python Example
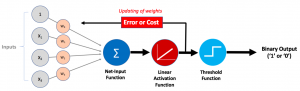
In this post, you will learn the concepts of Adaline (ADAptive LInear NEuron), a machine learning algorithm, along with Python example.As like Perceptron, it is important to understand the concepts of Adaline as it forms the foundation of learning neural networks. The concept of Perceptron and Adaline could found to be useful in understanding how gradient descent can be used to learn the weights which when combined with input signals is used to make predictions based on unit step function output. Here are the topics covered in this post in relation to Adaline algorithm and its Python implementation: What’s Adaline? Adaline Python implementation Model trained using Adaline implementation What’s Adaptive …
Python Implementations of Machine Learning Models
This post highlights some great pages where python implementations for different machine learning models can be found. If you are a data scientist who wants to get a fair idea of whats working underneath different machine learning algorithms, you may want to check out the Ml-from-scratch page. The top highlights of this repository are python implementations for the following: Supervised learning algorithms (linear regression, logistic regression, decision tree, random forest, XGBoost, Naive bayes, neural network etc) Unsupervised learning algorithms (K-means, GAN, Gaussian mixture models etc) Reinforcement learning algorithms (Deep Q Network) Dimensionality reduction techniques such as PCA Deep learning Examples that make use of above mentioned algorithms Here is an insight into …
Python – Extract Text from HTML using BeautifulSoup

In this post, you will learn about how to use Python BeautifulSoup and NLTK to extract words from HTML pages and perform text analysis such as frequency distribution. The example in this post is based on reading HTML pages directly from the website and performing text analysis. However, you could also download the web pages and then perform text analysis by loading pages from local storage. Python Code for Extracting Text from HTML Pages Here is the Python code for extracting text from HTML pages and perform text analysis. Pay attention to some of the following in the code given below: URLLib request is used to read the html page …
Python – Extract Text from PDF file using PDFMiner
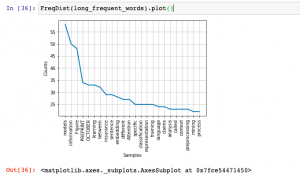
In this post, you will get a quick code sample on how to use PDFMiner, a Python library, to extract text from PDF files and perform text analysis. I will be posting several other posts in relation to how to use other Python libraries for extracting text from PDF files. In this post, the following topic will get covered: How to set up PDFMiner Python code for extracting text from PDF file using PDFMiner Setting up PDFMiner Here is how you would set up PDFMiner.six. You could execute the following command to get set up with PDFMiner while working in Jupyter notebook: Python Code for Extracting Text from PDF file …
I found it very helpful. However the differences are not too understandable for me