Category Archives: Machine Learning
Maximum Likelihood Estimation: Concepts, Examples
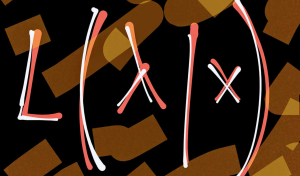
Maximum Likelihood Estimation (MLE) is a fundamental statistical method for estimating the parameters of a statistical model that make the observed data most probable. MLE is grounded in probability theory, providing a strong theoretical basis for parameter estimation. This is becoming more so important to learn fundamentals of MLE concepts as it is at the core of generative modeling (generative AI). Many models used in machine learning and statistics are based on MLE, including logistic regression, survival models, and various types of machine learning algorithms. MLE is particularly important for data scientists because it underpins many of the probabilistic machine learning models that are used today. These models, which are …
R-squared in Linear Regression Models: Concepts, Examples
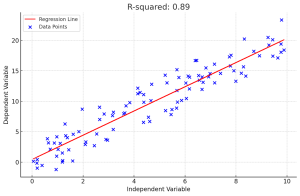
In linear regression, R-squared (R2) is a measure of how close the data points are to the fitted line. It is also known as the coefficient of determination. Understanding the concept of R-squared is crucial for data scientists as it helps in evaluating the goodness of fit in linear regression models, compare the explanatory power of different models on the same dataset and communicate the performance of their models to stakeholders. In this post, you will learn about the concept of R-Squared in relation to assessing the performance of multilinear regression machine learning model with the help of some real-world examples explained in a simple manner. Before doing a deep dive, …
Hierarchical Clustering: Concepts, Python Example
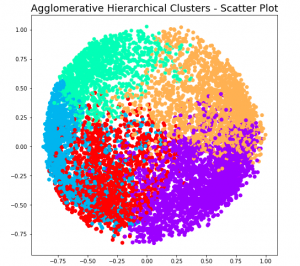
Hierarchical clustering a type of unsupervised machine learning algorithm that stands out for its unique approach to grouping data points. Unlike its counterparts, such as k-means, it doesn’t require the predetermined number of clusters. This feature alone makes it an invaluable method for exploratory data analysis, where the true nature of data is often hidden and waiting to be discovered. But the capabilities of hierarchical clustering go far beyond just flexibility. It builds a tree-like structure, a dendrogram, offering insights into the data’s relationships and similarities, which is more than just clustering—it’s about understanding the story your data wants to tell. In this blog, we’ll explore the key features that …
Minimum Description Length (MDL): Formula, Examples
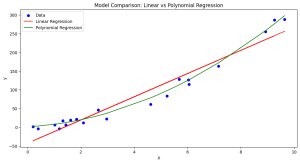
Learning the concepts of Minimum Description Length (MDL) is valuable for several reasons, especially for those involved in statistics, machine learning, data science, and related fields. One of the fundamental problems in statistics and data analysis is choosing the best model from a set of potential models. The challenge is to find a model that captures the essential features of the data without overfitting. This is where methods such as MDL, AIC, BIC, etc. comes to rescue. MDL offers a principled way to balance model complexity against the goodness of fit. This is crucial in many areas, such as machine learning and statistical modeling, where overfitting is a common problem. …
AIC & BIC for Selecting Regression Models: Formula, Examples
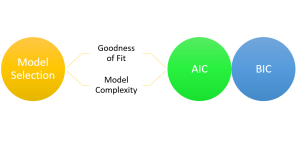
Are you grappling with the complexities of choosing the right regression model for your data? You are not alone. When working with regression models, selecting the most appropriate machine learning model is a critical step toward understanding the relationships between variables and making accurate predictions. With numerous regression models available, it becomes essential to employ robust criteria for model selection. This is where the two most widely used criteria come to the rescue. They are the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). In this blog, we will learn about the concepts of AIC, BIC and how they can be used to select the most appropriate machine …
Linear Regression Datasets: CSV, Excel

Linear regression is a fundamental machine learning algorithm that helps in understanding the relationship between independent and dependent variables. It is widely used in various fields for predicting numerical outcomes based on one or more input features. To practice and learn about linear regression, it is essential to have access to good quality datasets. In this blog, we have compiled a list of 17 datasets suitable for training linear regression models, available in CSV or easily convertible to CSV (Excel) format. I have also provided a sample Python code you can use to train using these datasets. List of Dataset for Training Linear Regression Models The following is a list …
Problems with Categorical Variables: Examples
Have you ever encountered unfamiliar words while learning a new language and didn’t know their meanings? Or tried to fit all your belongings into a suitcase, only to realize it’s too full? Or started reading a book series from the third book and felt lost? These scenarios in our daily lives surprisingly resemble some challenges we face with categorical variables in machine learning. Categorical variables, while essential in many datasets, bring with them a unique set of challenges. In this article, we’ll be discussing three major problems associated with categorical features: Let’s explore each with real-life examples and supporting Python code snippets. Incomplete Vocabulary The “Incomplete Vocabulary” problem arises when …
Insurance & Linear Regression Model Example
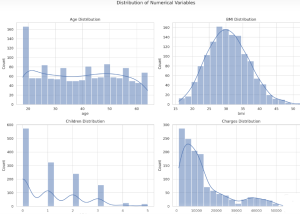
Ever wondered how insurance companies determine the premiums you pay for your health insurance? Predicting insurance premiums is more than just a numbers game—it’s a task that can impact millions of lives. In this blog, we’ll demystify this complex process by walking you through an end-to-end example of predicting health insurance premium charges by demonstrating with Python code example. Specifically, we’ll use a linear regression model to predict these charges based on various factors like age, BMI, and smoking status. Whether you’re a beginner in data science or a seasoned professional, this blog will offer valuable insights into building and evaluating regression models. What is Linear Regression? Linear Regression is …
Text Clustering Real-World Applications: Examples
How often have you wondered about the vast amounts of unstructured data around us and its untapped potential? How can businesses sift through thousands of customer reviews, documents, or feedback to derive actionable insights? What if there was a way to automatically group similar pieces of text, helping organizations quickly identify patterns and trends? Enter text clustering. A subset of text analytics, text clustering is an unsupervised machine learning task that divides a set of texts into clusters or groups. This ensures that texts in the same group are more similar to each other than to those in other groups. A powerful tool for deciphering insights from unstructured data, text …
Find Topics of Text Clustering: Python Examples
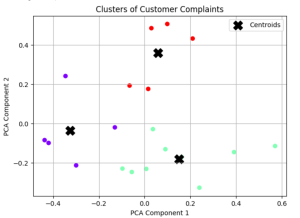
Have you ever clustered a collection of texts and wondered what predominant topics underlie each group? How can you pinpoint the essence of each cluster comprising of large volume of words? Is there a way to succinctly represent the core topic of each cluster using Python? Text clustering is a powerful technique in natural language processing (NLP) that groups documents into clusters based on their content. Once you’ve clustered your data, a natural follow-up question arises: “What are these clusters about?” In this article, we’ll discuss two different methods to find the dominant topics of text clusters using Python. Meanwhile, check out my post on text clustering – Text Clustering …
OpenAI Python API Example for NLP Tasks

Ever wondered how you can leverage the power of OpenAI’s GPT-3 and GPT-3.5 (from Jan 2024 onwards) directly in your Python application? Are you curious about generating human-like text with just a few lines of code? This blog post will walk you through an example Python code snippet that utilizes OpenAI’s Python API for different NLP tasks such as text generation. Check out my other post on how to use Langchain framework for text generation using OpenAI GPT models. OpenAI Python APIs The OpenAI Python API is an interface that allows you to interact with OpenAI’s language models, including their GPT-3 model. The following are different popular models that you …
Architecting a Generative AI Platform for GPT-based LLM Apps
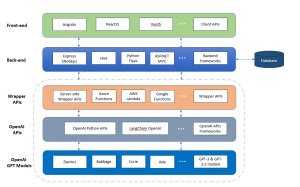
Have you ever wondered how to build a scalable Generative AI platform based on OpenAI GPT models that can serve different applications? Are you a data scientist, product manager, or software engineer looking to understand the intricacies of the architecture of such a scalable generative AI platform? This blog aims to demystify the architectural building blocks needed to create a robust GPT-based platform. By the end, you will have a clear roadmap for architecting, designing, and implementing your own GPT-based large language models (LLMs) applications platform. Generative AI Platform Architecture for GPT-based LLM Apps The following is the technology architecture of generative AI platform which can leverage OpenAI GPT based …
Microsoft’s Free Courses: Data Science, Machine Learning, AI

Are you keen on diving into the world of data science, machine learning, or artificial intelligence? Have you been searching for courses that not only teach the fundamentals but are also free and accessible? Look no further! Microsoft has put together three distinct courses that will cater to your interests and ignite your passion for learning. Data Science for Beginners This course offers an ideal starting point for those new to data science, focusing on the basics and guiding through practical exercises. The course would help you demystify the complex world of data, allowing you to make informed decisions in various fields such as business, healthcare, and more. Each lesson …
Text Clustering Python Examples: Steps, Algorithms
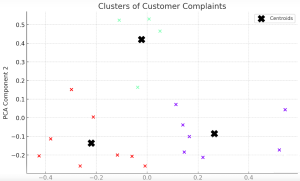
Text clustering has swiftly emerged as a cornerstone in data-driven decision-making across industries. But what exactly is text clustering, and how can it transform the way businesses operate? How does it convert unstructured text into actionable insights? What are the core steps involved in text clustering, and how are they interlinked? What algorithms are pivotal in implementing text clustering effectively? In this blog, we will unravel these questions, diving deep into the systematic steps of text clustering, its underlying algorithms, and real-world examples that bring this technique to life. Whether you’re a product manager seeking to leverage data analytics or a data scientist curious to learn key steps of text …
Topic Modeling LDA Python Example
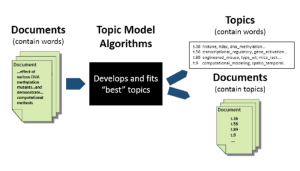
Are you overwhelmed by the endless streams of text data and looking for a way to unearth the hidden themes that lie within? Have you ever wondered how platforms like Google News manage to group similar articles together, or how businesses extract insights from vast volumes of customer reviews? The answer to these questions might be simpler than you think, and it’s rooted in the world of Topic Modeling. Introducing Latent Dirichlet Allocation (LDA) – a powerful algorithm that offers a solution to the puzzle of understanding large text corpora. LDA is not just a buzzword in the data science community; it’s a mathematical tool that has found applications in …
Encoder Only Transformer Models Quiz / Q&A

Are you intrigued by the revolutionary world of transformer architectures? Have you ever wondered how encoder-only transformer models like BERT, ELECTRA, or DeBERTa have reshaped the landscape of Natural Language Processing (NLP)? The rapid advancement of machine learning has led to the creation of numerous transformer architectures, each with unique features, applications, and underlying mechanics. Whether you’re a data scientist, machine learning engineer, generative AI enthusiast, or a student eager to deepen your understanding, this quiz offers an engaging and informative way to assess your knowledge and sharpen your skills. It would also help you prepare for your interviews on this topic. Encoder-only transformer models have become a cornerstone in …

I found it very helpful. However the differences are not too understandable for me