Tag Archives:
Retrieval Augmented Generation (RAG) & LLM: Examples
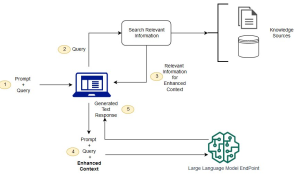
Last updated: 25th Jan, 2025 Have you ever wondered how to seamlessly integrate the vast knowledge of Large Language Models (LLMs) with the specificity of domain-specific knowledge stored in file storage, relational databases, graph databases, vector databases, etc? As the world of LLMs continues to evolve, the need for more sophisticated and contextually relevant responses from LLMs becomes paramount. Lack of contextual knowledge can result in LLM hallucination thereby producing inaccurate, unsafe, and factually incorrect responses. This is where question & context augmentation to prompts is used for contextually sensitive answer generation with LLMs, and, the retrieval-augmented generation method, comes into the picture. For data scientists and product managers keen …
Content-based Recommender System: Python Example

In this blog, we will learn about how to implement content-based recommender system using Python programming example. We will learn with the example of movie recommender system for recommending movies. Download the movies data from here to work with example given in this blog. The following is a list of key activities we would do to build a movie recommender system based on content-based recommendation technique. Data loading & preparation Text vectorization Cosine similarity computation Getting recommendations Data Loading & Preparation To start with, we import the data in csv format. Once data is imported, next step is analyse and prepare data before we apply modeling techniques. The dataset contains …
Self-Supervised Learning vs Transfer Learning: Examples
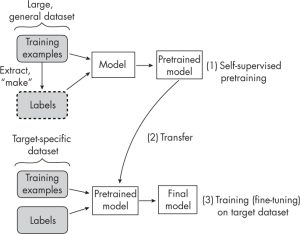
Last updated: 3rd March, 2024 Understanding the difference between self-supervised learning and transfer learning, along with their practical applications, is crucial for any data scientist looking to optimize model performance and efficiency. Self-supervised learning and transfer learning are two pivotal techniques in machine learning, each with its unique approach to leveraging data for model training. Transfer learning capitalizes on a model pre-trained on a broad dataset with diverse categories, to serve as a foundational model for a more specialized task. his method relies on labeled data, often requiring significant human effort to label. Self-supervised learning, in contrast, pre-trains models using unlabeled data, creatively generating its labels from the inherent structure …
Attention Mechanism in Transformers: Examples
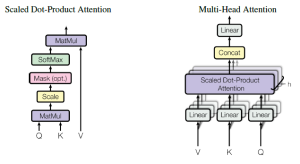
Last updated: 1st Feb, 2024 The attention mechanism allows the model to focus on relevant words or phrases when performing NLP tasks such as translating a sentence or answering a question. It is a critical component in transformers, a type of neural network architecture used in NLP tasks such as those related to LLMs. In this blog, we will delve into different aspects of the attention mechanism (also called an attention head), common approaches (such as self-attention, cross attention, etc.) to calculating and implementing attention, and learn the concepts with the help of real-world examples. You can get good details in this book: Generative Deep Learning by David Foster. You …
NLP Tokenization in Machine Learning: Python Examples

Last updated: 1st Feb, 2024 Tokenization is a fundamental step in Natural Language Processing (NLP) where text is broken down into smaller units called tokens. These tokens can be words, characters, or subwords, and this process is crucial for preparing text data for further analysis like parsing or text generation. Tokenization plays a crucial role in training machine learning models, particularly Large Language Models (LLMs) like GPT (Generative Pre-trained Transformer) series, BERT (Bidirectional Encoder Representations from Transformers), and others. Tokenization is often the first step in preparing text data for machine learning. LLMs use tokenization as an essential data preprocessing step. Advanced tokenization techniques (like those used in BERT) allow …
Large Language Models (LLMs): Types, Examples
Last updated: 31st Jan, 2024 Large language models (LLMs), being the key pillar of generative AI, have been gaining traction in the world of natural language processing (NLP) due to their ability to process massive amounts of text and generate accurate results related to predicting the next word in a sentence, given all the previous words. These different LLM models are trained on a large or broad corpus of text datasets, which contain hundreds of millions to billions of words. LLMs, as they are known, rely on complex algorithms including transformer architectures that shift through large datasets and recognize patterns at the word level. This data helps the LLMs better understand …
LLM Optimization for Inference – Techniques, Examples
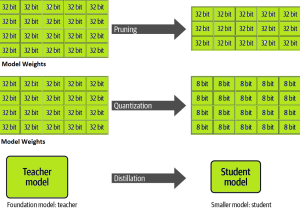
One of the common challenges faced with the deployment of large language models (LLMs) while achieving low-latency completions (inferences) is the size of the LLMs. The size of LLM throws challenges in terms of compute, storage, and memory requirements. And, the solution to this is to optimize the LLM deployment by taking advantage of model compression techniques that aim to reduce the size of the model. In this blog, we will look into three different optimization techniques namely pruning, quantization, and distillation along with their examples. These techniques help model load quickly while enabling reduced latency during LLM inference. They reduce the resource requirements for the compute, storage, and memory. …
Transfer Learning vs Fine Tuning LLMs: Differences
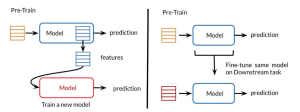
Last updated: 23rd Jan, 2024 Two NLP concepts that are fundamental to large language models (LLMs) are transfer learning and fine-tuning pre-trained LLMs. Rather, true fine-tuning can also be termed as full fine-tuning because transfer learning is also a form of fine-tuning. Despite their interconnected nature, they are distinct methodologies that serve unique purposes when training foundation LLMs to achieve different objectives. In this blog, we will explore the differences between transfer Learning and full fine-tuning, learning about their characteristics and how they come into play in real-world scenarios related to natural language understanding (NLU) and natural language generation (NLG) tasks with the help of examples. We will also learn …
Transformer Architecture in Deep Learning: Examples
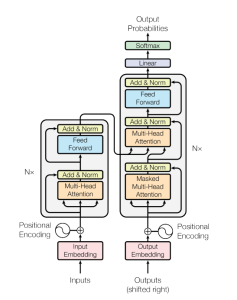
The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need. Transformer Block – Core Building Block of Transformer Model Architecture Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block. The core building block of the Transformer architecture consists of multi-head attention …
LLM Training & GPU Memory Requirements: Examples
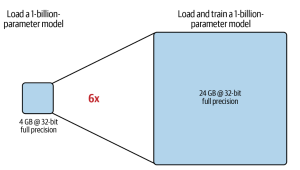
As data scientists and MLOps Engineers, you must have come across the challenges related to managing GPU requirements for training and deploying large language models (LLMs). In this blog, we will delve deep into the intricacies of GPU memory demands when dealing with LLMs. We’ll learn with the help of various examples to better understand how GPU memory impacts the performance and feasibility of training these LLMs. Whether you’re planning to train a foundation (pre-trained) model or fine-tuning an existing model, the insights are aimed to guide you through the crucial considerations of GPU memory allocation. Greater details can be found in this book: Generative AI on AWS. Understanding GPU …
Instruction Fine-tuning LLM Explained with Examples

A pre-trained or foundation model is further trained (or fine-tuned) with instructions datasets to help them learn about your specific data and perform humanlike tasks. These models are called instruction fine-tuning LLMs. In this blog, we will learn about the concepts and different examples of instruction fine-tuning models. You might want to check out this book to learn more: Generative AI on AWS. What are Instruction fine-tuning LLMs? Instruction fine-tuning LLMs, also called chat or instruct models, are created by training pre-trained models with different types of instructions. Instruction fine-tuning can be defined as a type of supervised machine learning that improves the foundation model by continuously comparing the model’s …
Distributed LLM Training & DDP, FSDP Patterns: Examples

Training large language models (LLMs) like GPT-4 requires the use of distributed computing patterns as there is a need to work with vast amounts of data while training with LLMs having multi-billion parameters vis-a-vis limited GPU support (NVIDIA A100 with 80 GB currently) for LLM training. In this blog, we will delve deep into some of the most important distributed LLM training patterns such as distributed data parallel (DDP) and Fully sharded data parallel (FSDP). The primary difference between these patterns is based on how the model is split or sharded across GPUs in the system. You might want to check out greater details in this book: Generative AI on …
Pre-trained Models Explained with Examples
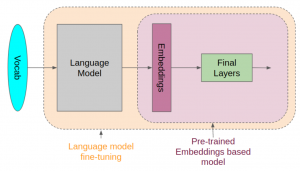
NLP has been around for decades, but it has recently seen an explosion in popularity due to pre-trained models (PTMs), also termed foundation models. This blog post will introduce you to different types of pre-trained (a.k.a. foundation) machine learning models and discuss their usage in real-world examples. Before we get into looking at different types of pre-trained models in NLP, let’s understand the concepts related to pre-trained models. What are Pre-trained Models? Pre-trained models (PTMs) are very large and complex neural network-based deep learning models, such as transformers, that consist of billions of parameters (a.k.a. weights) and have been trained on very large datasets to perform specific NLP tasks. The …
NLP Corpus Types (Text & Multimodal): Examples

At the heart of NLP lies a fundamental element: the corpus. A corpus, in NLP, is not just a collection of text documents or utterances; it’s at the core of large language models (LLMs) training. Each corpus type serves a unique purpose in terms of training language models that serve different purposes. Whether it’s a collection of written texts, transcriptions of spoken words, or an amalgamation of various media forms, each corpus type holds the key to leveraging different aspects of language to generate value. In this blog, we’re going to explore the significance of these different corpora types in NLP. From the traditional text corpora consisting of written content …
Demystifying Encoder Decoder Architecture & Neural Network
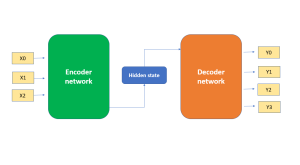
In the field of AI / machine learning, the encoder-decoder architecture is a widely-used framework for developing neural networks that can perform natural language processing (NLP) tasks such as language translation, text summarization, and question-answering systems, etc which require sequence-to-sequence modeling. This architecture involves a two-stage process where the input data is first encoded (using what is called an encoder) into a fixed-length numerical representation, which is then decoded (using a decoder) to produce an output that matches the desired format. In this blog, we will explore the inner workings of the encoder-decoder architecture, how it can be used to solve real-world problems, and some of the latest developments in …
Attention Mechanism Workflow & Transformer: Examples
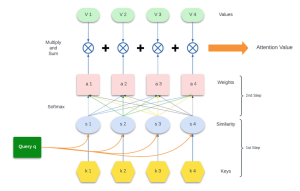
The attention mechanism workflow in the context of transformers in NLP, is a process that enables the model to dynamically focus on certain parts of the input data when performing a task such as machine translation, language understanding, text summarization, etc. Large language models, such as those based on the transformer architecture, rely on attention mechanisms to understand the context of words in a sentence and perform tasks as mentioned earlier. This mechanism selectively weights the significance of different parts of the input. This mechanism is essential for handling sequential data where the importance of each element may vary depending on the context. In this blog, we will learn about …

I found it very helpful. However the differences are not too understandable for me