Category Archives: Machine Learning
When to Use Which Clustering Algorithms?
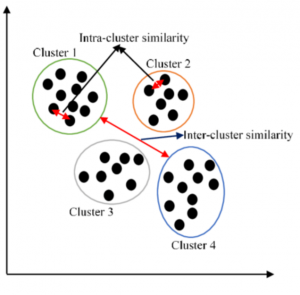
There are many clustering machine learning algorithms to choose from when you want to cluster data. But which one should you use in a particular situation? In this blog post, we will explore the different clustering algorithms and explain when each one is most appropriate. We will also provide examples so that you can see how these algorithms work in practice. What clustering is and why it’s useful Simply speaking, clustering is a technique used in machine learning to group data points together. The goal of clustering is to find natural groups, or clusters, in the data. Clustering algorithms are used to automatically find these groups. Clustering is useful because …
Steps for Evaluating & Validating Time-Series Models
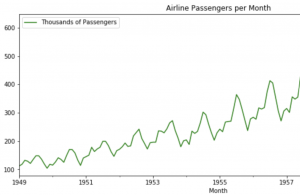
Time-series machine learning models are becoming increasingly popular due to the large volume of data that is now available. These models can be used to make predictions about future events, and they are often more accurate than traditional methods. However, it is important to properly evaluate (check accuracy by performing error analysis) and validate these models before you put them into production. In this blog post, we will discuss the different ways that you can evaluate and validate time series machine learning models. We will also provide some tips on how to improve your results. As data scientists, it is important to learn the techniques related to evaluating time-series models. …
Machine Learning with Alteryx: Examples
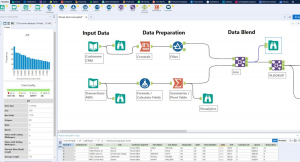
Alteryx is a self-service data analytics software platform that enables users to easily prep, blend, and analyze data all in one place. It is a powerful tool that can be used in a variety of machine learning scenarios. It can be used to clean and prepare data, and develop, evaluate and deploy machine learning (ML) models. It offers a variety of features and tools that can be used to preprocess data, choose algorithms, train models, and evaluate results. In this blog post, we will discuss some of the ways that Alteryx can be used in machine learning. We will also provide examples of how to use Alteryx in machine learning scenarios. …
Hate Speech Detection Using Machine Learning

Hate speech is a big problem on the internet. It can be found on social media, in comment sections, and even in online forums. Detecting hate speech is important because it can have harmful effects on society. In this blog post, we will discuss the latest techniques for detecting hate speech using machine learning algorithms. We will also provide examples of how these algorithms work. What is hate speech? Hate speech can be defined as any speech that targets a group of people based on their race, religion, ethnicity, national origin, sexual orientation, or gender identity. Hate speech is often used to spread hate and bigotry. It can also be …
Machine Learning with Graphs: Free online course(Stanford)
Are you interested in learning the concepts of machine learning with Graphs? Stanford University is offering a free online course in machine learning titled Machine Learning with Graphs (CS224W). The lecture videos will be available on Canvas for all the enrolled Stanford students. The lecture slides and assignments will be posted online as the course progresses. This class will be offered next in Fall 2022. After completing this course, you will be able to apply machine learning methods to a variety of real-world problems. The course titled Machine learning with Graphs, will teach you how to apply machine learning methods to graphs and networks. Complex data can be represented as …
Differences Between MLOps, ModelOps, AIOps, DataOps
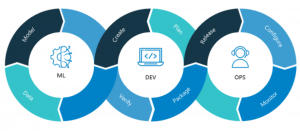
In this blog post, we will talk about MLOps, AIOps, ModelOps and Dataops and difference between these terms. MLOps stands for Machine Learning Operations, AIOps stands for Artificial Intelligence-Operations (AI for IT operations), DataOps stands for Data operations and ModelOps stands for model operations. As data analytics stakeholders, it is important to understand the differences between MLOps, AIOps, Dataops, and ModelOps. For setting up AI/ML practice, it is important to plan to set up teams and practices around AIOps, MLOps/ModelOps and DataOps. What is MLOps? MLOps (or ML Operations) refers to the process of managing your ML workflows. It’s a subset of ModelOps that focuses on operationalizing ML models that …
Business Analytics Team Structure: Roles/ Responsibilities
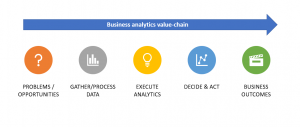
Business analytics is a business function that has been around for years, but it’s only recently gained traction as one of the most important business functions. Organizations are now realizing how business analytics can help them increase revenue and improve business operations. But before you bring on a business analytics team, you need to determine if your company needs full-time or part-time team members or both. It might seem logical to hire full-time staff members just because they’re in demand, but this isn’t always necessary. If your business operates without any external data sets and doesn’t have complex reporting and advanced analytics needs then it may be more cost-effective to …
Linear Regression Interview Questions for Data Scientists
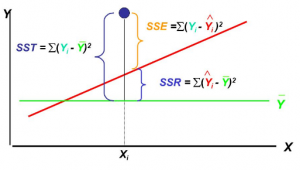
This page lists down 40 regression (linear/univariate, multiple/multilinear/multivariate) interview questions (in form of objective questions) which may prove to be helpful for Data Scientists / Machine Learning enthusiasts. Those appearing for interviews for machine learning/data scientist freshers/intern/beginners positions would also find these questions very helpful and handy enough to quickly brush up / check your knowledge and prepare accordingly. Practice Tests on Regression Analysis These interview questions are split into four different practice tests with questions and answers which can be found on following page: Linear, Multiple regression interview questions and answers – Set 1 Linear, Multiple regression interview questions and answers – Set 2 Linear, Multiple regression interview questions …
Different Success / Evaluation Metrics for AI / ML Products

In this post, you will learn about some of the common success metrics that can be used for measuring the success of AI / ML (machine learning) / DS (data science) initiatives / projects / products. If you are one of the AI / ML stakeholders including product managers, you would want to get hold of these metrics in order to apply right metrics in right business use cases. Business leaders do want to know and maximise the return on investments (ROI) from AI / ML investments. Here is the list of success metrics for AI / DS / ML initiatives: Business value metrics / key performance indicators (KPIs): Business …
Warehouse Management & Machine Learning Use Cases

Warehouses are a vital part of the supply chain. Not only do they store products, but warehouses also play a role in shipping and receiving goods. As warehouse operations become more complex, it’s important to use technology to help manage them. Warehouses need to be able to efficiently manage the flow of goods in and out while still making room for new deliveries. Increasingly warehouses are turning to machine learning algorithms as a way to improve warehouse efficiency, reduce costs, and increase warehouse productivity. In this blog post, we will explore different machine learning use cases which can be deployed by warehouse managers to create a positive business impact. Machine …
E-commerce Machine Learning Use Cases: Examples

In e-commerce, machine learning can be used to improve a number of decisions thereby resulting in creating a positive business impact. Not only does it help e-commerce organizations increase conversion rates and find the best deals for their customers, but it also helps them understand the customer better. This blog post will look at various different use cases where AI/machine learning and deep learning have been used in eCommerce. What are some key machine learning use cases in eCommerce? Here are some key areas in eCommerce where AI/machine learning can be leveraged: Product recommendation: One of the key use cases where machine learning has been used is to provide product …
Cybersecurity Machine Learning Use Cases: Examples

Cybersecurity professionals are increasingly finding cybersecurity machine learning use cases in their work. The reason for this is that cybersecurity has become more complicated and the scale of cybersecurity threats is growing exponentially. Machine learning can help to combat these cybersecurity threats by providing security teams with real-time alerts, but there are many cybersecurity machine learning use cases beyond just cybersecurity. Artificial intelligence (AI) technologies, in particular, machine learning models such as logistic regression, SVM and random forest, etc., and deep neural networks models such as CNN, LSTM, etc., have been widely used to fight against cyberattacks. In this blog post, we will look into how machine learning is being …
Elbow Method vs Silhouette Score – Which is Better?
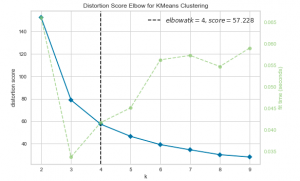
In K-means clustering, elbow method and silhouette analysis or score techniques are used to find the number of clusters in a dataset. The elbow method is used to find the “elbow” point, where adding additional data samples does not change cluster membership much. Silhouette score determines whether there are large gaps between each sample and all other samples within the same cluster or across different clusters. In this post, you will learn about these two different methods to use for finding optimal number of clusters in K-means clustering. Selecting optimal number of clusters is key to applying clustering algorithm to the dataset. As a data scientist, knowing these two techniques to find …
Different types of Machine Learning: Models / Algorithms
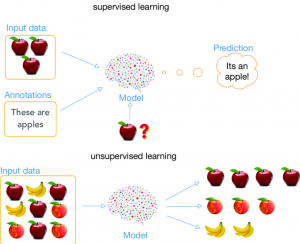
Machine learning is a type of machine intelligence that enables computers to learn and improve without being explicitly programmed. It’s based on the idea that we can build systems which allow our data to do the talking, by finding patterns in vast quantities of information. These machine learning algorithms require different types of machine-learning models trained using different algorithms, depending on what problem they are trying to solve or how accurate an answer needs to be. In this blog post, we will discuss the following four different types of machine learning models / algorithms: Supervised learning Unsupervised learning Semi-supervised learning Reinforcement learning What is supervised learning? Supervised learning is defined …
Free AI / Machine Learning Courses at Alison.com
Are you interested in learning about AI / machine learning / data sicence and looking for free online courses? As per MANUELA M. VELOSO, Herbert A. Simon University Professor at CMU,Machine Learning (ML) is a fascinating field of Artificial Intelligence (AI) research and practice where we investigate how computer agents can improve their perception, cognition, and action with experience. Machine Learning is about machines improving from data, knowledge, experience, and interaction. Machine Learning utilizes a variety of techniques to intelligently handle large and complex amounts of information build upon foundations in many disciplines, including statistics, knowledge representation, planning and control, databases, causal inference, computer systems, machine vision, and natural language …
Google Cloud Automl: Business Application Examples

Google cloud platform (GCP) automl services are a set of google cloud platform products with a focus on machine learning and automation. They help you to automate several tasks related to machine learning. In this blog post, we’ll talk about google cloud automl services and some common business problems that can be solved using these GCP automl services. What are some popular Google Cloud Automl services? Google cloud automl services include some of the following: Google Cloud Vision can be used to perform tasks related to image recognition like face detection, OCR (optical character recognition), landmark detection, etc. Google’s cloud vision can detect emotions, understand text, and more. The service …
I found it very helpful. However the differences are not too understandable for me