Author Archives: Ajitesh Kumar
When not to use F-Statistics for Multi-linear Regression
In this post, you will learn about the scenario in which you may NOT want to use F-Statistics for doing the hypothesis testing on whether there is a relationship between response and predictor variables in the multilinear regression model. Multilinear regression is a machine learning / statistical learning method which is used to predict the quantitative response variable and also understand/infer the relationship between the response and multiple predictor variables. We will look into the following topics: Background When not to use F-Statistics for Multilinear Regression Model Background F-statistics is used in hypothesis testing for determining whether there is a relationship between response and predictor variables in multilinear regression models. Let’s consider …
Machine Learning – Cloud-native Model Deployments
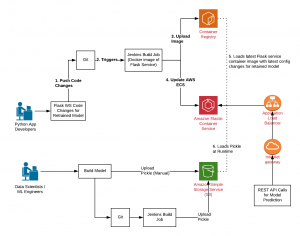
In this post, we are going to learn about the cloud-native machine learning model deployments. Cloud-native Deployments First and foremost, let’s understand the meaning of cloud-native deployments? If we are building an application or a service and we can deploy this application or the service on any cloud platform without much ado, it could be said as cloud-native deployment. And the way it is made possible is through the container technologies such as Dockers. What basically is required to be done is to wrap the applications or the services within the containers and move the containers images onto the cloud services such as AWS ECS, AWS EKS or Google Kubernetes …
What, When & Why of Regularization in Machine Learning?
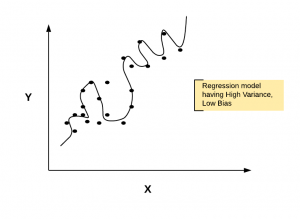
In this post, we will try and understand some of the following in relation to regularizing the regression machine learning models to achieve higher accuracy and stable models: Background What is regularization? Why & when does one need to adopt/apply the regularization technique? Background At times, when one is building a multi-linear regression model, one uses the least squares method for estimating the coefficients of determination or parameters for features. As a result, some of the following happens: Often, the regression model fails to generalize on unseen data. This could happen when the model tries to accommodate for all kind of changes in the data including those belonging to both …
Unit Tests & Data Coverage for Machine Learning Models

This post represents thoughts on what would it look like planning unit tests for machine learning models. The idea is to perform automated testing of ML models as part of regular builds to check for regression related errors in terms of whether the predictions made by certain set of input data vectors does not match with expected outcomes. This brings up some of the following topics for discussion: Why unit testing for machine learning models? What would unit tests for machine learning models mean? Data coverage or code coverage? Why unit testing for Machine Learning models? Once a model is built, the challenge is to monitor the performance metrics of the models …
Machine Learning Cheat sheet (Stanford)
Here is a great set of cheat sheet on some of the following topics: Supervised learning Unsupervised learning Deep learning Probability and statistics Linear algebra Tips and tricks including performance metrics https://stanford.edu/~shervine/teaching/cs-229/ Hope you liked the cheat sheets on different topics of machine learning and data science.
Machine Learning Models used in Facebook
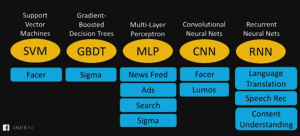
This post quickly represents machine learning projects and related machine learning models. The above diagram represents the usage of the following learning algorithms: Support Vector Machines (SVM) Gradient-boosted decision trees Multi-layer Perceptron (MLP): Used for ranking and personalizing news feeds, ads, search etc. Convolutional neural networks (CNN): Recurrent neural networks (RNN): Used for language translation, speech recognition, content understanding References
13 Programming Languages used for Machine Learning

In this post, you will learn about different programming languages which can be used to create (train) machine learning models to solve supervised and unsupervised learning problems. Here are the top 13 programming languages used for machine learning: R Language: R is one of the most popular programming language and environment for statistical computing and graphics. Python: There are some of the following Python libraries which makes it easy to create machine learning/deep learning models: Scikit-learn library (Classical machine learning models): Packages such as NumPy, SciPy, Pandas are very useful and helpful in creating supervised and unsupervised learning models. Deep learning models using python libraries provided by Tensorflow, PyTorch, Theanos, CNTK, …
Top 5 Machine Learning Introduction Slides for Beginners
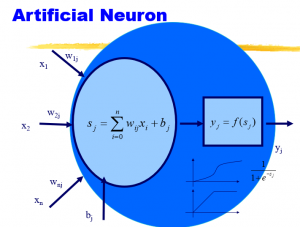
In this post, you will get to know a list of introduction slides (ppt) for machine learning. These slides could help you understand different types of machine learning algorithms with detailed examples. One or more slides from the following list could be used for making presentations on machine learning. If you are looking out for topics to be included in the machine learning course for your internal training purpose in your organization, the details presented below might turn out to be very helpful. If you are starting on learning data science, these could be good slides. Machine Learning Overview Machine Learning: An Overview: The slides present introduction to machine learning …
Andrew NG Machine Learning Coursera Videos
In this post, you will get to know the list of Andrew NG Machine Learning Coursera Videos. Here is the information: Youtube playlist of machine learning videos which are same as that of Andrew NG machine learning course on Coursera. One could use Internet Download Manager (IDM) to download these videos. Use Coursera-dl script found on Github to download the machine learning course. The script makes it easier to batch download lecture resources (e.g., videos, ppt, etc) for Coursera classes. Given one or more class names and account credentials, it obtains week and class names from the lectures page, and then downloads the related materials into appropriately named files and directories. Use AcademicTorrents website …
MIT OCW Machine Learning Courses Information

In this post, you get the information related to MIT OCW machine learning course from MIT OpencourseWare (OCW). They use Matlab as the primary programming environment. The documentation for Matlab could be found on this page, Matlab Documentation. The course is provided by Electrical Engineering and Computer Science department. Other related courses which could be useful for data scientist / machine learning engineers are some of the following: Introduction to probability (Video lectures, Lecture notes) Introduction to computational thinking and data science (Video lectures, Lecture notes) Lecture Notes – Machine Learning Course Lecture notes could be found on the following topics: Introduction, linear classification, perceptron update rule (PDF) Perceptron convergence, generalization (PDF) …
Machine Learning – Insurance Applications Use Cases
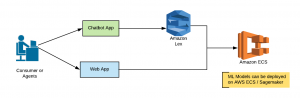
In this post, you will learn about some of the following insurance applications use cases where machine learning or AI-powered solution can be applied: Insurance advice to consumers and agents Claims processing Fraud protection Risk management AI-powered Insurance Advice to Consumers & Agents Insurance Advice to Consumers: Machine learning models could be trained to recommend the tailor made products based on the learning of the consumer profiles and related attributes such as queries etc from the past data. Such models could be integrated with Chatbots (Google Dialog flow, Amazon Lex etc) applications to create intelligent digital agents (Bots/apps) which could understand the intent of the user, collect appropriate data from the user (using prompts) …
AWS reInvent – Top 7 New Machine Learning Services
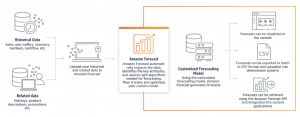
In this post, you will learn about some great new and updated machine learning services which have been launched at AWS re:Invent Conference Nov 2018. My personal favorite is Amazon Textract. Amazon Personalize Amazon Forecast Amazon Textract Amazon DeepRacer Amazon Elastic inference AWS Inferentia Updated Amazon Sagemaker Amazon Personalize for Personalized Recommendations Amazon Personalize is a managed machine learning service by Amazon with the primary goal to democratize recommendation system benefitting smaller and larger companies to quickly get up and running with the recommendation system thereby creating the great user experience. Here is the link to Amazon Personalize Developer Guide. The following are some of the highlights: Helps personalize the user experience using some of …
Solution – Macbook Air Stuck at Progress Bar Loading

In this post, you will learn about the solution related to Mac Air Stuck at Progress Bar Loading. The reason I am doing this post is that my Mac Air had been showing the same behavior for the last several months and I was able to finally fix it. I am hoping that the solution does help someone. Anyways, in the whole process, I started my Mac Air several times in voice-over mode and became expert at it. Commands/Solutions which didn’t work I contacted Apple customer service two times and they said that it looks to be a software problem after I tried all the steps they suggested. I was asked to …
Guidelines for Creating an Ethical AI Framework
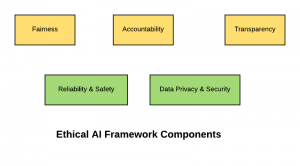
In this post, you will learn about how to create an Ethical AI Framework which could be used in your organization. In case, you are looking for Ethical AI RAG Matrix created with Excel, please drop me a message. The following are key aspects of ethical AI which should be considered for creating the framework: Fairness Accountability Transparency Reliability & Safety Data privacy and security Fairness AI/ML-powered solutions should be designed, developed and used in respect of fundamental human rights and in accordance with the fairness principle. The model design considerations should include the impact on not only the individuals but also the collective impact on groups and on society at large. The following represents some …
GitFlow Workflow Best Practices & Quiz Questions
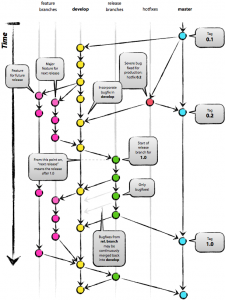
In this post, you will learn about some of the best practices in relation to managing your development and production releases using GitFlow Workflow. There will be a master branch which is called as an official repository. Forking a develop branch of the master: To start with, we will fork off another branch of the master which we may call as “develop”. This branch will act as an integration branch for features branches. NOTE: feature in features branches does not represent the features in machine learning. “Develop” branch will act as a parent to the feature branches. This means that developers would fork from “develop” branch and their changes are merged back into “develop” branch. In real-world scenarios, …
Javascript Security Vulnerabilities Examples (DarwinBox)
In this post, you will learn quick tips on security vulnerabilities related to Javascript based on analysis of how Javascript assets are managed in DarwinBox, and how to fix those security vulnerabilities. Security Vulnerabilities found with Javascript Assets While assessing the Javascript assets of DarwinBox, the following was found: Coding: Javascript code could be easily read and understood. There is a need to minimize and uglify the code. Method naming: The name of methods leak the implementation details and the underlying technology used. This could be used by hackers for planning attacks. For example, the method such as “doElasticSearch”. This represents that ElasticSearch is used for the search. File naming: The name of files represented …

I found it very helpful. However the differences are not too understandable for me