In this post, you will learn about some of the bias mitigation strategies which could be applied in ML Model Development lifecycle (MDLC) to achieve discrimination-aware machine learning models. The primary objective is to achieve a higher accuracy model while ensuring that the models are lesser discriminant in relation to sensitive/protected attributes. In simple words, the output of the classifier should not correlate with protected or sensitive attributes. Building such ML models becomes the multi-objective optimization problem. The quality of the classifier is measured by its accuracy and the discrimination it makes on the basis of sensitive attributes; the more accurate, the better, and the less discriminant (based on sensitive attributes), the better. The following are some of the bias mitigation strategies:
- Pre-processing algorithms
- In-processing algorithms
- Post-processing algorithms
Here is a diagram representing the bias mitigation strategies for machine learning models:
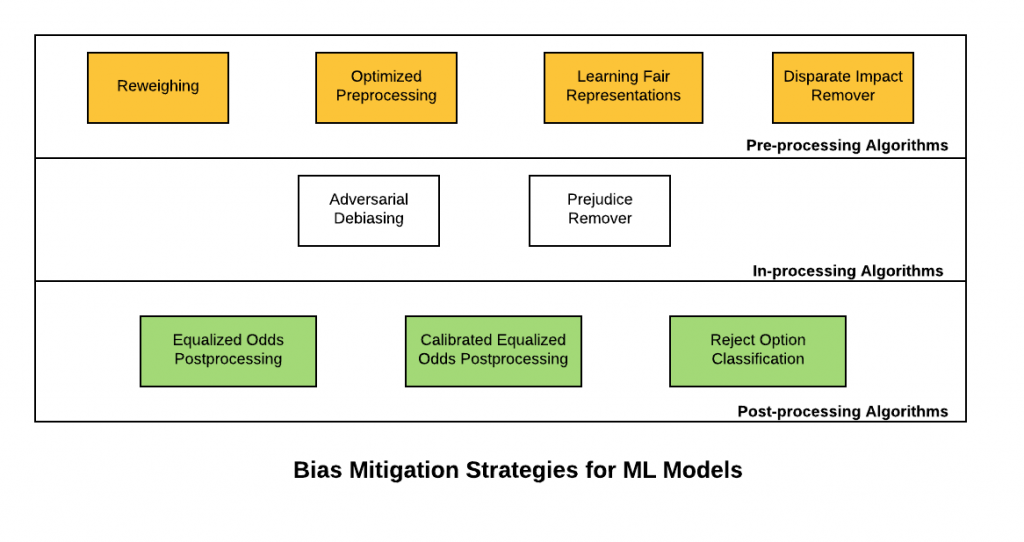
Pre-processing Algorithms
Pre-processing algorithms are used to mitigate bias prevalent in the training data. The idea is to apply one of the following technique for preprocessing the training data set and then, apply classification algorithms for learning an appropriate classifier.
- Reweighing: Reweighing is a data preprocessing technique which recommends generating weights for the training examples in each (group, label) combination differently to ensure fairness before classification. The idea is to apply appropriate weights to different tuples in the training dataset to make the training dataset discrimination free with respect to the sensitive attributes. Instead of reweighing, one could also apply techniques (non-discrimination constraints) such as suppression (remove sensitive attributes) or massaging the dataset – modify the labels (change the labels appropriately to remove discrimination from the training data). However, the reweighing technique is more effective than the other two mentioned earlier.
- Optimized preprocessing: The idea is to learn a probabilistic transformation that edits the features and labels in the data with group fairness, individual distortion, and data fidelity constraints and objectives.
- Learning fair representations: The idea is to find a latent representation that encodes the data well while obfuscating information about protected attributes.
- Disparate impact remover: Feature values are appropriately edited to increase group fairness while preserving rank-ordering within groups.
In-processing Algorithms
- Adversarial Debiasing: A classifier model is learned to maximize prediction accuracy and simultaneously reduce an adversary’s ability to determine the protected attribute from the predictions. This approach leads to a fair classifier as the predictions cannot carry any group discrimination information that the adversary can exploit.
- Prejudice remover: The idea is to add a discrimination-aware regularization term to the learning objective.
Post-processing Algorithms
- Equalized odds postprocessing: The algorithm solves a linear program to find probabilities with which to change output labels to optimize equalized odds.
- Calibrated equalized odds postprocessing: The algorithm optimizes over calibrated classifier score outputs to find probabilities with which to change output labels with an equalized odds objective.
- Reject option classification: The idea is to give favorable outcomes to unprivileged groups and unfavorable outcomes to privileged groups in a confidence band around the decision boundary with the highest uncertainty.
References
Summary
In this post, you learned about bias mitigation strategies to build higher performing models while making sure that the models are lesser discriminant. The techniques presented in this post will be updated at regular intervals based on ongoing research.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me