Tag Archives: machine learning
Predictive vs Prescriptive Analytics Difference
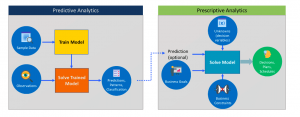
In this post, you will quickly learn about the difference between predictive analytics and prescriptive analytics. As data analytics stakeholders, one must get a good understanding of these concepts in order to decide when to apply predictive and when to make use of prescriptive analytics in analytics solutions / applications. Without further ado, let’s get straight to the diagram. In the above diagram, you could observe / learn the following: Predictive analytics: In predictive analytics, the model is trained using historical / past data based on supervised, unsupervised, reinforcement learning algorithms. Once trained, the new data / observation is input to the trained model. The output of the model is prediction in form …
Top 10 Analytics Strategies for Great Data Products
In this post, you will learn about the top 10 data analytics strategies which will help you create successful data products. These strategies will be helpful in case you are setting up a data analytics practice or center of excellence (COE). As an AI / Machine Learning / Data Science stakeholders, it will be important to understand these strategies in order to deliver analytics solution which creates business value having positive business impact. Here are the top 10 data analytics strategies: Identify top 2-3 business problems Identify related business / engineering organizations Create measurement plan by identifying right KPIs Identify analytics deliverables such as analytics reports, predictions etc Gather data …
Keras CNN Image Classification Example
In this post, you will learn about how to train a Keras Convolution Neural Network (CNN) for image classification. Before going ahead and looking at the Python / Keras code examples and related concepts, you may want to check my post on Convolution Neural Network – Simply Explained in order to get a good understanding of CNN concepts. Keras CNN Image Classification Code Example First and foremost, we will need to get the image data for training the model. In this post, Keras CNN used for image classification uses the Kaggle Fashion MNIST dataset. Fashion-MNIST is a dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a …
Data Quality Challenges for Machine Learning Models

In this post, you will learn about some of the key data quality challenges which need to be dealt with in a consistent and sustained manner to ensure high quality machine learning models. Note that high quality models can be termed as models which generalizes better (lower true error with predictions) with unseen data or data derived from larger population. As a data science architect or quality assurance (QA) professional dealing with quality of machine learning models, you must learn some of these challenges and plan appropriate development processes to deal with these challenges. Here are some of the key data quality challenges which need to be tackled appropriately in …
Python Keras – Learning Curve for Classification Model
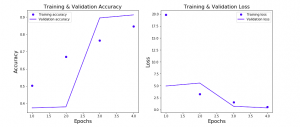
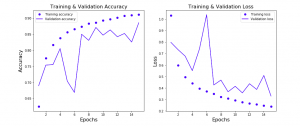
In this post, you will learn about how to train an optimal neural network using Learning Curves and Python Keras. As a data scientist, it is good to understand the concepts of learning curve vis-a-vis neural network classification model to select the most optimal configuration of neural network for training high-performance neural network. In this post, the following topics have been covered: Concepts related to training a classification model using a neural network Python Keras code for creating the most optimal neural network using a learning curve Training a Classification Neural Network Model using Keras Here are some of the key aspects of training a neural network classification model using Keras: …
Free MIT Course on Machine Learning for Healthcare
In this post, you will get a quick overview on free MIT course on machine learning for healthcare. This is going to be really helpful for machine learning / data science enthusiasts as building machine learning solutions to serve healthcare requirements comes with its own set of risks. It will be good to learn about different machine learning techniques, applications related disease progression modeling, cardiac imaging, pathology etc, risks and risk mitigation techniques. Here is the link to the course – Machine Learning for Healthcare Here are the links to some of the important course content: Video lectures Lecture notes (PDF) The entire course material can be downloaded from this page – …
Keras Multi-class Classification using IRIS Dataset
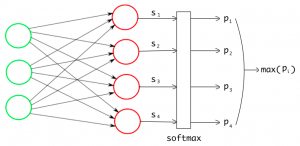
In this post, you will learn about how to train a neural network for multi-class classification using Python Keras libraries and Sklearn IRIS dataset. As a deep learning enthusiasts, it will be good to learn about how to use Keras for training a multi-class classification neural network. The following topics are covered in this post: Keras neural network concepts for training multi-class classification model Python Keras code for fitting neural network using IRIS dataset Keras Neural Network Concepts for training Multi-class Classification Model Training a neural network for multi-class classification using Keras will require the following seven steps to be taken: Loading Sklearn IRIS dataset Prepare the dataset for training and testing …
How to Setup / Install MLFlow & Get Started
In this post, you will learn about how to setup / install MLFlow right from your Jupyter Notebook and get started tracking your machine learning projects. This would prove to be very helpful if you are running an enterprise-wide AI practice where you have a bunch of data scientists working on different ML projects. Mlflow will help you track the score of different experiments related to different ML projects. Install MLFlow using Jupyter Notebook In order to install / set up MLFlow and do a quick POC, you could get started right from within your Jupyter notebook. Here are the commands to get set up. Mlflow could be installed with …
Top Tutorials – Neural Network Back Propagation Algorithm
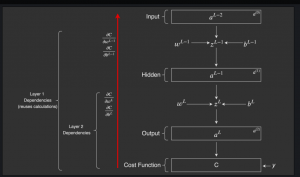
Here are the top web pages /videos for learning back propagation algorithm used to compute the gradients in neural network. I will update this page with more tutorials as I do further deep dive on back propagation algorithm. For beginners or expert level data scientists / machine learning enthusiasts, these tutorials will prove to be very helpful. Before going ahead and understanding back propagation algorithm from different pages, lets quickly understand the key components of neural network algorithm: Feed forward algorithm: Feed forward algorithm represents the aspect of how input signals travel through different neurons present in different layers in form of weighted sums and activations, and, result in output / …
Product Manager – Machine Learning Interview Questions

In this post, you will learn about some of the interview questions which can be asked in the AI / machine learning based product manager / business analyst job. Some of the questions listed in this post can also prove to be useful for the interview for the job position of director or vice president, product management. The interview questions can be categorized based on some of the following topics: Machine learning high level concepts Identifying a problem as machine learning problems Identifying business metrics vs value generation Feature engineering Working with data science team in model development lifecycle Monitoring model performance Model performance metrics presentation to key stakeholders Setting up …
Python Sklearn – How to Generate Random Datasets
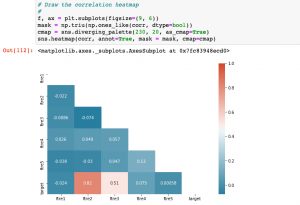
In this post, you will learn about some useful random datasets generators provided by Python Sklearn. There are many methods provided as part of Sklearn.datasets package. In this post, we will take the most common ones such as some of the following which could be used for creating data sets for doing proof-of-concepts solution for regression, classification and clustering machine learning algorithms. As data scientists, you must get familiar with these methods in order to quickly create the datasets for training models using different machine learning algorithms. Methods for generating datasets for Classification Methods for generating datasets for Regression Methods for Generating Datasets for Classification The following is the list of …
Neural Networks and Mathematical Models Examples
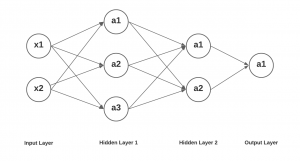
In this post, you will learn about concepts of neural networks with the help of mathematical models examples. In simple words, you will learn about how to represent the neural networks using mathematical equations. As a data scientist / machine learning researcher, it would be good to get a sense of how the neural networks can be converted into a bunch of mathematical equations for calculating different values. Having a good understanding of representing the activation function output of different computation units / nodes / neuron in different layers would help in understanding back propagation algorithm in a better and easier manner. This will be dealt in one of the …
Adaptive Linear Neuron (Adaline) Python Example
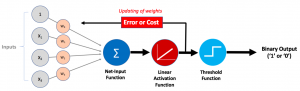
In this post, you will learn the concepts of Adaline (ADAptive LInear NEuron), a machine learning algorithm, along with Python example.As like Perceptron, it is important to understand the concepts of Adaline as it forms the foundation of learning neural networks. The concept of Perceptron and Adaline could found to be useful in understanding how gradient descent can be used to learn the weights which when combined with input signals is used to make predictions based on unit step function output. Here are the topics covered in this post in relation to Adaline algorithm and its Python implementation: What’s Adaline? Adaline Python implementation Model trained using Adaline implementation What’s Adaptive …
Yann LeCun Deep Learning Free Online Course

This post is about listing down free online course materials for deep learning (PyTorch) by none other than Yann LeCun. Here are some useful links to the deep learning course: Deep Learning course – Homepage Deep learning lecture slides Github pages having Jupyter notebooks having PyTorch code Lectures slides, notebooks and related YouTube videos can be found on the deep learning (DL) course home page. It is a 14 week course and covers different topics such as following: Introduction to deep learning (What DL can do, what are good features / representations) Gradient descent and back propagation algorithm Artificial neural networks Convolution neural networks (Convnets) and related applications Regularization / Optimization …
Python Implementations of Machine Learning Models
This post highlights some great pages where python implementations for different machine learning models can be found. If you are a data scientist who wants to get a fair idea of whats working underneath different machine learning algorithms, you may want to check out the Ml-from-scratch page. The top highlights of this repository are python implementations for the following: Supervised learning algorithms (linear regression, logistic regression, decision tree, random forest, XGBoost, Naive bayes, neural network etc) Unsupervised learning algorithms (K-means, GAN, Gaussian mixture models etc) Reinforcement learning algorithms (Deep Q Network) Dimensionality reduction techniques such as PCA Deep learning Examples that make use of above mentioned algorithms Here is an insight into …
RANSAC Regression Explained with Python Examples
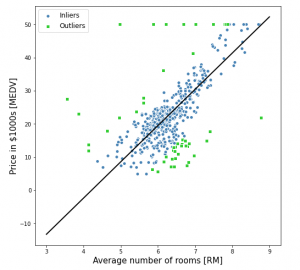
In this post, you will learn about the concepts of RANSAC regression algorithm along with Python Sklearn example for RANSAC regression implementation using RANSACRegressor. RANSAC regression algorithm is useful for handling the outliers dataset. Instead of taking care of outliers using statistical and other techniques, one can use RANSAC regression algorithm which takes care of the outlier data. In this post, the following topics are covered: Introduction to RANSAC regression RANSAC Regression Python code example Introduction to RANSAC Regression RANSAC (RANdom SAmple Consensus) algorithm takes linear regression algorithm to the next level by excluding the outliers in the training dataset. The presence of outliers in the training dataset does impact …
I found it very helpful. However the differences are not too understandable for me