Tag Archives: machine learning
Google Cloud Automl: Business Application Examples

Google cloud platform (GCP) automl services are a set of google cloud platform products with a focus on machine learning and automation. They help you to automate several tasks related to machine learning. In this blog post, we’ll talk about google cloud automl services and some common business problems that can be solved using these GCP automl services. What are some popular Google Cloud Automl services? Google cloud automl services include some of the following: Google Cloud Vision can be used to perform tasks related to image recognition like face detection, OCR (optical character recognition), landmark detection, etc. Google’s cloud vision can detect emotions, understand text, and more. The service …
NIT Warangal offers one-week online training on AI, Machine Learning

Are you interested in learning about AI and Machine Learning, or refresing your concepts? NIT Warangal offers one-week online paid training (minimal fees) on AI, Machine Learning. This program is a great opportunity for students to learn about AI & machine learning basics and advanced concepts. It is organized by the Department of Electronics and Communication Engineering & Department of R&D in association with Center of Continuing Education. It will be taught by experience professors who have years of experience in their respective fields. The course will take place between 30th November to 4th December 2021, and it is open to all Faculty/ Research Scholars/Industry professionals/ and other eligible students …
ML Engineer vs Data Scientist: Differences & Similarities
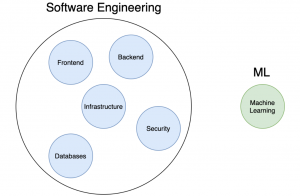
In today’s world, ML (machine learning) engineer and Data scientist are two popular job positions. These positions have a lot of overlap but there are also some key differences to be aware of. In this blog post, we will go over the details of ML engineers vs Data scientists so you can decide which one is right for you! What does an ML engineer do? An ML engineer primarily designs and develops machine learning systems. Before getting into the roles & responsibilities of an ML engineer, let’s understand what is a machine learning system. A machine learning system can be defined as a system that comprises of one or more …
Real-World Applications of Convolutional Neural Networks
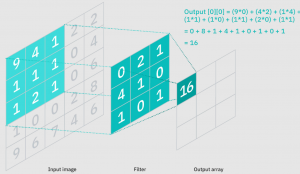
Convolutional neural networks (CNNs) are a type of deep learning algorithm that has been used in a variety of real-world applications. CNNs can be trained to classify images, detect objects in an image, and even predict the next word in a sentence with incredible accuracy. CNNs can also be applied to more complex tasks such as natural language processing (NLP). CNNs are very good at solving classification problems because they’re able to identify patterns within data sets. This blog post will explore some CNN applications and discuss how CNN models can be used to solve real-world problems. Before getting into the details of CNN applications, let’s quickly understand what are …
Week Nov1, 2021: Top 3 Machine Learning Tutorial Videos

The field of machine learning is a vast topic and it can be hard to know where to start. In this blog post, we’ll cover the top three free tutorial videos on machine learning from YouTube published this week (Week of Nov 1, 2021). These videos will help you get started with the basics of machine learning & deep learning, introduce you to some popular algorithms in use today, and give you an idea of what’s possible when building a model from scratch. Build a Machine Learning Project From Scratch with Python and Scikit-learn Let’s say you want to build a machine learning project from scratch. Maybe you’re not sure …
Support Vector Machine (SVM) Interview Questions

Support Vector Machine (SVM) is a machine learning algorithm that can be used to classify data. SVM does this by maximizing the margin between two classes, where “margin” refers to the distance from both support vectors. SVM has been applied in many areas of computer science and beyond, including medical diagnosis software for tuberculosis detection, fraud detection systems, and more. This blog post consists of quiz comprising of questions and answers on SVM. This is a practice test (objective questions and answers) that can be useful when preparing for interviews. The questions in this and upcoming practice tests could prove to be useful, primarily, for data scientists or machine learning interns/ …
Machine Learning Examples from Daily Life

Machine learning is a powerful machine intelligence technique that can be used in a variety of settings to generate data insights. In this blog post, we will explore real-world or real-life machine learning / deep learning / AI examples from daily life. We’ll see how machine-learning techniques have been successfully applied to solve real-life problems. The idea is to make you aware of how machine learning and data science applications are everywhere. What are some real-world examples of machine learning from daily life? Here are some real-world examples of machine learning that we use in our daily life: Best driving directions (Google Maps): A bunch of machine learning / deep …
Stock Price Prediction using Machine Learning Techniques
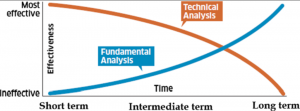
In the past few decades, many advances have been made in the field of data analytics. Researchers are now able to predict stock prices with higher accuracy due to analytical predictive models. These predictive techniques utilize data from previous stock price movements and look for patterns that could indicate future stock price changes in the market. The use of these machine learning techniques will allow investors to make better decisions and invest more wisely by maximizing their returns and minimizing their losses. In this blog post, you will learn about some of the popular machine learning techniques in relation to making stock price movement (direction of stock price) predictions and …
Data Science / AI Team Structure – Roles & Responsibilities

Setting up a successful artificial intelligence (AI) / data science or advanced analytics practice or center of excellence (CoE) is key to success of AI in your organization. In order to setup a successful data science COE, setting up a well-organized data science team with clearly defined roles & responsibilities is the key. Are you planning to set up the AI or data science team in your organization, and hence, looking for some ideas around data science team structure and related roles and responsibilities? In this post, you will learn about some of the following aspects related to the building data science/machine learning team. Focus areas Roles & responsibilities Data Science Team – Focus …
Sentiment Analysis & Machine Learning Techniques

Artificial intelligence (AI) / Machine learning (ML) techniques are getting more and more popular. Many people use machine learning to analyze the sentiment of tweets, for example, to make predictions related to different business areas. In this blog post, you will learn about different machine learning / deep learning and NLP techniques which can be used for sentiment analysis. What is sentiment analysis? Sentiment analysis is about predicting the sentiment of a piece of text and then using this information to understand users’ (such as customers) opinions. . The principal objective of sentiment analysis is to classify the polarity of textual data, whether it is positive, negative, or neutral. Whether …
Clinical Trials & Predictive Analytics Use Cases
Analytics plays a big role in modeling clinical trials and predictive analytics is one such technique that has been embraced by clinical researchers. Machine learning algorithms can be applied at various stages in the drug discovery process – from early compound selection to clinical trial simulation. Data scientists have been applying machine learning algorithms to clinical trial data in order to identify predictive patterns and correlations between clinical outcomes, patient demographics, drug response phenotypes, medical history, and genetic information. Predictive analytics has the potential to enhance clinical research by helping accelerate clinical trials through predictive modeling of clinical outcome probability for better treatment decisions with reduced clinical trial costs. In …
Procure-to-pay Processes & Machine Learning
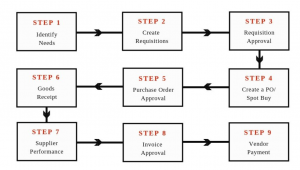
The procure-to-pay (P2P) cycle or process consists of a set of steps that must be taken in order for an organization to procure and pay for goods and services. Procurement is the process by which organizations purchase goods, supplies, equipment, or services from outside sources. The procurement function may also serve as an intermediary between two internal departments or divisions that have overlapping needs. In this blog post, we will discuss how AI / machine learning can be leveraged to automate certain procure-to-pay processes such that procure-to-pay teams can focus on core business goals. What is the procure-to-pay cycle or process? The procure-to-pay (P2P) cycle or process is defined as …
Building Machine Learning Models & Dev Challenges
The machine learning models and AI implementation industry is booming. The demand for machine learning models has never been higher, but the challenges of machine learning development and deployment have also increased. In this post, we will discuss a few common machine learning development and deployment challenges. In future blogs, we will learn about solutions to overcome these challenges. This blog post will help you learn and understand some of the key challenges that you may face if you are planning to start machine learning practice in your organization. These challenges are also very much relevant if you have machine learning engineers and data scientists working across different offices/locations on …
Demand Forecasting & Machine Learning Techniques
Machine learning is a technology that can be used for demand forecasting in order to make demand forecasts more accurate and reliable. In demand forecasting, machine learning techniques are used to forecast demand for a product or service. There are different types of machine learning/deep learning techniques used in demand forecastings such as neural networks, support vector machines, time series forecasting, and regression analysis. This blog post will introduce different machine learning & deep learning techniques for demand forecasting and give an overview of how they work. What is the demand forecasting process? The demand forecasting process is defined as the creation of demand forecasts, demand planning, and demand decision …
Agriculture Use Cases & Machine Learning Applications

Today agriculture is in a state of flux. Farmers are faced with the challenges of producing more food in face of a changing climate and population growth, while also adapting to evolving technologies that have changed agriculture forever. Machine learning has been applied to agriculture for many different use cases, from irrigation scheduling to pest management. In this post, we will explore agriculture use cases for machine learning & deep learning that can help farmers meet these challenges head-on. Different machine learning applications can be built around these agricultural use cases. It will be helpful for data scientists to get a high level idea around use cases and related machine …
BigQuery ML Concepts & Examples: Starter Guide

BigQuery ML is a machine learning platform that allows data scientists to build models using the power of their data. Unlike traditional machine learning, BigQuery ML does not require any programming skills, making it an easy way to get started with machine learning. Product managers and data scientists can both benefit from BigQuery ML by finding insights in their own datasets or collaborating with one another on new applications. The introduction of BigQuery Machine Learning Platform has enabled organizations to take advantage of the benefits of machine learning without needing deep expertise in either big-data or analytics technologies. This blog post will provide an overview of what you need to …
I found it very helpful. However the differences are not too understandable for me