In this post, you will learn about how to setup / install MLFlow right from your Jupyter Notebook and get started tracking your machine learning projects. This would prove to be very helpful if you are running an enterprise-wide AI practice where you have a bunch of data scientists working on different ML projects. Mlflow will help you track the score of different experiments related to different ML projects.
Install MLFlow using Jupyter Notebook
In order to install / set up MLFlow and do a quick POC, you could get started right from within your Jupyter notebook. Here are the commands to get set up. Mlflow could be installed with simple command: pip install mlflow. Within Jupyter notebook, this is what you would do:
#
# Install MLFLow using PIP Install
#
!pip install mlflow
#
# Check whether MLFlow installed by accessing its version
#
!mlflow --version
Executing above commands would set up MLFlow and print its version. It printed this for me: mlflow, version 1.11.0
Next step is to start MLFlow UI. Here is the command to get started with MLFlow UI from within Jupyter Notebook
#
# Mlflow UI
#
!mlflow ui
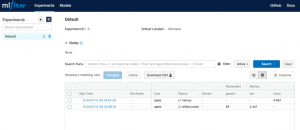
You could as well execute the command, mlflow ui, in the command prompt and it would start the server at URL such as http://127.0.0.1:5000/. This is how the Mlflow UI would look like:
Next step is to run some experiments in form of training a model. The goal is to track the model runs in MLFlow UI.
Run Experiments / Train Model & Track using MLFlow UI
In order to getting started with training model and tracking model scores / experiment outcomes using MLFlow, I would suggest you take a look at this POC.
Download the MLFlow sample code from this MLFlow github page: https://github.com/mlflow/mlflow. You can train a simplistic logistic regression model using the code given below. This could can be found in the following folder in the downloaded code (examples/sklearn_logistic_regression/train.py).
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
All this is required to be done is to add the below code to your machine learning model training code and execute with Python. This would make sure that MLflow runs can be recorded to local file. You could as well record the MLFlow runs on remote server. To log ML project runs remotely, you will need to set the MLFLOW_TRACKING_URI environment variable to the tracking server’s URI. The code below is executed from within Jupyter notebook.
!python /Users/apple/Downloads/mlflow-master/examples/sklearn_logistic_regression/train.py
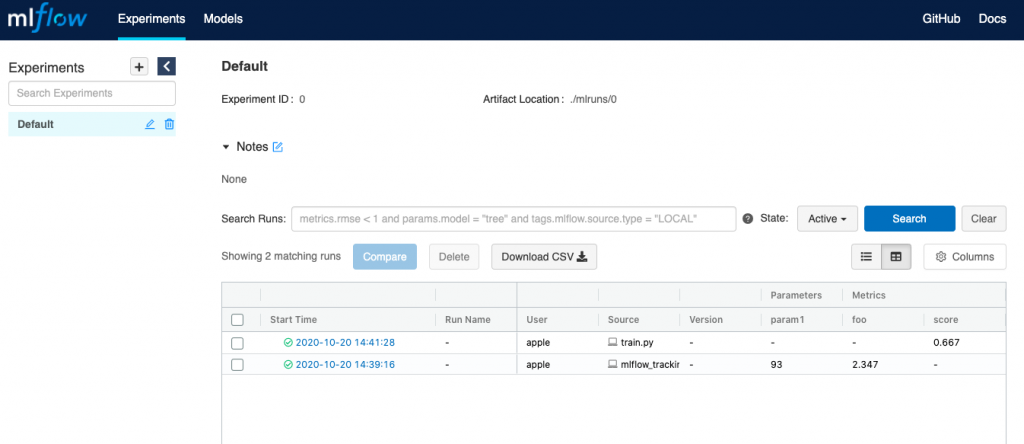
This will output the following shown as a screenshot:

The above run could now be accessed in MLFlow UI.
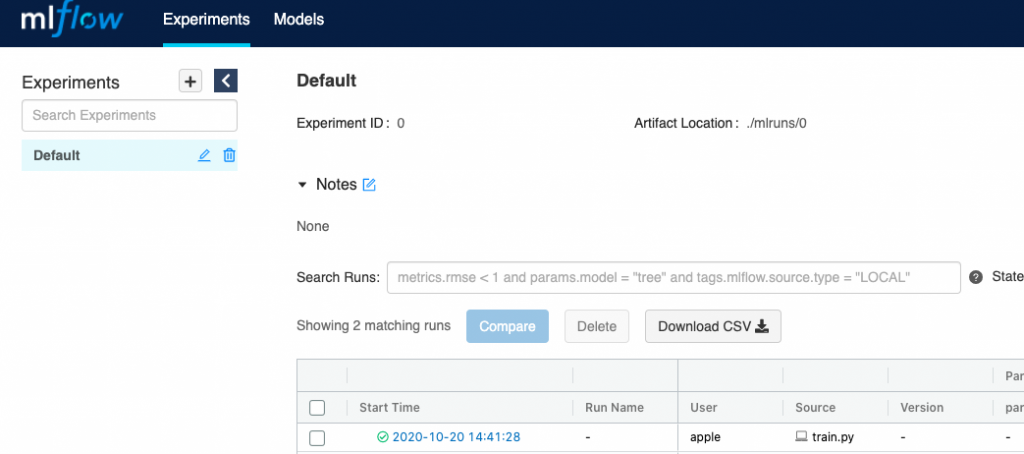
You could learn more about MLFlow on MLFLow concept page.
Conclusions
Here is the summary of what you learned in this post in relation to setting up / installing MLFlow and getting started:
- MLflow can be installed simply with command such as pip install mlflow.
- Mlflow UI can be started using command such as mlflow ui
- Machine learning model training logs can be written by using MLFlow APIs / methods in the model training code.
- MLflow runs can be recorded to local files, to a SQLAlchemy compatible database, or remotely to a tracking server.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me