Have you ever wondered how generative AI is converting words into images? Or how generative AI models create a picture of something you’ve only described in words? Creating high-quality images from textual descriptions has long been a challenge for artificial intelligence (AI) researchers. That’s where DALL-E and DALL-E 2 comes in. In this blog, we will look into the details related to Dall-E 2.
Developed by OpenAI, DALL-E 2 is a cutting-edge AI model that can generate highly realistic images from textual descriptions. So how does DALL-E 2 work, and what makes it so special? In this blog post, we’ll explore the key concepts and techniques behind DALL-E 2, including Contrastive Language-Image Pre-training (CLIP), diffusion models, and post-processing. We’ll also discuss the computational resources required to train a model like DALL-E 2 and the deep learning frameworks and libraries that can be used to implement it. By the end of this post, you’ll have a solid understanding of how DALL-E 2 works and what makes it such an exciting development in the world of generative AI.
What’s DALL-E 2 and How does it work?
DALL-E 2 is a type of large language model (a type of generative models) which uses diffusion model to convert text descriptions to images. It is trained based on encoder-decoder architecture. DALL-E 2 is a newer version (of DALL-E). It uses an encoder-decoder pipeline that encodes the text description into an OpenAI language model called Contrastive Language-Image Pre-training (CLIP) embedding, which is a high-dimensional vector that represents both the text and image content. The model then decodes this embedding back to an image using a diffusion model.
While DALL-E uses Vector Quantized Variational Autoencoder (VQ-VAE) to address the high dimensionality of image information compared to text, DALL-E 2 encodes the text description into an OpenAI language model called Contrastive Language-Image Pre-training (CLIP) embedding.
The following is a step-by-step workflow that explains how DALL-E 2 text-to-image generation works:
- Input Text fed to DALL-E 2: DALL-E 2 receives a textual description of an image as input provided by the end user.
- Text encoded using CLIP (CLIP Text Embeddings): The text input is encoded using CLIP, a pre-trained neural network that can encode both text and images into high-dimensional text/image embedding vectors. The CLIP encoder converts the input text into a high-dimensional vector representation that captures its semantic meaning. The converted vector representation can also be called as CLIP text embeddings.
- Clip text embeddings converted to CLIP image embeddings via Prior (Autoregressive or Diffusion Model): The CLIP text embedding is then passed through a Prior (autoregressive or diffusion model), which is a type of generative model that can sample from a probability distribution to generate realistic images. The diffusion model is trained to generate high-quality images that match the encoded text vector. Out of autoregressive and diffusion models, diffusion model was found to perform better.
- CLIP image embeddings to final image generation: Once the diffusion model (prior) has generated a CLIP image embedding, it is passed through a diffusion decoder (diffusion model) which then generates the final image.
It should be noted that while building DALL-E 2, it was also tried to pass the CLIP text embedding in step #2 directly (without using prior) to decoder in step #4 for final image generation. However, it was found that using a prior resulted in better image generation.
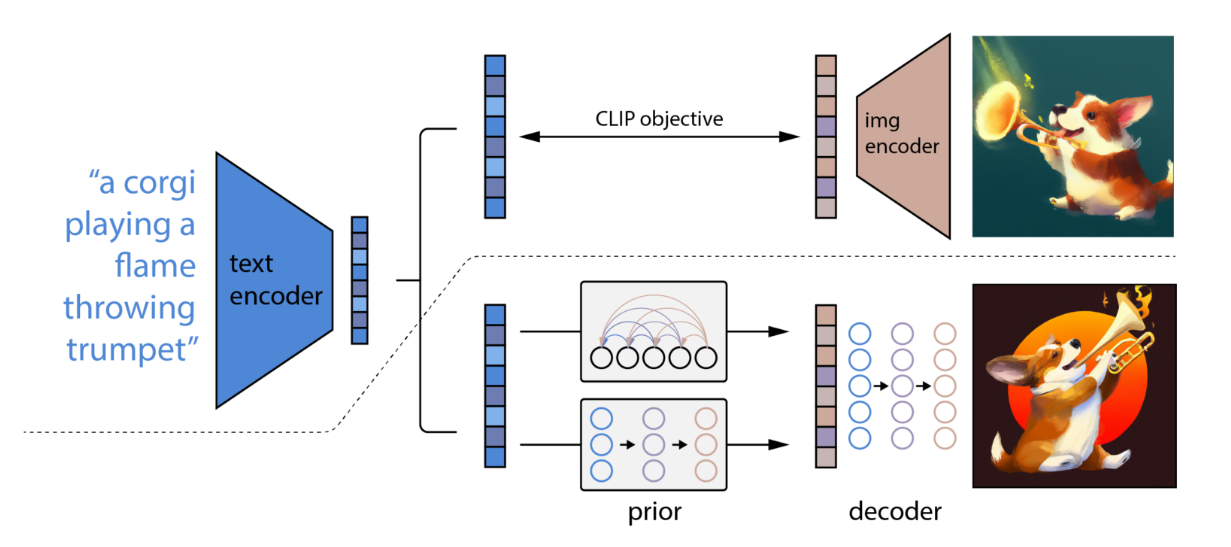
The image above represents the following:
- The part of image on top represents CLIP training process using which a joint representation space of text and image is learned.
- The version in the bottom represents text-to-image generation process explained above.
For greater information, read this paper: Hierarchical text-conditional image generation with CLIP latents
Building Something Like DALL-E 2
DALL-E 2 is a complex generative model that requires significant computational resources and specialized training methods. DALL-E 2 uses several existing deep learning techniques, such as Contrastive Language-Image Pre-training (CLIP) and diffusion models, which can be implemented using existing deep learning frameworks in Python such as PyTorch or TensorFlow.
CLIP can be implemented in PyTorch using the CLIP module provided by OpenAI’s official repository. Diffusion models can also be implemented in PyTorch. Check out the paper, denoising diffusion probabilistic models which is one of the first papers on generating images using diffusion models. Here is one of the PyTorch implementation of this paper for generating images using diffusion models.
It’s worth noting that training a model like DALL-E 2 requires significant expertise and computational resources, and may typically be beyond the scope of most individual researchers or small teams. However, researchers and developers can still use existing pre-trained models or adapt existing techniques to their specific use cases using the available deep learning frameworks.
Conclusion
DALL-E 2 represents a significant breakthrough in the field of generative AI, with the ability to generate highly realistic and detailed images from textual descriptions. By leveraging the power of CLIP encoding, diffusion models, and post-processing techniques, DALL-E 2 can produce images that match the meaning and intent of the input text. As deep learning frameworks and computational resources continue to advance, we can expect to see even more impressive and impactful applications of models like DALL-E 2 in the future. For data scientists and AI enthusiasts alike, understanding the concepts and techniques behind DALL-E 2 is a valuable step towards unlocking the full potential of generative AI.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me