Tag Archives: generative ai
Chunking Strategies for RAG with Examples
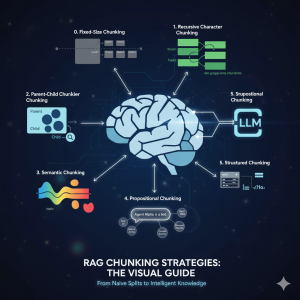
If you’ve built a “Naive” RAG pipeline, you’ve probably hit a wall. You’ve indexed your documents, but the answers are… mediocre. They’re out of context, they miss the point, or they just feel wrong. Here’s the truth: Your RAG system is only as good as its chunks. Chunking—the process of breaking your documents into searchable pieces—is one of the most important decision you will make in your RAG pipeline. It’s not just “preprocessing”; it is the foundation of your AI’s knowledge in the RAG application. The problem is what I call the “Chunking Goldilocks Problem”: Let’s walk through the evolution of chunking strategies, from the simple baseline to the state-of-the-art, …
RAG Pipeline: 6 Steps for Creating Naive RAG App
If you’re starting with large language models, you must have heard of RAG (Retrieval-Augmented Generation). It’s the magic that lets AI chatbots talk about your data—your company’s PDFs, your private notes, or any new information—without “hallucinating.” It might sound complex, but the core logic of a simple RAG pipeline can be boiled down to six simple steps. We’re going to walk through the “conductor” script that runs this pipeline, showing you how data flows from a raw document to a smart, factual answer. Our entire system is built on this simple mantra: Let’s look at the Python code that brings this mantra to life. Step 0: Loading Our “Brains” (The …
Large Language Models (LLMs): Four Critical Modeling Stages
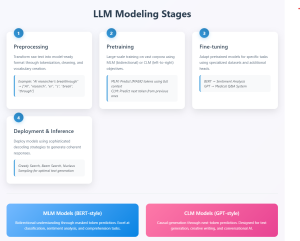
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and search engines to code generators and creative writing assistants. Yet behind every seemingly effortless AI conversation lies a sophisticated multi-stage modeling process that transforms raw text into intelligent, task-specific systems capable of human-like understanding and generation. Understanding the LLM modeling stages described later in this blog is crucial to be able to create pre-trained model and finetune them. Let’s explore and learn about these LLM modeling stages. Stage 1: Preprocessing – Laying the Foundation The preprocessing stage involves transforming raw text data into a format suitable for model training. This includes segmenting the raw text …
Retrieval Augmented Generation (RAG) & LLM: Examples
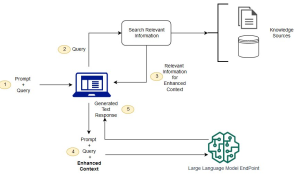
Last updated: 25th Jan, 2025 Have you ever wondered how to seamlessly integrate the vast knowledge of Large Language Models (LLMs) with the specificity of domain-specific knowledge stored in file storage, relational databases, graph databases, vector databases, etc? As the world of LLMs continues to evolve, the need for more sophisticated and contextually relevant responses from LLMs becomes paramount. Lack of contextual knowledge can result in LLM hallucination thereby producing inaccurate, unsafe, and factually incorrect responses. This is where question & context augmentation to prompts is used for contextually sensitive answer generation with LLMs, and, the retrieval-augmented generation method, comes into the picture. For data scientists and product managers keen …
How to Setup MEAN App with LangChain.js

Hey there! As I venture into building agentic MEAN apps with LangChain.js, I wanted to take a step back and revisit the core concepts of the MEAN stack. LangChain.js brings AI-powered automation and reasoning capabilities, enabling the development of agentic AI applications such as intelligent chatbots, automated customer support systems, AI-driven recommendation engines, and data analysis pipelines. Understanding how it integrates into the MEAN stack is essential for leveraging its full potential in creating these advanced applications. So, I put together this quick learning blog to share what I’ve revisited. The MEAN stack is a popular full-stack JavaScript framework that consists of MongoDB, Express.js, Angular, and Node.js. Each component plays …
Completion Model vs Chat Model: Python Examples

In this blog, we will learn about the concepts of completion and chat large language models (LLMs) with the help of Python examples. What’s the Completion Model in LLM? A completion model is a type of LLM that takes a text input and generates a text output, which is called a completion. In other words, a completion model is a type of LLM that generates text that continues from a given prompt or partial input. When provided with an initial piece of text, the model uses its trained knowledge to predict and generate the most likely subsequent text. A completion model can generate summaries, translations, stories, code, lyrics, etc depending on …
LLM Hosting Strategy, Options & Cost: Examples

As part of laying down application architecture for LLM applications, one key focus area is LLM deployments. Related to LLM deployment is laying down LLM hosting strategy as part of which different hosting options need to be looked at, and evaluated based on various criteria including cost and appropriate hosting should be selected. In this blog, we will learn about different hosting options for different kinds of LLM and related strategies. LLM Hosting Cost depends on the type of LLM Needed What is going to be the cost related to LLM hosting depends upon the type of LLM we need for our application. LLM Hosting Cost for Proprietary Models If …
Application Architecture for LLM Applications: Examples
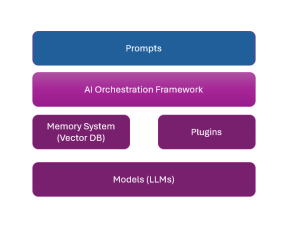
Large language models (LLMs), also termed large foundation models (LFMs), in recent times have been enabling the creation of innovative software products that are solving a wide range of problems that were unimaginable until recent times. Different stakeholders in the software engineering and AI arena need to learn about how to create such LLM-powered software applications. And, the most important aspect of creating such apps is the application architecture of such LLM applications. In this blog, we will learn about key application architecture components for LLM-based applications. This would be helpful for product managers, software architects, LLM architects, ML engineers, etc. LLMs in the software engineering landscape are also termed …
Autoencoder vs Variational Autoencoder (VAE): Differences, Example
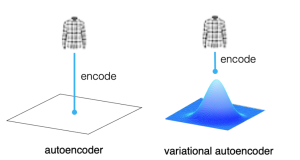
Last updated: 12th May, 2024 In the world of generative AI models, autoencoders (AE) and variational autoencoders (VAEs) have emerged as powerful unsupervised learning techniques for data representation, compression, and generation. While they share some similarities, these algorithms have unique properties and applications that distinguish them. This blog post aims to help machine learning / deep learning enthusiasts understand these two methods, their key differences, and how they can be utilized in various data-driven tasks. We will learn about autoencoders and VAEs, understanding their core components, working mechanisms, and common use cases. We will also try and understand their differences in terms of architecture, objectives, and outcomes. What are Autoencoders? …
Attention Mechanism in Transformers: Examples
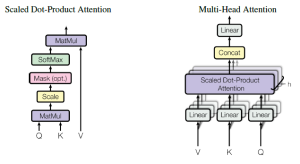
Last updated: 1st Feb, 2024 The attention mechanism allows the model to focus on relevant words or phrases when performing NLP tasks such as translating a sentence or answering a question. It is a critical component in transformers, a type of neural network architecture used in NLP tasks such as those related to LLMs. In this blog, we will delve into different aspects of the attention mechanism (also called an attention head), common approaches (such as self-attention, cross attention, etc.) to calculating and implementing attention, and learn the concepts with the help of real-world examples. You can get good details in this book: Generative Deep Learning by David Foster. You …
Large Language Models (LLMs): Types, Examples
Last updated: 31st Jan, 2024 Large language models (LLMs), being the key pillar of generative AI, have been gaining traction in the world of natural language processing (NLP) due to their ability to process massive amounts of text and generate accurate results related to predicting the next word in a sentence, given all the previous words. These different LLM models are trained on a large or broad corpus of text datasets, which contain hundreds of millions to billions of words. LLMs, as they are known, rely on complex algorithms including transformer architectures that shift through large datasets and recognize patterns at the word level. This data helps the LLMs better understand …
LLM Optimization for Inference – Techniques, Examples
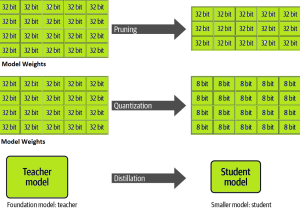
One of the common challenges faced with the deployment of large language models (LLMs) while achieving low-latency completions (inferences) is the size of the LLMs. The size of LLM throws challenges in terms of compute, storage, and memory requirements. And, the solution to this is to optimize the LLM deployment by taking advantage of model compression techniques that aim to reduce the size of the model. In this blog, we will look into three different optimization techniques namely pruning, quantization, and distillation along with their examples. These techniques help model load quickly while enabling reduced latency during LLM inference. They reduce the resource requirements for the compute, storage, and memory. …
Transfer Learning vs Fine Tuning LLMs: Differences
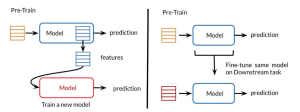
Last updated: 23rd Jan, 2024 Two NLP concepts that are fundamental to large language models (LLMs) are transfer learning and fine-tuning pre-trained LLMs. Rather, true fine-tuning can also be termed as full fine-tuning because transfer learning is also a form of fine-tuning. Despite their interconnected nature, they are distinct methodologies that serve unique purposes when training foundation LLMs to achieve different objectives. In this blog, we will explore the differences between transfer Learning and full fine-tuning, learning about their characteristics and how they come into play in real-world scenarios related to natural language understanding (NLU) and natural language generation (NLG) tasks with the help of examples. We will also learn …
Transformer Architecture in Deep Learning: Examples
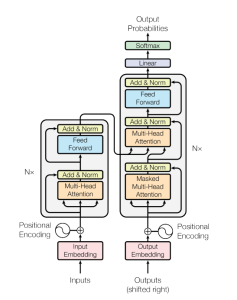
The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need. Transformer Block – Core Building Block of Transformer Model Architecture Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block. The core building block of the Transformer architecture consists of multi-head attention …
LLM Training & GPU Memory Requirements: Examples
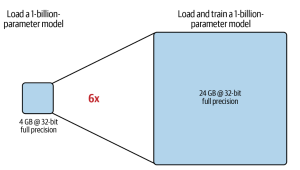
As data scientists and MLOps Engineers, you must have come across the challenges related to managing GPU requirements for training and deploying large language models (LLMs). In this blog, we will delve deep into the intricacies of GPU memory demands when dealing with LLMs. We’ll learn with the help of various examples to better understand how GPU memory impacts the performance and feasibility of training these LLMs. Whether you’re planning to train a foundation (pre-trained) model or fine-tuning an existing model, the insights are aimed to guide you through the crucial considerations of GPU memory allocation. Greater details can be found in this book: Generative AI on AWS. Understanding GPU …
Instruction Fine-tuning LLM Explained with Examples

A pre-trained or foundation model is further trained (or fine-tuned) with instructions datasets to help them learn about your specific data and perform humanlike tasks. These models are called instruction fine-tuning LLMs. In this blog, we will learn about the concepts and different examples of instruction fine-tuning models. You might want to check out this book to learn more: Generative AI on AWS. What are Instruction fine-tuning LLMs? Instruction fine-tuning LLMs, also called chat or instruct models, are created by training pre-trained models with different types of instructions. Instruction fine-tuning can be defined as a type of supervised machine learning that improves the foundation model by continuously comparing the model’s …

I found it very helpful. However the differences are not too understandable for me