Author Archives: Ajitesh Kumar
Machine Learning Programming Languages List

If you’re interested in pursuing a career in machine learning, you’ll need to have a firm grasp of at least one programming language. But with so many languages to choose from, which one should you learn? Here are three of the most popular machine learning programming languages, along with a brief overview of each. Python Python is a programming language with many features that make it well suited for machine learning. It has a large and active community of developers who have contributed a wide variety of libraries and tools. Python’s syntax is relatively simple and easy to learn, making it a good choice for people who are new to …
NoSQL Databases List & Examples
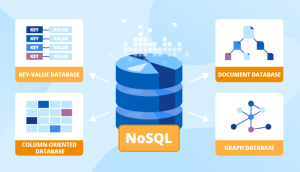
With the proliferation of big data, there has been a corresponding increase in the number of NoSQL databases. For those who are new to the term, NoSQL databases are non-relational databases that are designed to handle large amounts of data. In this blog post, we will take a look at some of the most popular NoSQL databases. NoSQL databases are a newer alternative to traditional relational databases that are designed to provide more flexibility and scalability. NoSQL databases are often used for big data applications that require real-time analysis or for applications that need to be able to handle a large amount of concurrent users. While NoSQL databases can offer …
Free Machine Learning Courses from Top US Universities

Anyone looking to start learning machine learning has a plethora of resources at their disposal. However, with so many choices it can be difficult to know where to start. This blog post will outline four free machine learning courses from top US universities such as Harvard, Stanford, MIT, etc that are sure to get you on the right track. List of Online Free Courses on Machine Learning The following is a list of online free courses on machine learning from some of the top US universities: Harvard’s CS50p: Intro to Python (cs50.harvard.edu/python/2022/) MIT 6.S191: Intro to Deep Learning (https://introtodeeplearning.com/) Cornell Tech CS 5787: Applied machine learning course (https://cornelltech.github.io/cs5785-fall-2019/) Stanford’s Machine …
Data Preprocessing Steps in Machine Learning

Data preprocessing is an essential step in any machine learning project. By cleaning and preparing your data, you can ensure that your machine learning model is as accurate as possible. In this blog post, we’ll cover some of the important and most common data preprocessing steps that every data scientist should know. Replace/remove missing data Before building a machine learning model, it is important to preprocess the data and remove or replace any missing values. Missing data can cause problems with the model, such as biased results or inaccurate predictions. There are a few different ways to handle missing data, but the best approach depends on the situation. In some …
Resume Screening using Machine Learning & NLP

In today’s job market, there are many qualified candidates vying for the same position. So, how do you weed out the applicants who are not a good fit for your company? One way to do this is by using machine learning and natural language processing (NLP) to screen resumes. By using machine learning and NLP to screen resumes, you can more efficiently identify candidates who have the skills and qualifications you are looking for. In this blog, we will learn different aspects of screening and selecting / shortlisting candidates for further processing using machine learning & NLP techniques. Key Challenges for Resume Screening / Shortlisting Resume screening is the process …
Supply chain management & Machine Learning
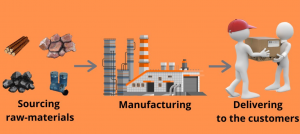
As supply chains become more complex, businesses are looking for new ways to optimize and automate their supply chain operations. One area that is seeing a lot of growth is the use of artificial intelligence (AI) and machine learning in supply chain management. There are many different applications for these technologies in supply chain management, from forecasting demand to optimizing inventory levels. In this blog post, we will explore some of the most interesting use cases for AI and machine learning in supply chain management. What is supply chain management and what are its key components? Supply chain management is the process of coordinating and controlling the flow of goods, …
List of Blockchain Platforms & Examples
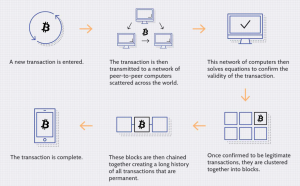
You may have heard of Bitcoin, Ethereum, or even Hyperledger, but what exactly are they? They are all examples of different types of blockchain platforms. In this blog post, we will give a detailed overview of the list of the different types of blockchain platforms and some examples to help you better understand this cutting-edge technology. Bitcoin Blockchain Bitcoin is a digital asset and a payment system invented by Satoshi Nakamoto. Transactions are verified by network nodes through cryptography and recorded in a public dispersed ledger called a blockchain. Bitcoin is unique in that there are a finite number of them: 21 million. Bitcoin blockchains function differently from traditional ledgers. …
Car Insurance & Machine Learning Use Cases

The car insurance industry is one of the many sectors that have been disrupted by the advent of machine learning. In the past, car insurance companies have relied on historical data to set premiums. However, machine learning / AI has enabled insurers to better predict risk and price insurance policies more accurately. As a result, AI / machine learning is transforming the car insurance industry by making it more efficient and customer-centric. In this blog, you will learn about some key car insurance use cases which can be dealt using machine learning. Detecting fraudulent car insurance claims Fraudulent car insurance claims are a problem for both insurers and policyholders. They …
Bagging vs Boosting Machine Learning Methods
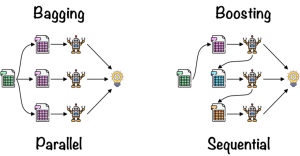
In machine learning, there are a variety of methods that can be used to improve the performance of your models. Two of the most popular methods are bagging and boosting. In this blog post, we’ll take a look at what these methods are and how they work with the help of examples. What is Bagging? Bagging, short for “bootstrap aggregating”, is a method that can be used to improve the accuracy of your machine learning models. The idea behind bagging is to train multiple models on different subsets of the data and then combine the predictions of those models. The data is split into a number of smaller datasets, or …
Weak Supervised Learning: Concepts & Examples
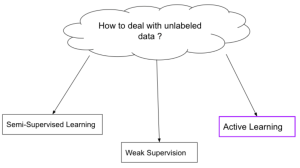
Supervised learning is a type of machine learning algorithm that uses a labeled dataset to learn and generalize from. The labels act as supervisors, providing the algorithm with feedback so it can learn to map input data to the correct output labels. In this blog post, we’ll be focusing on weak supervised learning, a subset of supervised learning that uses only partially labeled or unlabeled data. We’ll cover some of the most common weak supervision techniques and provide examples of each. What is Weak Supervised Learning? Weak supervised learning is a type of machine learning where the learner is only given a few labels to work with. Weak supervision is …
Diabetes Detection & Machine Learning / AI

Diabetes is a chronic disease that affects millions of people worldwide. The early detection of diabetes is crucial to preventing the development of serious complications. However, traditional methods of diabetes detection are often inaccurate and invasive. Machine learning / AI offers a promising solution for the early detection of diabetes. Machine learning algorithms can automatically detect patterns in data and use those patterns to make predictions. Machine learning is well suited for the detection of diabetes because it can handle the large amount of data required for accurate predictions. In addition, machine learning algorithms can automatically identify patterns that are too subtle for humans to discern. Quick Overview on Machine …
Healthcare Claims Processing AI Use Cases
In recent years, artificial intelligence (AI) / machine learning (ML) has begun to revolutionize many industries – and healthcare is no exception. Hospitals and insurance companies are now using AI to automate various tasks in the healthcare claims processing workflow. Claims processing is a complex and time-consuming task that often requires manual intervention. By using AI to automate claims processing, healthcare organizations can reduce costs, improve accuracy, and speed up the claims adjudication process. In this blog post, we will explore some of the most common use cases for healthcare claims processing AI / machine learning. Automated Data Entry One of the most time-consuming tasks in the claims process is …
Top Healthcare Data Aggregation Companies
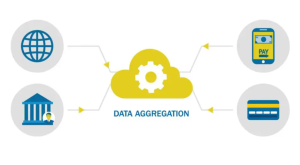
Data aggregation is the process of collecting data from multiple sources and compiling it into a single database. This process is essential for healthcare professionals, companies and startups because it allows them to track and analyze patient data, which can be used to improve patient care. There are many companies that offer healthcare data aggregation services. However, not all of them are created equal. To help you choose the right company for your needs, we’ve compiled the following list of the top healthcare data aggregation companies. This list will be updated from time-to-time. Athenahealth: Athenahealth is a healthcare data aggregation company that provides electronic health records, practice management software, and …
How to Prepare for a Python Interview

Python has become the most popular programming language in the world and is one of the most in-demand languages by employers. It is a widely used high-level interpreted programming language. Its design philosophy emphasizes code readability and its syntax allows programmers to express concepts in fewer lines of code than would be possible in languages such as C++ or Java. The language provides constructs intended to enable clear programs on both a small and large scale. As such, if you’re a Python programmer, you’re likely to face stiff competition when applying for jobs. In order to increase your chances of landing an interview, it’s important to be well prepared. In …
ESG & AI / Machine Learning Use Cases

Environmental, social, and governance (ESG) factors are a set of standards used to evaluate a company’s performance on issues that have an impact on society and the environment. AI or machine learning can be used to help identify these factors. In this blog post, we will explore some use cases for how AI / machine learning can be used in conjunction with ESG factors. The following is a list of AI use cases related ESG. This list will be updated from time-to-time. Predict ESG ratings using fundamental dataset: Investors (asset managers and asset owners) started to assess companies based on how they handle sustainability issues. To do this assessment, investors …
Checklist for Training Deep Learning Models
Deep learning is a powerful tool for solving complex problems, but it can be difficult to get started. In this blog post, we’ll provide a checklist of things to keep in mind when training and evaluating the deep learning models and deciding whether they are suitable to deploy in production. By following this checklist, you can ensure that your models are well-trained and ready to tackle real-world tasks. Validation of data distribution The distribution of data can have a significant impact on the performance of deep learning models. When training a model, it is important to ensure that the training data is representative of the distribution of the data that …

I found it very helpful. However the differences are not too understandable for me