In this post, you will learn different types of distance measures used in different machine learning algorithms such as K-nearest neighbours, K-means etc.
Distance measures are used to measure the similarity between two or more vectors in multi-dimensional space. The following represents different forms of distance metrics / measures:
- Geometric distances
- Computational distances
- Statistical distances
Geometric Distance Measures
Geometric distance metrics, primarily, tends to measure the similarity between two or more vectors solely based on the distance between two points in multi-dimensional space. The examples of such type of geometric distance measures are Minkowski distance, Euclidean distance and Manhattan distance. One other different form of geometric distance is cosine similarity which will discuss in this section.
Minkowski distance is the general form of Euclidean and Manhattan distance. Mathematically, it can be represented as the following:
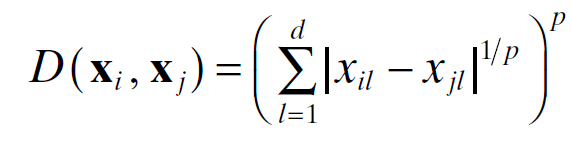
When the value of P becomes 1, it is called Manhattan distance. When P takes the value of 2, it becomes Euclidean distance. Let’s understand these distance measures with illustrative diagrams.
Euclidean Distance
The formula of Euclidean distance looks like the following. It is formed by assigning the value of P as 2 in Minkowski distance formula.
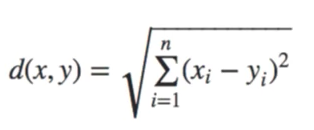
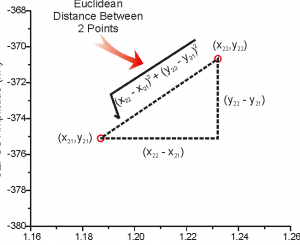
Let’s look at another illustrative example to understand Euclidean distance. Here it goes.

Euclidean distance looks very similar to the Pythagorean theorem. It is the most intuitive type of distance measure which can be used to calculate distances between two different points. Let’s say you want to find the distance between two different points in your city, you can use Euclidean distance for same. Here is the diagram which represents the same.
Recall the definition of displacement in Physics. Displacement is defined as the shortest distance between two different, and, so is Euclidean distance.
Manhattan Distance
If you want to find Manhattan distance between two different points (x1, y1) and (x2, y2) such as the following, it would look like the following:
Manhattan distance = (x2 – x1) + (y2 – y1)
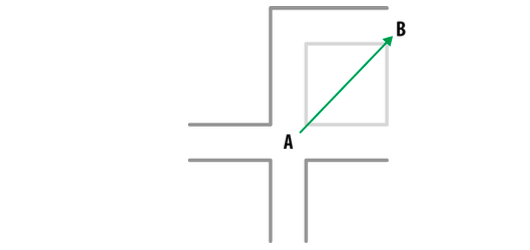
Diagrammatically, it would look like traversing the path from point A to point B while walking on the pink straight line.
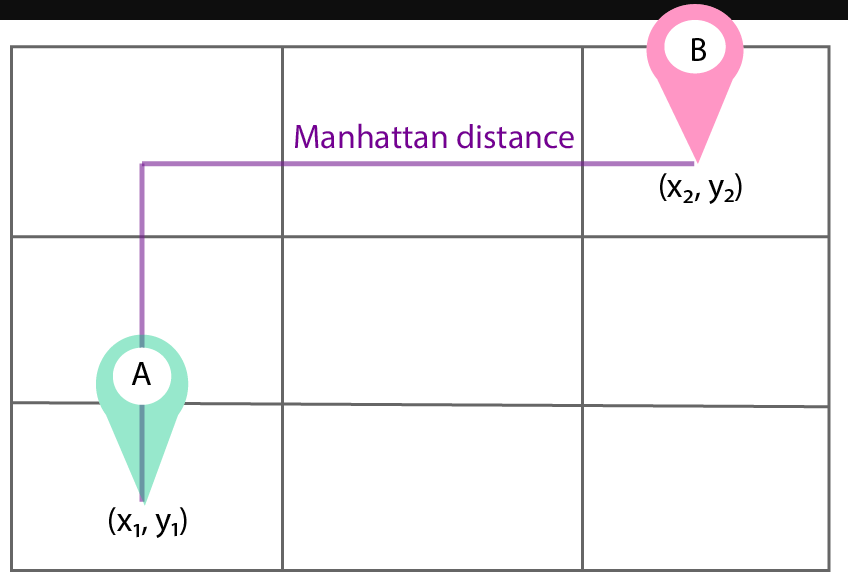
Another diagram which illustrates the Manhattan distance is the following. It is the path traversed represented by the line with arrow.

Let’s look at the diagram given below to understand Euclidean, Manhattan and Minkowski distance. Note that different value of P such as 1 and 2 in Minkowski distance results in Euclidean and Manhattan distance respectively. The distance measures used to measure distance between two points in the city are represented with different value of P in Minkowski distance formula.

Cosine Distance / Similarity
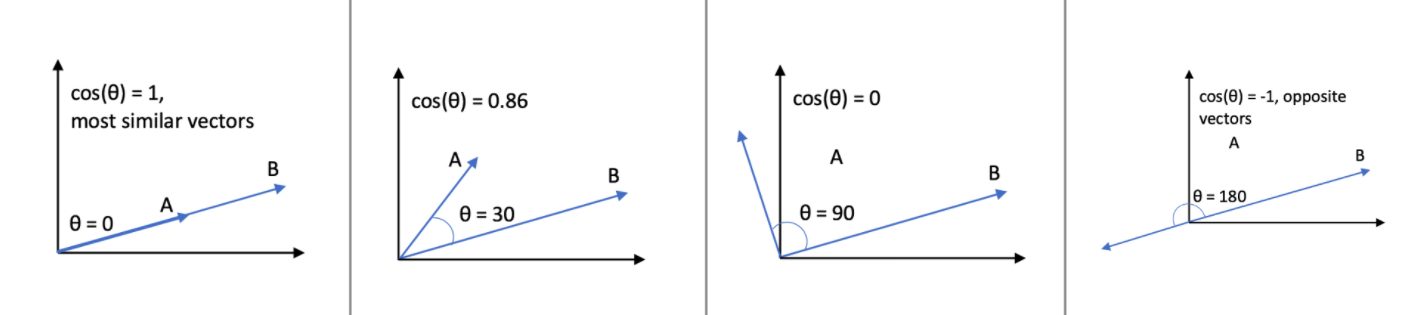
Cosine similarity is a measure of similarity between two non-zero vectors. It is calculated as an inner product of the two vectors that measures the cosine of the angle between them. The vectors which are most similar will have 0 degree between them. In other words, the most similar vectors will coincide with each other. The value of cos 0 is 1. The vector which will be opposite to each other or most dissimilar will have value as -1 (cos(180deg).
The advantage of using cosine distance is the sheer speed at calculating distances between sparse vectors. For instance, if there are 500 attributes collected about houses and 200 of these were mutually exclusive (meaning that one house had them but the others don’t), then there would only be need to include 300 dimensions in the calculation.
Here is the formula for cosine similarity between two vectors a and b having attributes in n dimensions

The diagram below represents cosine similarity between two vectors having different angle between them.
Statistical Distance Measures
Statistical distance measures is used to calculate distance between two statistical objects. The statistical distance measure is used in solving problems such as hypothesis testing, independence contrast, goodness of fit tests, classification tasks, outlier detection, density estimation methods etc. The following represents some of the important types of statistical distance measures:
- Mahalanobis distance
- Jaccard distance
Mahalanobis Distance
Mahalanobis distance is one type of statistical distance measure which is used to compute the distance from the point to the centre of a distribution. It is ideal to solve the outlier detection problem. The distance of a point P from probability distribution D is how far away standard deviation P is from the mean of probability distribution D. If the point P is at the mean of the probability distribution, the distance is zero (0).
Two points may seem to have same Euclidean distance but different Mahalanobis distance and hence are not similar. Look at the diagram given below.
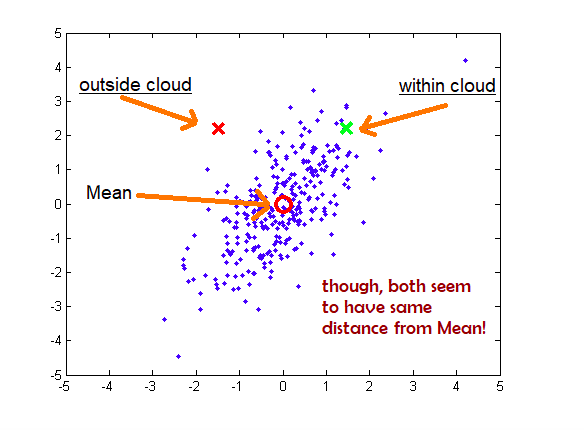
You may note that point X can be seen as an outlier in the data distribution shown in the above diagram although the Euclidean distance of red and green points is same from the mean.
Jaccard Distance
One another type of statistical measure is Jaccard Distance. It takes into consideration the intersection or overlap of attributes between two objects between which the distance needs to be found. For example, lets say there are two points represented by a set of attributes. If one or more attributes for one points match another, then they would be overlapping and therefore close in distance. If the points had diverging attributes they wouldn’t match. The following diagram represents the Jaccard distance formula:


Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me