In this post, you will learn about the concepts of training, validation, and test data sets used for training machine learning models. The post is most suitable for data science beginners or those who would like to get clarity and a good understanding of training, validation, and test data sets concepts. The following topics will be covered:
- Data split – training, validation, and test data set
- Different model performance based on different data splits
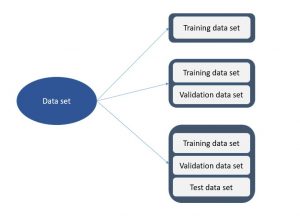
Data Splits – Training, Validation & Test Data Sets
You can split data into the following different sets and each data split configuration will have machine learning models having different performance:
- Training data set: When you use the entire data set for training the model, what you have is just the training data set. You train the model using the entire data set and test the model performance on the random data set taken from the entire training sample data set.
- Validation data set: When you split the data set into two splits where the one split is called a training data set and another split is called a validation data set. You train the model using the training data set and evaluate the model performance using the validation data set. Generally, the training and validation data set is split into an 80:20 ratio. Thus, 20% of the data is set aside for validation purposes. The ratio changes based on the size of the data. In case, the data size is very large, one also goes for a 90:10 data split ratio where the validation data set represents 10% of the data.
- Test data set: When you split the data set into three splits, what we get is the test data set. The three splits consist of training data set, validation data set and test data set. You train the model using the training data set and assess the model performance using the validation data set. You optimize the model performance using training and validation data set. Finally, you test the model generalization performance using the test data set. The test data set remains hidden during the model training and model performance evaluation stage. One can split the data into a 70:20:10 ratio. 10% of the data set can be set aside as test data for testing the model performance.
Model Performance based on different Data Splits
You get different model performances based on the different types of data split. The following diagram represents different data split configurations.
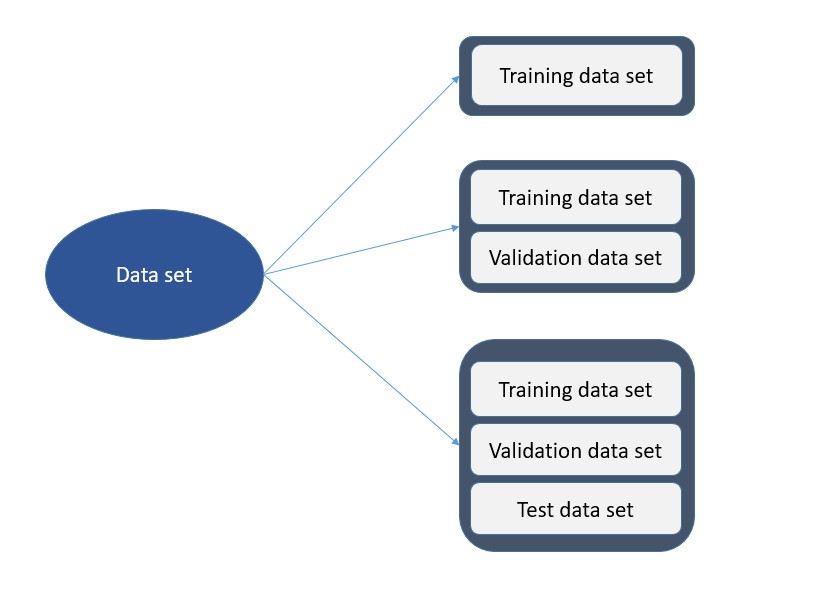
Lets understand the different aspects of model performance as following:
- Model built using just training data set: When the entire dataset is used for training the model, the model gets highly biased to the dataset. Such model most likely won’t be able to generalize on unseen data unless the dataset used for training represented the entire population. Such model overfits to the training dataset.
- Model built with training & validation data set: When the dataset is trained using training data set and evaluated on validation dataset, the model performs much better than the earlier model trained using entire dataset. However, when such models are trained for long time, these model get biased. Basically, the hyperparameters get changed appropriately in each iteration such that model performs better with validation data set. Thus, the validation dataset details get leaked into training dataset. This results in models getting biased.
- Model built with training, validation & test data set: In this case, there is third dataset split from the original dataset which is kept hidden from training and evaluation process. Such models have a greater likelihood of generalizing on unseen dataset than earlier two cases mentioned above.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Latest posts by Ajitesh Kumar (see all)
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me