Tag Archives: ai
Python – Extract Text from HTML using BeautifulSoup

In this post, you will learn about how to use Python BeautifulSoup and NLTK to extract words from HTML pages and perform text analysis such as frequency distribution. The example in this post is based on reading HTML pages directly from the website and performing text analysis. However, you could also download the web pages and then perform text analysis by loading pages from local storage. Python Code for Extracting Text from HTML Pages Here is the Python code for extracting text from HTML pages and perform text analysis. Pay attention to some of the following in the code given below: URLLib request is used to read the html page …
Python – Extract Text from PDF file using PDFMiner
In this post, you will get a quick code sample on how to use PDFMiner, a Python library, to extract text from PDF files and perform text analysis. I will be posting several other posts in relation to how to use other Python libraries for extracting text from PDF files. In this post, the following topic will get covered: How to set up PDFMiner Python code for extracting text from PDF file using PDFMiner Setting up PDFMiner Here is how you would set up PDFMiner.six. You could execute the following command to get set up with PDFMiner while working in Jupyter notebook: Python Code for Extracting Text from PDF file …
NLTK Hello World Python Example
In this post, you will learn about getting started with natural language processing (NLP) with NLTK (Natural Language Toolkit), a platform to work with human languages using Python language. The post is titled hello world because it helps you get started with NLTK while also learning some important aspects of processing language. In this post, the following will be covered: Install / Set up NLTK Common NLTK commands for language processing operations Install / Set up NLTK This is what you need to do set up NLTK. Make sure you have Python latest version set up as NLTK requires Python version 3.5, 3.6, 3.7, or 3.8 to be set up. In Jupyter notebook, you could execute …
Contract Management Use Cases for Machine Learning

This post briefly represent the contract management use cases which could be solved using machine learning / data science. These use cases can also be termed as predictive analytics use cases. This can be useful for procurement business functions in any manufacturing companies which require to procure raw materials from different suppliers across different geographic locations. The following are some of the examples of industry where these use cases and related machine learning techniques can be useful. Pharmaceutical Airlines Food Transport Key Analytics Questions One must understand the business value which could be created using predictive analytics use cases listed later in this post. One must remember that one must start with questions …
Difference – Artificial Intelligence & Machine Learning
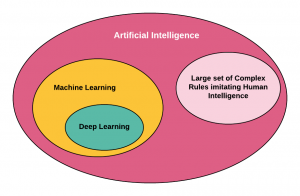
In this post, you learn the difference between artificial intelligence & machine learning. Artificial intelligence represents a set of computer programs that imitate human intelligence. The diagram below represents the key difference between AI and Machine Learning. Basically, machine learning is a part of AI landscape. One can do AI without doing machine learning or deep learning. Thus, an organization can claim that they have AI-based systems without having machine learning or deep learning based systems. All machine learning or deep learning based systems can be termed as AI systems. But, all AI systems may not be termed as machine learning systems. The following are key building blocks of an …
Infographics for Model & Algorithm Selection & Evaluation
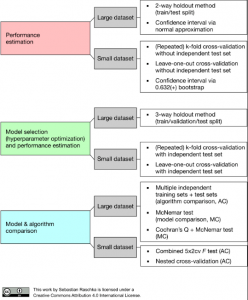
This is a short post created for quick reference on techniques which could be used for model evaluation & selection and model and algorithm comparision. This would be very helpful for those aspiring data scientists beginning to learn machine learning or those with advanced data science skills as well. The image has been taken from this blog, Comparing the performance of machine learning models and algorithms using statistical tests and nested cross-validation authored by Dr. Sebastian Raschka The above diagram provides prescription for what needs to be done in each of the following areas with small and large dataset. Very helpful, indeed. Model evaluation Model selection Model and algorithm comparison …
Logistic Regression: Sigmoid Function Python Code
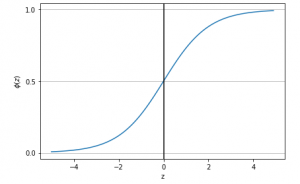
In this post, you will learn about the following: How to represent the probability that an event will take place with the asssociated features (attributes / independent features) Sigmoid function python code Probability as Sigmoid Function The below is the Logit Function code representing association between the probability that an event will occur and independent features. $$Logit Function = \log(\frac{P}{(1-P)}) = {w_0} + {w_1}{x_1} + {w_2}{x_2} + …. + {w_n}{x_n}$$ $$Logit Function = \log(\frac{P}{(1-P)}) = W^TX$$ $$P = \frac{1}{1 + e^-W^TX}$$ The above equation can be called as sigmoid function. Python Code for Sigmoid Function Executing the above code would result in the following plot: Pay attention to some of the …
Beta Distribution Example for Cricket Score Analysis

This post represents a real-world example of Binomial and Beta probability distribution from the sports field. In this post, you will learn about how the run scored by a Cricket player could be modeled using Binomial and Beta distribution. Ever wanted to predict the probability of Virat Kohli scoring a half-century in a particular match. This post will present a perspective on the same by using beta distribution to model the probability of runs that can be scored in a match. If you are a data scientist trying to understand beta and binomial distribution with a real-world example, this post will turn out to be helpful. First and foremost, let’s identify the random variable that we would like …
Pandas – How to Extract Month & Year from Datetime
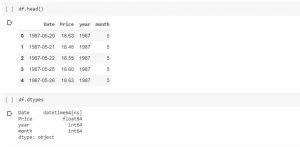
This is a quick post representing code sample related to how to extract month & year from datetime column of DataFrame in Pandas. The code sample is shown using the sample data, BrentOilPrices downloaded from this Kaggle data page. Here is the code to load the data frame. Check the data type of the data using the following code: The output looks like the following: Date object Price float64 dtype: object Use the following command to change the date data type from object to datetime and extract the month and year. Printing data using head command would print the following:
Pandas – How to Concatenate Dataframe Columns
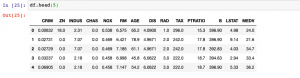
Quick code sample on how to concatenate the data frames columns. We will work with example of Boston dataset found with sklearn.datasets. One should note that data frames could be concatenated by rows and columns. In this post, you will learn about how to concatenate data frames by columns. Here is the code for working with Boston datasets. First and foremost, the Boston dataset will be loaded. Once loaded, let’s create different different data frames comprising of data and target variable. This above creates two data frames comprising of data (features) and the values of target variable. Here are the snapshots. Use the following command to concatenate the data frames. …
Difference between Machine Learning & Traditional Software
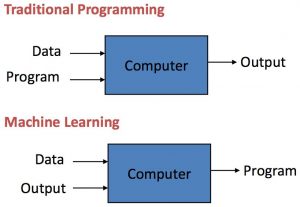
In this post, we will understand what are some of the key differences between machine learning models and traditional/conventional software. S.No Traditional Software Machine Learning 1 In traditional software, the primary objective is to meet functional and non-functional requirements. In machine learning models, the primary goal is to optimize the metric (accuracy, precision/recall, RMSE, etc) of the models. Every 0.1 % improvement in the model metrics could result in significant business value creation. 2 The quality of the software primary depends on the quality of the code. The quality of the model depends upon various parameters which are mainly related to the input data and hyperparameters tuning. 3 Traditional software …
Neural Network Architecture for Text-to-Speech Synthesis
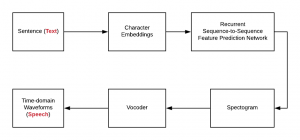
In this post, you would learn about a neural network reference solution architecture which could be used to convert the text to speech. The neural network solution architecture given in this post is based on deep learning (autoencoder network (encoder-decoder) with attention). Neural Network Reference Architecture for Text-to-Speech Synthesis In the solution architecture diagram (figure 1) depicted below, the following is described: Sentences are first converted into character embeddings. Character embeddings are numeric representations of words. Numeric representations of each of the words could be used to create numeric representations of higher-level representations like sentences/paragraphs/documents/etc. Character embeddings are next fed into recurrent sequence-to-sequence feature prediction network with attention. The sequence-to-sequence …
Reverse Image Search using Deep Learning (CNN)

In this post, you will learn about a solution approach for searching similar images out of numerous images matching an input image (query) using machine learning / deep learning technology. This is also called a reverse image search. The image search is generally searching for images based on keywords. Here are the key components of the solution for reverse image search: A database of storing images with associated numerical vector also called embeddings. A deep learning model based on convolutional neural network (CNN) for creating numerical feature vectors (aka embeddings) for images A module which searches embeddings of an input image (query) from the image database based on the nearest neighbor …
Why Data Scientists Must Learn Statistics?

In order to understand the need for data scientists to be very good at the statistical concepts, one needs to clearly understand some of the following: Who are data scientists? What is the need for statistics in data scientists’ day-to-day work? Who are Data Scientists? Data Scientists are the primarily Scientists who do experiments to find some of the following: Whether there exists a relationship between data Whether the function approximated (machine learning or statistical learning model) from a given sample of data could be generalized for the entire population In case there are multiple function approximations for predicting outcomes given a set of input, which one of the function approximation …
When not to use F-Statistics for Multi-linear Regression
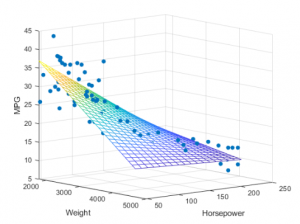
In this post, you will learn about the scenario in which you may NOT want to use F-Statistics for doing the hypothesis testing on whether there is a relationship between response and predictor variables in the multilinear regression model. Multilinear regression is a machine learning / statistical learning method which is used to predict the quantitative response variable and also understand/infer the relationship between the response and multiple predictor variables. We will look into the following topics: Background When not to use F-Statistics for Multilinear Regression Model Background F-statistics is used in hypothesis testing for determining whether there is a relationship between response and predictor variables in multilinear regression models. Let’s consider …
What, When & Why of Regularization in Machine Learning?
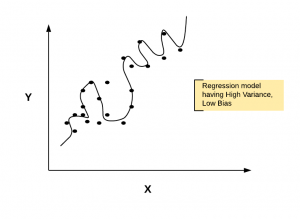
In this post, we will try and understand some of the following in relation to regularizing the regression machine learning models to achieve higher accuracy and stable models: Background What is regularization? Why & when does one need to adopt/apply the regularization technique? Background At times, when one is building a multi-linear regression model, one uses the least squares method for estimating the coefficients of determination or parameters for features. As a result, some of the following happens: Often, the regression model fails to generalize on unseen data. This could happen when the model tries to accommodate for all kind of changes in the data including those belonging to both …

I found it very helpful. However the differences are not too understandable for me