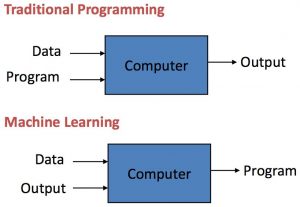
In this post, we will understand what are some of the key differences between machine learning models and traditional/conventional software.
| S.No | Traditional Software | Machine Learning |
| 1 | In traditional software, the primary objective is to meet functional and non-functional requirements. | In machine learning models, the primary goal is to optimize the metric (accuracy, precision/recall, RMSE, etc) of the models. Every 0.1 % improvement in the model metrics could result in significant business value creation. |
| 2 | The quality of the software primary depends on the quality of the code. | The quality of the model depends upon various parameters which are mainly related to the input data and hyperparameters tuning. |
| 3 | Traditional software is created using one software stack such as MEAN, Java, etc. | Machine learning models could be created using different algorithms and associated libraries. Each of these algorithms could result in different performance. |
Apart from the above, one of the key aspects of machine learning is that those working on machine learning models need to acquire the sensibilities of a scientist. This is because, with new data, one may require to retrain the model and aim to ensure the same or better performance. This is unlike traditional software development where the change in data does not change/impact the business functionality although new business rules may need to be accommodated.
Here is a great picture which represents the difference between machine learning models and traditional software

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Latest posts by Ajitesh Kumar (see all)
- Completion Model vs Chat Model: Python Examples - June 30, 2024
- LLM Hosting Strategy, Options & Cost: Examples - June 30, 2024
- Application Architecture for LLM Applications: Examples - June 25, 2024
Leave a Reply