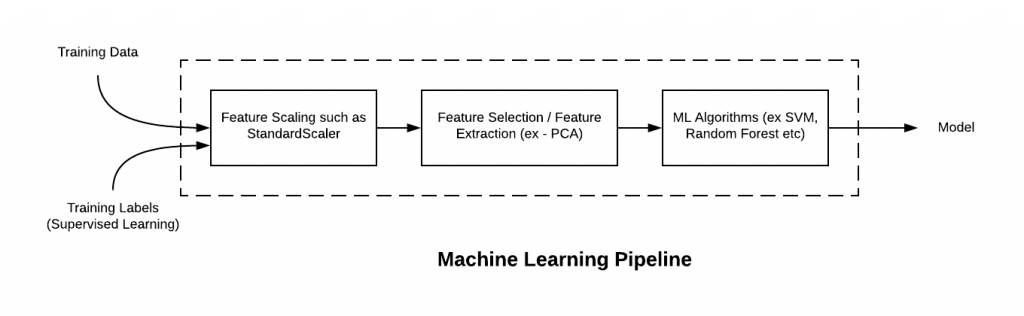
In this post, you will learning about concepts about machine learning (ML) pipeline and how to build ML pipeline using Python Sklearn Pipeline (sklearn.pipeline) package. Getting to know how to use Sklearn.pipeline effectively for training/testing machine learning models will help automate various different activities such as feature scaling, feature selection / extraction and training/testing the models. It is recommended for data scientists (Python) to get a good understanding of Sklearn.pipeline.
Introduction to Machine Learning Pipeline & Sklearn.pipeline
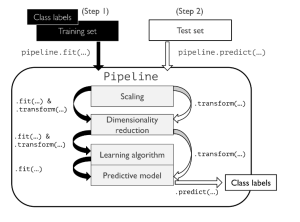
Machine Learning (ML) pipeline, theoretically, represents different steps including data transformation and prediction through which data passes. The outcome of the pipeline is the trained model which can be used for making the predictions. Sklearn.pipeline is a Python implementation of ML pipeline. Instead of going through the model fitting and data transformation steps for the training and test datasets separately, you can use Sklearn.pipeline to automate these steps. Here is a diagram representing a pipeline for training a machine learning model based on supervised learning. Make the note of some of the following in relation to Sklearn implementation of pipeline:
- Every step except the last one takes a set of SKlearn transformers for different purposes including feature scaling, feature selection, feature extraction etc. In the diagram given below, these transformers are represented using StandardScaler (feature scaling) and PCA (unsupervised feature extraction / dimensionality reduction). The StandardScaler class is used for feature scaling. This class helps to improve the accuracy of machine learning algorithms by standardizing the features in the data set. It adjusts the values of the features so that they are all within a certain range. The range is determined by the user, and it can be any value from 0 to 1. When the features are scaled, they are all adjusted so that they have a mean of 0 and a standard deviation of 1. The transformers for StandardScaler & PCA implements the following methods for the pipeline to work:
- Fit
- Transform
- Last step is an Sklearn estimator which is used for making the predictions. In the diagram given below, the estimator is represented using ML algorithm implementations such as SVC, RandomForestClassifier etc. The last step representing estimator must implement the following methods:
- Fit
- Predict
- For supervised learning, input is training data and labels and the output is model.
- Invoking fit method on pipeline instance will result in execution of pipeline for training data. This is illustrated in the code example in next section.
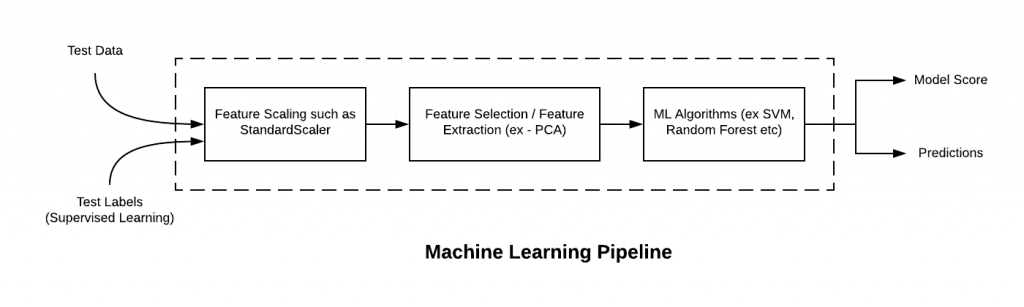
Here is how the above pipeline will look like, for test data. Pay attention to some of the following in the diagram given below:
- Input can be test data and labels
- Output can be either predictions or model performance score.
- Transform method is invoked on test data in data transformation stages.
- Methods such as score or predict is invoked on pipeline instance to get predictions or model score.
Sklearn ML Pipeline Python Code Example
Here is the Python code example for creating Sklearn Pipeline, fitting the pipeline and using the pipeline for prediction. The following are some of the points covered in the code below:
- Pipeline is instantiated by passing different components/steps of pipeline related to feature scaling, feature extraction and estimator for prediction. The last step must be algorithm which will be doing prediction. Here is the set of sequential activities along with final estimator (used for prediction)
- StandardScaler for feature scaling
- PCA for unsupervised feature extraction
- RandomForestClassifier for prediction
- Fit is invoked on the pipeline instance to perform sequential transformation activities such as the following activities:
- Data transformation using transformers for feature scaling, dimensionality reduction etc. Transformers must implement fit and transform method.
- Estimators is used to fit a model. Estimators must implement fit and predict method.
- Predict or Score method is called on pipeline instance to making prediction on the test data or scoring the model performance respectively.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases'
'/breast-cancer-wisconsin/wdbc.data', header=None)
#
# Encode the label using LabelEncoder
#
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
#
# Create training and test data
#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=1)
#
#v Create a pipeline and fit the model
#
pipe_lr = make_pipeline(StandardScaler(),
PCA(n_components=2),
RandomForestClassifier(criterion='gini', n_estimators=50, max_depth=5, random_state=1))
pipe_lr.fit(X_train, y_train)
y_pred = pipe_lr.predict(X_test)
test_acc = pipe_lr.score(X_test, y_test)
print(f'Test accuracy: {test_acc:.3f}')
The diagram below represents how the pipeline works:
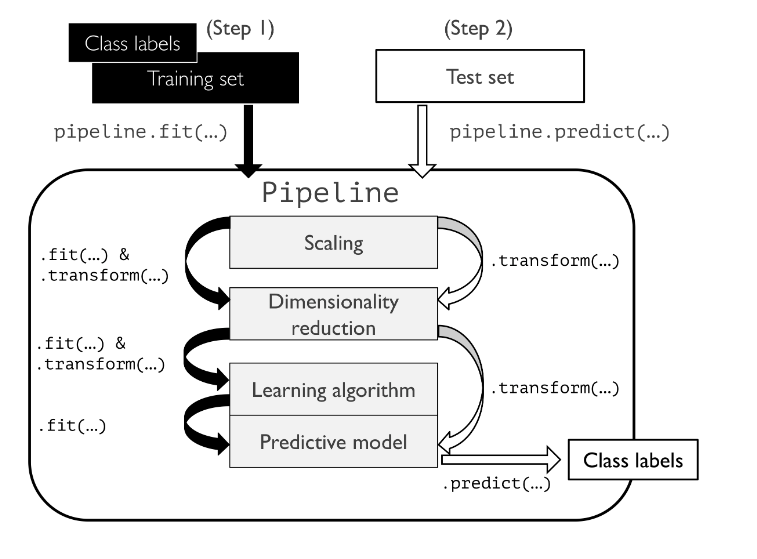
Note how different steps are implemented using the pipeline. The above steps are passed as arguments in make_pipeline method.
Conclusions
Here is the summary of what you learned:
- Use machine learning pipeline (sklearn implementations) to automate most of the data transformation and estimation tasks.
- make_pipeline class of Sklearn.pipeline can be used to creating the pipeline.
- Data transformers must implement fit and transform method
- Estimator must implement fit and predict method.
- Pipeline fit method is invoked to fit the model using training data.
- Pipeline predict or score method is invoked to get predictions or determining model performance scores.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me