Last updated: 8th Dec, 2023
In this post, you will learn about the key differences between the AdaBoost and the Random Forest machine learning algorithm. Random Forest and AdaBoost algorithms can be used for both regression and classification problems. Both the algorithms are ensemble learning algorithms that construct a collection of trees for prediction. Random Forest builds multiple decision trees using diverse variables and employs bagging for data sampling and predictions. AdaBoost, on the other hand, creates an ensemble of weak learners, often in the form of decision stumps (simple trees with one node and two leaves). AdaBoost iteratively adjusts these stumps to concentrate on mispredicted areas, often leading to higher accuracy than Random Forest but with a greater risk of overfitting. Here are different posts on Random forest and AdaBoost demonstrating how you could build classification models using Random Forest and Adaboost with Sklearn Python programming.
Models trained using both Random forest and AdaBoost classifier make predictions that generalize better with a larger population. The models trained using both algorithms are less susceptible to overfitting / high variance.
Differences between AdaBoost vs Random Forest
Here are the key differences between AdaBoost and the Random Forest algorithm:
- Data sampling: Both Random forest and Adaboost involve data sampling, but they differ in terms of how the samples are used. In Random forest, the training data is sampled based on the bagging technique. Read more details on this blog – Decoding Bagging in Random Forest: Examples.In AdaBoost, each new weak learner, typically a decision stump (a simple tree with one node and two leaves), is trained on data with varying focus. The training data misclassified by a previous stump gets higher weights, making these challenging samples a priority in subsequent training. This reweighting process makes the next stump focus more on correcting these errors, enhancing the algorithm’s ability to adapt and improve by targeting its efforts on previous mistakes.
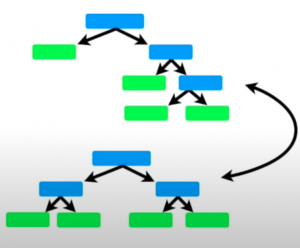
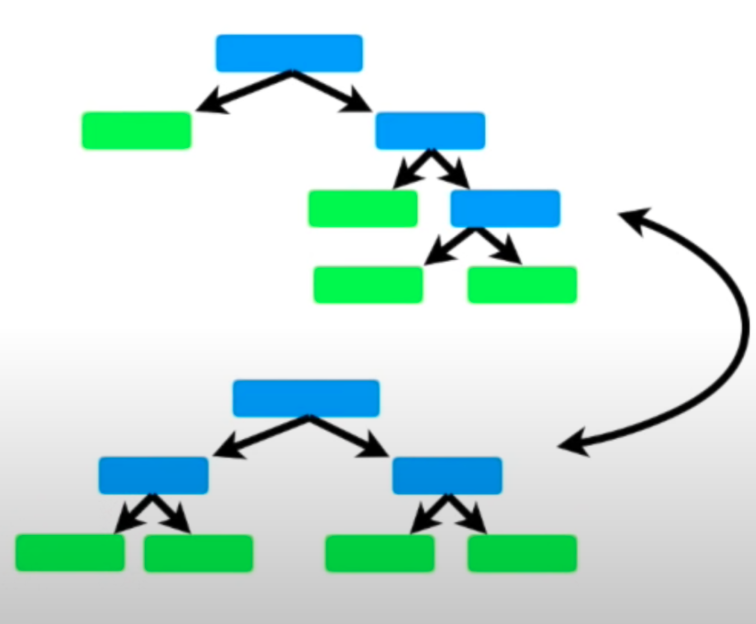
- Decision Trees vs Decision Stumps: Random Forest employs numerous decision trees, which can be full-sized or vary in depth. These trees use multiple variables for classifying data points. In contrast, AdaBoost utilizes decision stumps, which are simplified trees with only one node and two leaves. Each stump in AdaBoost is based on a single variable or feature, differing from Random Forest where trees use multiple variables for classification. Below are diagrams illustrating decision trees in Random Forest compared to decision stumps in AdaBoost.
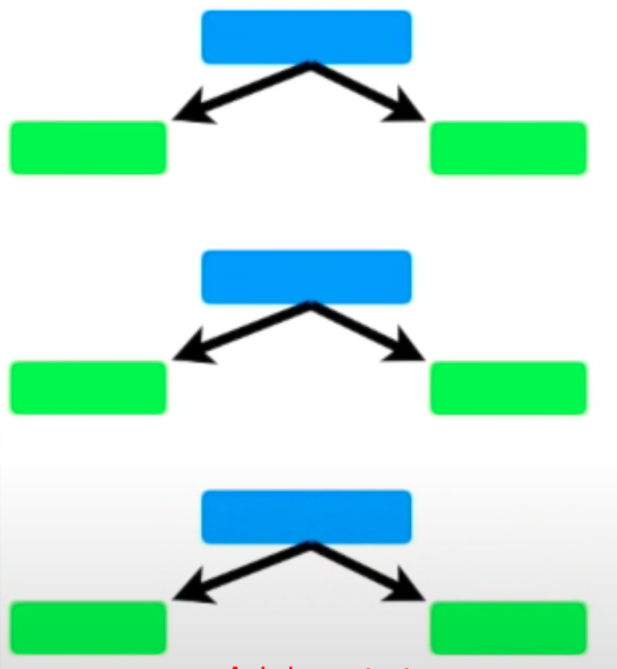
- Equal Weights vs Variable Weights: This is how the predictions are made for Adaboost vs Random Forest:
- In a Random Forest, each decision tree contributes equally to the final decision. The algorithm creates a ‘forest’ of decision trees, each trained on a random subset of the data. When making predictions, the Random Forest aggregates the predictions from all the trees, typically using a majority voting system. Each tree’s vote carries equal weight, regardless of its individual performance or accuracy.
- In contrast, AdaBoost assigns different weights to the decision stumps (simple one-node decision trees) based on their accuracy. In AdaBoost, decision stumps are added sequentially, and after each round, the algorithm increases the weight of the training samples that were misclassified. This, in turn, affects the training of the next stump. More accurate stumps are given more weight in the final decision-making process. Hence, some decision stumps may indeed have a higher say or influence on the final decision than others.
- Tree order:
- In a Random forest, each decision tree is made independently of other trees. The ordering in which decision trees are created is not important at all.
- However, in the forest of stumps made in AdaBoost, the ordering in which decision stumps are created is important. The errors made in the first decision stump influence how the second decision stump is made and the error made in the second stump influences how the third decision stump is made.
- Handling Overfitting:
- Random Forest is generally more robust against overfitting. This is because it uses the technique of bagging (Bootstrap Aggregating), where each decision tree is trained on a different subset of the data. This randomness helps in reducing overfitting.
- AdaBoost, while effective in improving the performance of the model, can be more prone to overfitting, especially when the data is noisy. AdaBoost focuses on correcting misclassified instances, which can lead to over-emphasizing outliers or noise in the data.
- Model Complexity:
- Random Forest can create very complex models, as it uses full decision trees which can have many nodes and leaves. This complexity can capture a wide variety of patterns in the data.
- AdaBoost typically uses decision stumps, which are very simple models. The complexity in AdaBoost comes from combining many such simple models.
- Flexibility with Different Types of Data:
- Random Forest is quite versatile and performs well with both categorical and numerical data. It’s also good for handling missing values and does not require feature scaling.
- AdaBoost can be sensitive to noisy data and outliers. It might require careful preprocessing of data, like handling missing values and feature scaling, to perform optimally.
- Training Speed and Computational Efficiency:
- Random Forest can be faster to train, as its trees can be built in parallel. This makes it computationally efficient, especially when dealing with large datasets.
- AdaBoost, on the other hand, builds its decision stumps sequentially, which can be slower. Each stump is influenced by the performance of the previous stump, so they cannot be constructed in parallel.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me