
Last updated: 11th Dec, 2023
In machine learning, there are a few different tree-based algorithms that can be used for both regression and classification tasks. Two of the most popular are decision trees and random forest. A decision tree is a basic machine learning model, resembling a flowchart. Random Forest, an advanced technique, combines multiple decision trees to enhance accuracy and reduce overfitting, using averaging or voting for final predictions. Essentially, Random Forest is a collection of decision trees working together. Both of these algorithms have their similarities and differences, and in this blog post, we’ll take a look at the key differences between them.
What’s Decision Tree Algorithm? How does it work?
The decision tree machine learning algorithm functions by segmenting the dataset into progressively smaller and more homogeneous subsets, a process known as splitting. This is guided by decision criteria that assess the split’s quality, typically based on measures such as data purity or entropy. Data purity refers to the homogeneity of a group with respect to the target variable, while entropy measures disorder or uncertainty in the data.
During each step, the algorithm selects the best split by evaluating how well it separates the data. For classification tasks, a common measure of purity is the Gini impurity or information gain, which quantifies the likelihood of incorrect labeling if it was done randomly according to the label distribution in the subset. In regression tasks, variance reduction is often the criterion.
The goal is to create subsets that are as pure as possible, meaning each subset should ideally contain data points that belong to the same class or have similar values for the target variable. This splitting continues recursively on each derived subset until reaching a stopping condition, such as maximum tree depth, minimum number of samples in a node, or no further improvement in purity. The resulting structure is a tree where each node represents a decision point, and the leaves represent the final predictions or outcomes.
This is how a sample decision tree would look like:
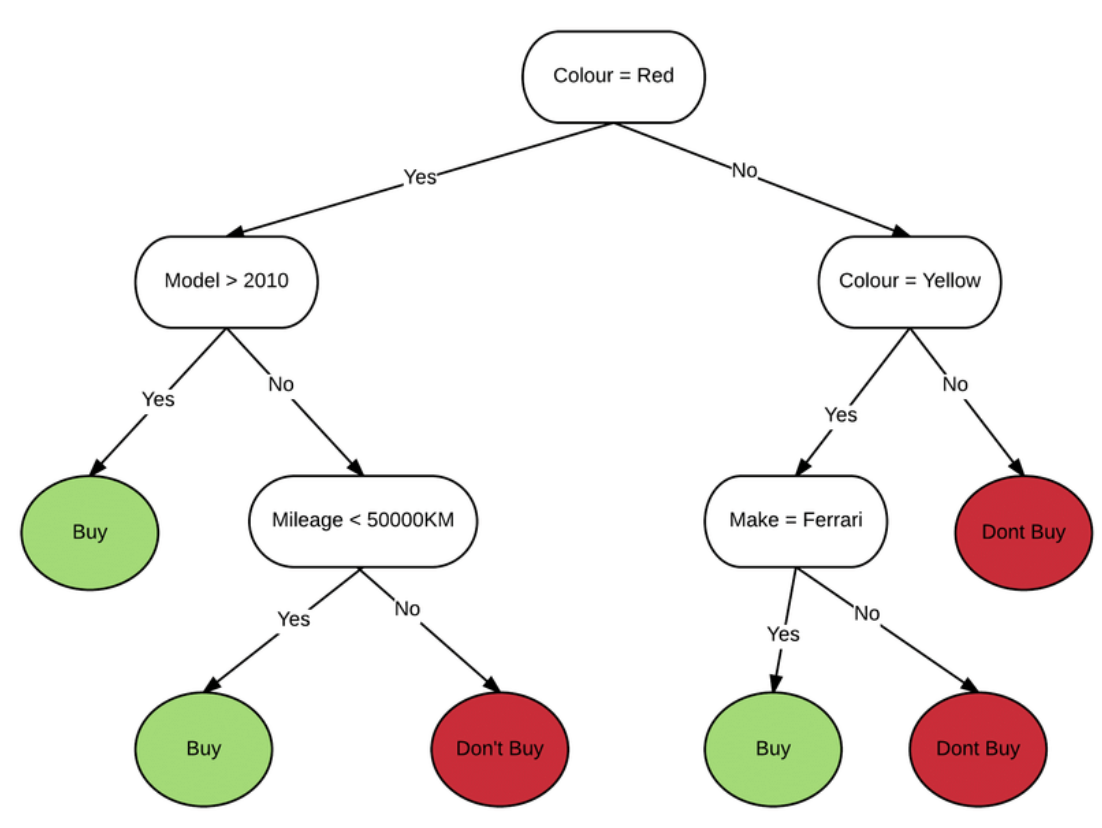
Learn more about decision tree in this post – Decision trees concepts and examples.
The following are some of the key aspects of decision tree:
- Feature Importance: It identifies crucial variables and their interrelations, aiding in feature selection.
- Pruning: To avoid overfitting, parts of the tree that contribute minimally to predictions are pruned.
- Handling Missing Values: Decision trees can manage missing data values effectively.
- Non-Linear Relationships: They capture complex, non-linear relationships between features and labels.
- Limitations: However, decision trees can overfit training data and are sensitive to data changes, affecting their structure.
What’s Random Forest Algorithm? How does it work?
Random Forest is a machine learning algorithm widely used for both regression and classification tasks. It’s an ensemble method, meaning it combines the predictions of multiple decision trees to improve accuracy. The core technique behind Random Forest is bagging, or Bootstrap Aggregating, which involves training each tree on a random subset of the data with a random selection of features. This approach has several key advantages and characteristics:
- Versatility: Suitable for both regression and classification problems, handling numerical and categorical data.
- Reduction in Overfitting: The ensemble approach, averaging predictions from various trees, decreases the likelihood of overfitting.
- Improved Accuracy: By combining multiple trees, Random Forest generally achieves higher accuracy than individual decision trees.
- Robustness to Outliers and Noise: The algorithm is less sensitive to outliers and noise due to its aggregation method.
- Efficiency in Training: Each tree is trained on a subset of the data, enhancing computational efficiency.
- Handling of Variance and Bias: Bagging helps in reducing the variance of predictions, providing more stable and reliable results.
- Decision Making Process: For classification, it uses majority voting; for regression, it averages the predictions.
- Feature Importance: Offers insights into the importance of different features for the prediction task.
- Limitations: It can be computationally intensive and offers lower interpretability compared to single decision trees.
This is how a sample random forest would look like:
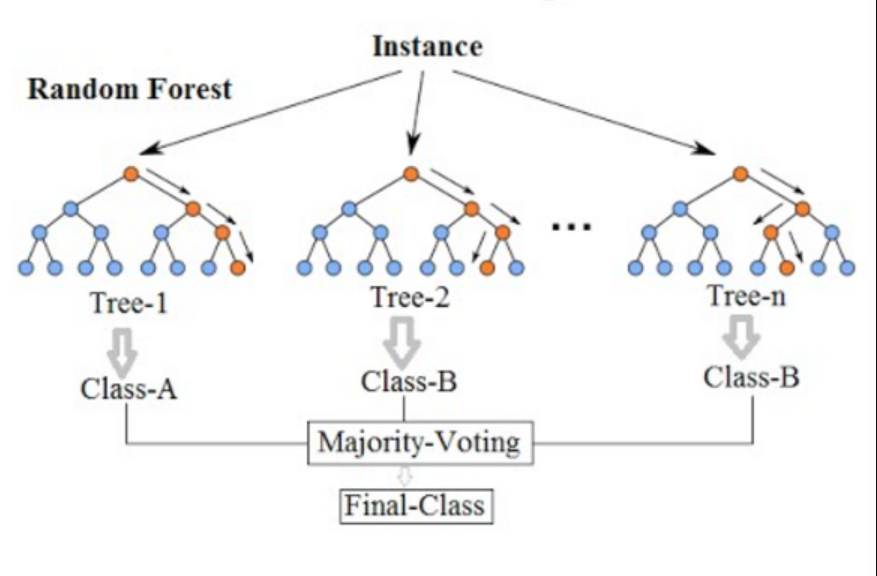
Learn more about random forest in this post: Random forest classifier python example
Key differences between decision tree and random forest
Random forest and decision tree are two popular methods used in machine learning. Both methods can be used for classification and regression tasks, but there are some key differences between them. Here is the list:
| Aspect | Decision Tree | Random Forest |
|---|---|---|
| Type of Model | Single model | Ensemble learning method comprising multiple decision trees |
| Prediction Method | Based on a series of if-then rules | Averages or takes the majority vote from multiple tree predictions |
| Objective Function | Utilizes a greedy algorithm for locally optimal solutions | Aims for a globally optimal solution by training trees on data subsets |
| Overfitting Tendency | Higher risk of overfitting, especially if not properly tuned | Lower risk of overfitting due to averaging across multiple trees |
| Accuracy | Generally less accurate, more prone to errors due to bias or variance | Generally more accurate, better at handling bias and variance |
| Computational Efficiency | Faster and less resource-intensive to train | More computationally expensive due to multiple models |
| Handling Missing Values | Typically relies on imputation, struggles with missing data | More robust to missing data, can handle it via bootstrapping |
| Flexibility | Less flexible, limited by the structure of the tree | More flexible due to the combination of multiple trees |
| Primary Focus in Model Learning | Minimizes entropy to create pure nodes | Strives to minimize variance across multiple trees |
| Robustness | Less robust, especially to variations in data | More robust due to diverse data representation in multiple trees |
| Ease of Interpretation | Easier to interpret and visualize due to simplicity | More complex, harder to interpret due to ensemble nature |
| Scalability | Scalable but may not handle large datasets effectively | Better scalability, suitable for large and complex datasets |
| Model Tuning | Requires careful tuning to prevent overfitting | Requires tuning for the number of trees and depth, among others |
| Use in Practice | Suitable for simpler tasks or when interpretability is key | Preferred for more complex tasks requiring higher accuracy |
Ultimately, the choice of model depends on the specific task and the available resources
Python Example for Training Decision Tree Model
Here’s a Python code example that demonstrates the use of a decision tree classifier on the breast cancer dataset. In this example, the breast cancer dataset is first loaded and split into training and testing sets. A decision tree classifier is then instantiated and trained on the training data. After predicting on the test set, the accuracy of the model is calculated, which in this case is approximately 94.74%. This indicates a high level of performance in classifying the breast cancer data using a decision tree
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # Load the breast cancer dataset data = load_breast_cancer() X = data.data y = data.target # Split the dataset into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Create a Decision Tree Classifier clf = DecisionTreeClassifier(random_state=42) # Train the classifier clf.fit(X_train, y_train) # Predict on the test set y_pred = clf.predict(X_test) # Calculate accuracy accuracy = accuracy_score(y_test, y_pred) print( "Accuracy: ", accuracy)
Python Example for Training Random Forest Model
Here is the Python code example for training a random forest classifier model using the same dataset:
from sklearn.ensemble import RandomForestClassifier # Create a Random Forest Classifier rf_clf = RandomForestClassifier(random_state=42) # Train the classifier rf_clf.fit(X_train, y_train) # Predict on the test set y_pred_rf = rf_clf.predict(X_test) # Calculate accuracy accuracy_rf = accuracy_score(y_test, y_pred_rf) accuracy_rf
Conclusion
Both decision trees and random forests are powerful machine learning algorithms that can be used for both regression and classification tasks. However, there are some key differences between them. Decision trees tend to overfit the training data, while random forests are much more resistant to overfitting. Additionally, decision trees require less data preprocessing than random forests, and they’re also easier to interpret because you can visualize the entire tree.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me