In this blog post, we will tune the hyperparameters of a Decision Tree Classifier using Grid Search. In machine learning, hyperparameter tuning is the process of optimizing a model’s hyperparameters to improve its performance on a given dataset. Hyperparameters are the parameters that control the model’s architecture and therefore have a direct impact on its performance. In machine learning, the performance of a model is greatly dependent on the hyperparameters used. Therefore, it is important to tune the hyperparameters so that the model can learn and generalize well on unseen data. There are many different methods for hyperparameter tuning, but in this blog post, we will focus on grid search. Grid search is a method of systematically working through a range of hyperparameter values in order to find the ones that result in the best performance for our model. In other words, we define a “grid” of hyperparameter values and then train and evaluate our model for each value combination.
Decision Tree Grid Search Python Example
Before getting into hyperparameter tuning of Decision tree classifier model using GridSearchCV, lets quickly understand what is decision tree.
Decision tree algorithms are a type of machine learning algorithm that can be used for both regression and classification tasks. Decision trees models are powerful models that are easy to interpret and explain, which makes them popular for use in data mining and predictive modeling. Decision tree algorithms work by constructing a tree-like structure, where each node represents a decision point and each branch represents a possible outcome. The algorithm then processes new data points by making predictions based on the decision tree structure. Decision trees are easy to interpret and can be used to make predictions on new data points. However, they are also prone to overfitting, especially when the data is noisy or has many features. One way to combat overfitting is to use a decision tree as part of a ensemble learning model, such as a random forest.
To understand how grid search works with decision trees classifier, let’s take a look at an example. Say we want to tune the decision tree hyperparameters max_depth and min_samples_leaf for the Iris dataset. Max_depth is the maximum depth of the tree and min_somples_leaf is the minimum number of samples required to be at a leaf node. We would first define a grid of values to search over as follows:
max_depth = [3, 5, 7]
min_samples_leaf = [1, 2, 3]
We will use Sklearn DecisionTreeClassifier to train the model. The Iris dataset is a classification dataset consisting of 150 observations of iris flowers. There are three species of iris in the dataset, and each observation has four features: sepal length, sepal width, petal length, and petal width. The goal is to build a classification model that can accurately predict the species of an iris given its measurements.
</p>
<p>
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
#
# Load the IRIS dataset
#
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
#
# Create an instance of decision tree classifier
#
clf = DecisionTreeClassifier(random_state=123)
#
# Create grid parameters for hyperparameter tuning
#
params = {
'min_samples_leaf': [1, 2, 3],
'max_depth': [1, 2, 3]
}
#
# Create gridsearch instance
#
grid = GridSearchCV(estimator=clf,
param_grid=params,
cv=10,
n_jobs=1,
verbose=2)
#
# Fit the model
#
grid.fit(X_train, y_train)
#
# Assess the score
#
grid.best_score_, grid.best_params_
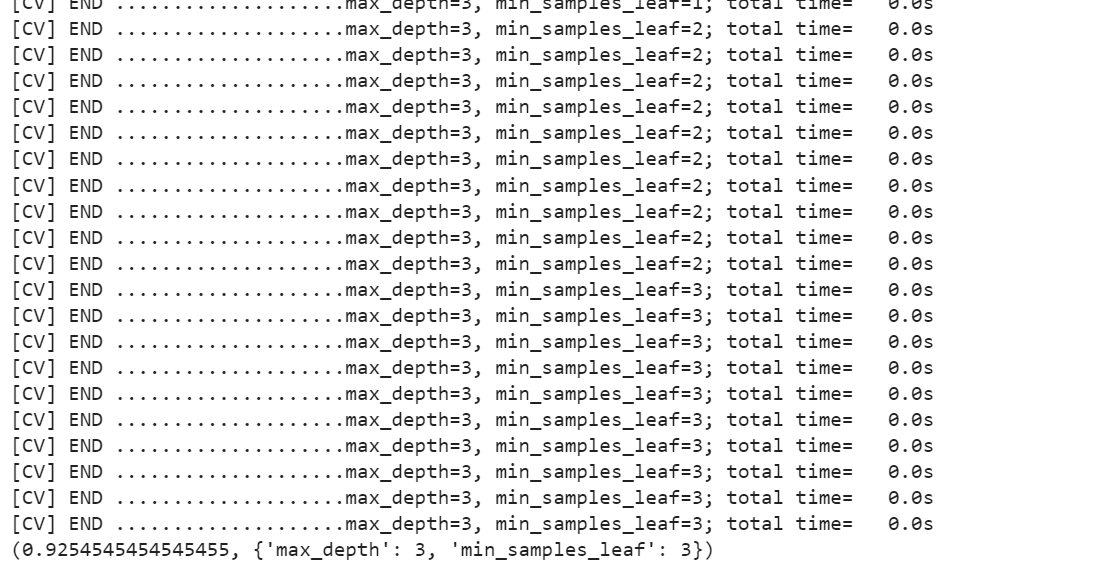
The output prints out grid search across different values of hyperparameters, the model score with best hyperparameters and the most optimal hyperparameters value.
In the above code, the decision tree model is train and evaluate our for each value combination and choose the combination that results in the best performance. In this case, “best performance” could be defined as either accuracy or AUC (area under the curve). Once we’ve found the best performing combination of hyperparameters, we can then train our final model using those values and deploy it to production.
Conclusion
In this blog post, we explored how to use grid search to tune the hyperparameters of a Decision Tree Classifier. We saw that by systematically trying different combinations of parameters using Grid Search, we can identify the set of values that results in the best performing model. Grid search is a powerful method for hyperparameter tuning that can help us improve the performance of our machine learning models. This approach can be extended to other types of models and other sets of hyperparameters.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me