Category Archives: AI
Online AI News from Top Global Universities – List

In this post, you will get an access to a list of web pages representing latest news related to artificial intelligence from top universities across the globe. This page will be updated from time-to-time for including new pages from different universities across the globe. These URLs will be very useful for those machine learning / data science enthusiasts who want to keep tab on current news and events in the field of artificial intelligence. MIT Stanford Stanford university – Human-centered AI (HAI) Stanford university – Center for AI in medicine and imaging Stanford AI research and ideas Harvard university JHU Malone center for Engg. in healthcare Yale university Princeton university …
MOSAIKS for creating Climate Change Models
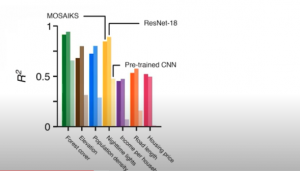
In this post, you will learn about the framework, MOSAIKS (Multi-Task Observation using Satellite Imagery & Kitchen Sinks) which can be used to create machine learning linear regression models for climate change. Here is the list of few prediction use cases which has already been tested with MOSAIKS and found to have high model performance: Forest cover Elevation Population density Nighttime lights Income Road length Housing price Crop yields Poverty mapping What is MOSAIKS? MOSAIKS provides a set of features created from Satellite imagery dataset. We are talking about 90TB of data gathered per day from 700+ satellites. These features can be combined with machine learning algorithms to address global …
Top 10+ Youtube AI / Machine Learning Courses

In this post, you get access to top Youtube free AI/machine learning courses. The courses are suitable for data scientists at all levels and cover the following areas of machine learning: Machine learning Deep learning Natural language processing (NLP) Reinforcement learning Here are the details of the free machine learning / deep learning Youtube courses. S.No Title Description Type 1 CS229: Machine Learning (Stanford) Machine learning lectures by Andrew NG; In case you are a beginner, these lectures are highly recommended Machine learning 2 Applied machine learning (Cornell Tech CS 5787) Covers all of the most important ML algorithms and how to apply them in practice. Includes 3 full lectures …
Deep Learning – Top 5 Online Jupyter Notebooks Servers

In this post, you will get information regarding the online Jupyter notebooks platform (GPU-based) which you can use to get started with both, machine learning and deep learning. The list consists of both freely available and paid options of online Jupyter notebook available with GPUs. When starting with GPUs, it is recommended to use rented options available online rather than buying your own GPU servers. There are online GPU Linux servers available (free and paid options) that can be used to train deep learning & machine learning models. I will be writing about it in my next post. Here is the list of Jupyter notebook platforms that could be used …
Top Deep Learning Myths You should know

This post highlights the top deep learning myths you should know. This is important to understand in order to leverage deep learning to solve complex AI problems. Many times, beginner to intermediate level machine learning enthusiasts don’t consider deep learning based on the myths discussed in this post. Without further ado, let’s look at the topmost and most common deep learning myths: Good understanding of complex mathematical concepts: Well, that is just a myth. At times, they say that one needs to have a higher degree in Mathematics & statistics. That is not true. With tools and programming languages along with libraries available today, basic mathematical concepts should be able …
Precision & Recall Explained using Covid-19 Example
In this post, you will learn about the concepts of precision, recall, and accuracy when dealing with the machine learning classification model. Given that this is Covid-19 age, the idea is to explain these concepts in terms of a machine learning classification model predicting whether the patient is Corona positive or not based on the symptoms and other details. The following model performance concepts will be described with the help of examples. What is the model precision? What is the model recall? What is the model accuracy? What is the model confusion matrix? Which metrics to use – Precision or Recall? Before getting into learning the concepts, let’s look at the data (hypothetical) derived out …
Predictive vs Prescriptive Analytics Difference
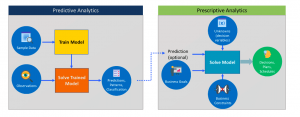
In this post, you will quickly learn about the difference between predictive analytics and prescriptive analytics. As data analytics stakeholders, one must get a good understanding of these concepts in order to decide when to apply predictive and when to make use of prescriptive analytics in analytics solutions / applications. Without further ado, let’s get straight to the diagram. In the above diagram, you could observe / learn the following: Predictive analytics: In predictive analytics, the model is trained using historical / past data based on supervised, unsupervised, reinforcement learning algorithms. Once trained, the new data / observation is input to the trained model. The output of the model is prediction in form …
NLTK – How to Read & Process Text File
In this post, you will learn about the how to read one or more text files using NLTK and process words contained in the text file. As data scientists starting to work on NLP, the Python code sample for reading multiple text files from local storage will be very helpful. Python Code Sample for Reading Text File using NLTK Here is the Python code sample for reading one or more text files. Pay attention to some of the following aspects: Class nltk.corpus.PlaintextCorpusReader reader is used for reading the text file. The constructor takes input parameter such as corpus root and the regular expression representing the files. List of files that are read could be found using method such as fileids List …
Python – Extract Text from HTML using BeautifulSoup

In this post, you will learn about how to use Python BeautifulSoup and NLTK to extract words from HTML pages and perform text analysis such as frequency distribution. The example in this post is based on reading HTML pages directly from the website and performing text analysis. However, you could also download the web pages and then perform text analysis by loading pages from local storage. Python Code for Extracting Text from HTML Pages Here is the Python code for extracting text from HTML pages and perform text analysis. Pay attention to some of the following in the code given below: URLLib request is used to read the html page …
Top 10 Data Science Skills for Product Managers

In this post, you will learn about some of the top data science skills / concepts which may be required for product managers / business analyst to have, in order to create useful machine learning based solutions. Here are some of the topics / concepts which need to be understood well by product managers / business analysts in order to tackle day-to-day challenges while working with data science / machine learning teams. Knowing these concepts will help product managers / business analyst acquire enough skills in order to solve machine learning based problems. Understanding the difference between AI, machine learning, data science, deep learning Which problems are machine learning problems? …
Python – Extract Text from PDF file using PDFMiner
In this post, you will get a quick code sample on how to use PDFMiner, a Python library, to extract text from PDF files and perform text analysis. I will be posting several other posts in relation to how to use other Python libraries for extracting text from PDF files. In this post, the following topic will get covered: How to set up PDFMiner Python code for extracting text from PDF file using PDFMiner Setting up PDFMiner Here is how you would set up PDFMiner.six. You could execute the following command to get set up with PDFMiner while working in Jupyter notebook: Python Code for Extracting Text from PDF file …
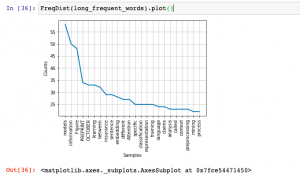
NLTK Hello World Python Example
In this post, you will learn about getting started with natural language processing (NLP) with NLTK (Natural Language Toolkit), a platform to work with human languages using Python language. The post is titled hello world because it helps you get started with NLTK while also learning some important aspects of processing language. In this post, the following will be covered: Install / Set up NLTK Common NLTK commands for language processing operations Install / Set up NLTK This is what you need to do set up NLTK. Make sure you have Python latest version set up as NLTK requires Python version 3.5, 3.6, 3.7, or 3.8 to be set up. In Jupyter notebook, you could execute …
Decision Tree Classifier Python Code Example
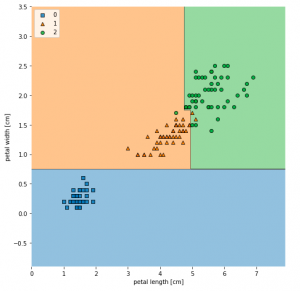
In this post, you will learn about how to train a decision tree classifier machine learning model using Python. The following points will be covered in this post: What is decision tree? Decision tree python code sample What is Decision Tree? Simply speaking, the decision tree algorithm breaks the data points into decision nodes resulting in a tree structure. The decision nodes represent the question based on which the data is split further into two or more child nodes. The tree is created until the data points at a specific child node is pure (all data belongs to one class). The criteria for creating the most optimal decision questions is …
Machine Learning – SVM Kernel Trick Example
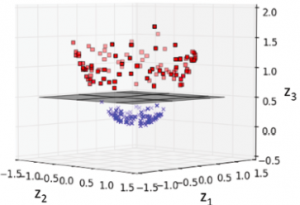
In this post, you will learn about what are kernel methods, kernel trick, and kernel functions when referred with a Support Vector Machine (SVM) algorithm. A good understanding of kernel functions in relation to the SVM machine learning (ML) algorithm will help you build/train the most optimal ML model by using the appropriate kernel functions. There are out-of-box kernel functions such as some of the following which can be applied for training models using the SVM algorithm: Polynomial kernel Gaussian kernel Radial basis function (RBF) kernel Sigmoid kernel The following topics will be covered: Background – Why Kernel concept? What is a kernel method? What is the kernel trick? What are …
Sklearn SVM Classifier using LibSVM – Code Example
In this post, you learn about Sklearn LibSVM implementation used for training an SVM classifier, with code example. Here is a great guide for learning SVM classification, especially, for beginners in the field of data science/machine learning. LIBSVM is a library for Support Vector Machines (SVM) which provides an implementation for the following: C-SVC (Support Vector Classification) nu-SVC epsilon-SVR (Support Vector Regression) nu-SVR Distribution estimation (one-class SVM) In this post, you will see code examples in relation to C-SVC, and nu-SVC LIBSVM implementations. I will follow up with code examples for SVR and distribution estimation in future posts. Here are the links to their SKLearn pages for C-SVC and nu-SVC …
SVM – Understanding C Value with Code Examples
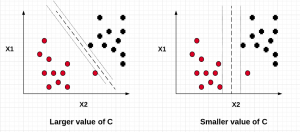
In this post, we will understand the importance of C value on the SVM soft margin classifier overall accuracy using code samples. In the previous post titled as SVM as Soft Margin Classifier and C Value, the concepts around SVM soft margin classifier and the importance of C value was explained. If you are not sure about the concepts, I would recommend reading earlier article. Lets take a look at the code used for building SVM soft margin classifier with C value. The code example uses the SKLearn IRIS dataset In the above code example, take a note of the value of C = 0.01. The model accuracy came out to …
I found it very helpful. However the differences are not too understandable for me