In this post, you will learn about what are kernel methods, kernel trick, and kernel functions when referred with a Support Vector Machine (SVM) algorithm. A good understanding of kernel functions in relation to the SVM machine learning (ML) algorithm will help you build/train the most optimal ML model by using the appropriate kernel functions. There are out-of-box kernel functions such as some of the following which can be applied for training models using the SVM algorithm:
- Polynomial kernel
- Gaussian kernel
- Radial basis function (RBF) kernel
- Sigmoid kernel
The following topics will be covered:
- Background – Why Kernel concept?
- What is a kernel method?
- What is the kernel trick?
- What are the kernel functions and its different types?
- Code example with linear kernel
Background – Why Kernel Concept?
Non-linear data set are difficult to be separated using a linear hyperplane. SVM algorithm is related to finding the hyperplane which separates the data based on maximum margin. Thus, the ask is the following:
Is there a way in which a non-linear data set or data set which is linearly inseparable can be represented in another form such that the data becomes linearly separable.
Take a look at the following data set which is linearly inseparable. This is plotted using IRIS data set.
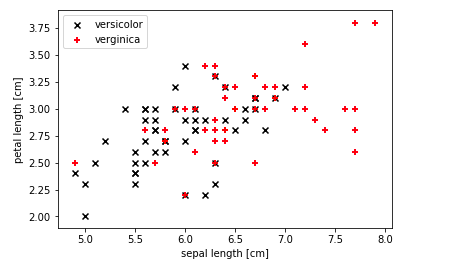
The above data set is in 2-dimensions. And, it is not linearly inseparable in a smooth manner. Can the above data set be represented in the following form by adding another dimension? If it is possible, a hyperplane can be found which separates them clearly.
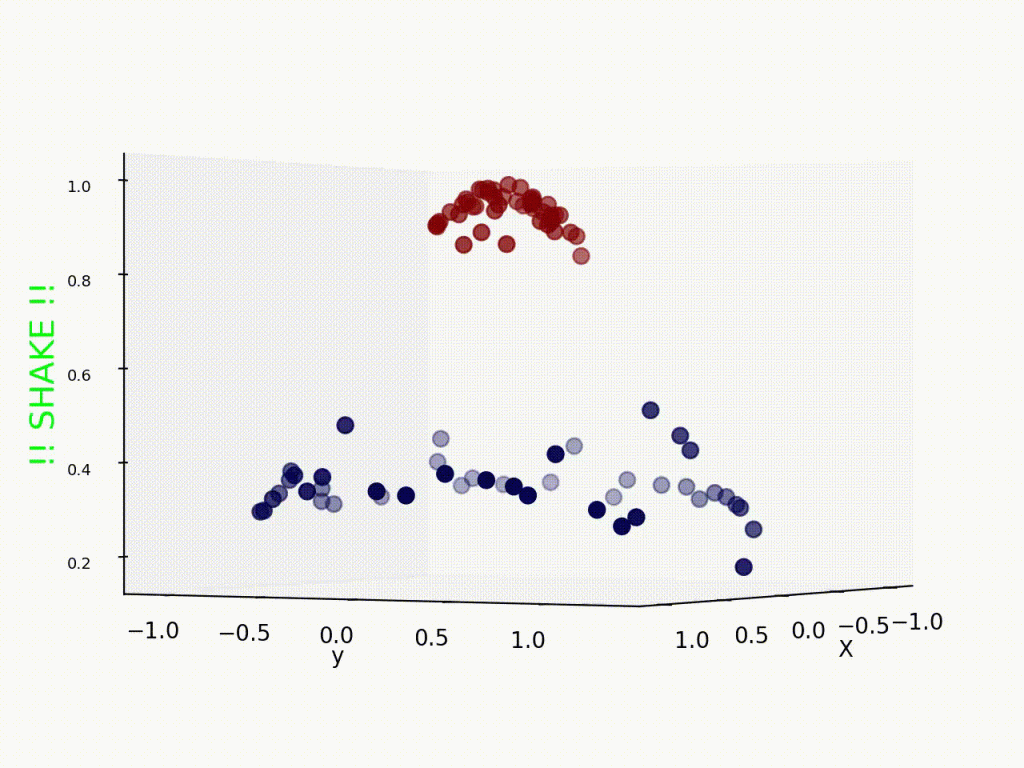
Here is a great representation in the animation format representing how data in two-dimension gets transformed when moved to 3-dimension. The data set becomes linearly separable after applying appropriate kernel function.
This is where the kernel method comes to the rescue. The idea is to apply a function that projects / transform the data in such a manner that the data becomes linearly separable. In case of SVM algorithm, data becomes linearly separable by applying maximum margin.
Let’s take a look at another simple example of data in 1 dimension which is not easy to separate and how adding another dimension makes it easy.
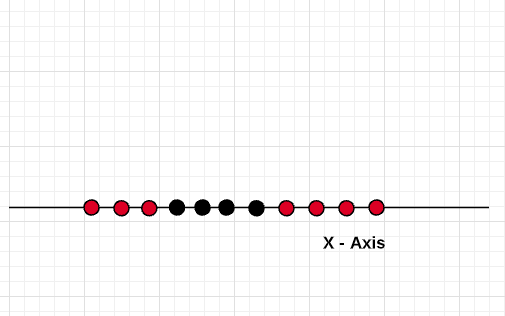
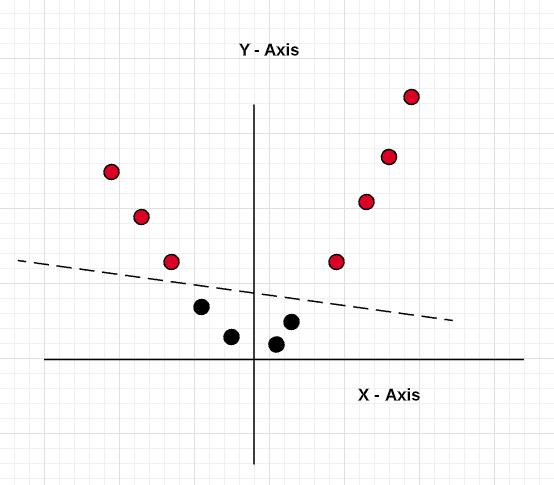
Let’s apply the method of adding another dimension to the data by using the function Y = X^2 (X-squared). Thus, the data looks like the following after applying the kernel function (Y = X^2) and becomes linearly separable.
What are Kernel Methods?
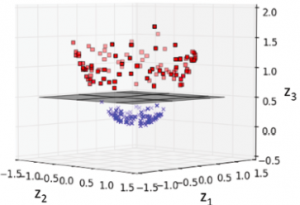
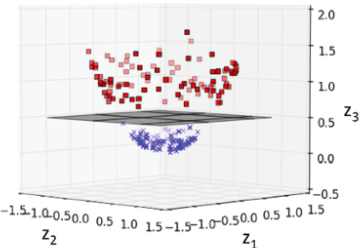
Kernel methods represent the techniques that are used to deal with linearly inseparable data or non-linear data set shown in fig 1. The idea is to create nonlinear combinations of the original features to project them onto a higher-dimensional space via a mapping function, , where the data becomes linearly separable. In the diagram given below, the two-dimensional dataset (X1, X2) is projected into a new three-dimensional feature space (Z1, Z2, Z3) where the classes become separable.
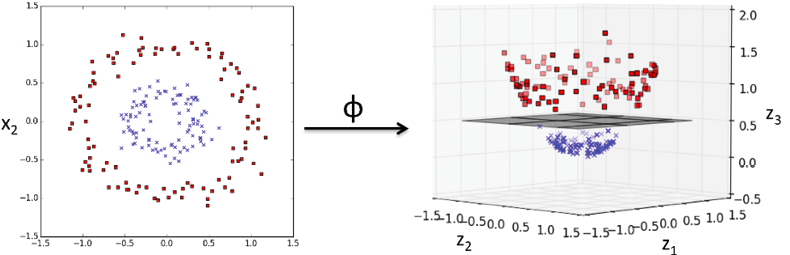
By using the above method, the training data can be transformed into a higher-dimensional feature space via a mapping function, , and a linear SVM model can be trained to classify the data in this new feature space. The new data can then be transformed using the mapping function and fed into the model for classification. However, this method is computationally very expensive. So, what’s the solution?
The solution is to apply some trick which can avoid the need to explicitly map the input data to high-dimension feature space in order to train linear learning algorithms to learn a nonlinear function or decision boundary. This is called a kernel trick. One must note that the kernel trick applies much more broadly than SVM.
What is Kernel Trick?
In order to deal with the above challenge of computing (expensive) the data coordinates (new features) using mapping function to transform to higher-dimensional space, the kernel trick is applied. Kernel trick is to convert dot product of support vectors to the dot product of mapping function. Recall the optimization problem for SVM:
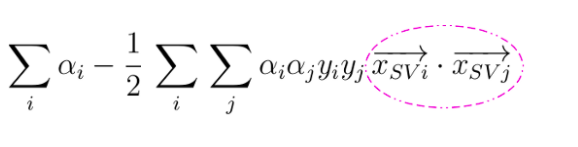
Pay attention to the pink circle which represents the dot product of the support vectors. The trick is to replace this inner product with another one, without even knowing Φ. In fact, there can be many different feature maps that correspond to the same inner product. The above equation will look something like the following after replacing the dot product of support vectors with the dot product of the mapping function.
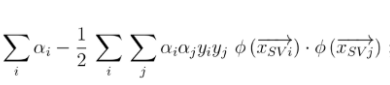
From above, if there is a function that can be represented as an inner product of mapping function, all we will be required to know is that function and not the mapping function. That function is called a Kernel Function.
What are Kernel Functions and its different types?
The kernel function is a function which can be represented the dot product of the mapping function (kernel method) and can be represented as the following:
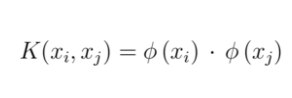
Kernel function reduces the complexity of finding the mapping function. So, the kernel function defines the inner product in the transformed space. The following are different kinds of kernel functions. That said, one can define their own kernel functions based on the condition that kernel function must be symmetric and satisfies the Mercer theorem.
- Polynomial kernel
- Gaussian kernel
- Radial basis function (RBF) kernel
- Sigmoid kernel
Code Example – SVM Model with RBF Kernel
Here is a simple code example in relation to how RBF kernel can be applied to non-linear data set.
# Load the libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
# Load the IRIS dataset
iris = datasets.load_iris();
X = iris.data
y = iris.target
# Create training/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, test_size=0.3, stratify=y)
# Feature scaling
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# Fit the model with RBF kernel
svc = SVC(kernel='rbf', random_state=1, gamma=0.10, C=10.0)
svc.fit(X_train_std, y_train)
y_pred = svc.predict(X_test_std)
# Check the performance
print('Accuracy: %.3f' % accuracy_score(y_test, y_pred))
Summary
Here is the summary of what was covered in this post:
- Data set which is linearly inseparable (non-linear) can be projected to higher dimension using the mapping function
- Kernel method is about identifying these mapping functions which transform the non-linear data set to a higher dimension and make data linearly separable
- Instead of computing data coordinates using a mapping function and training/testing model, the kernel trick is applied.
- Kernel trick allows the inner product of mapping function instead of the data points. The trick is to identify the kernel functions which can be represented in place of the inner product of mapping functions.
- Kernel functions allow easy computation.
References
- SVM and Kernel SVM
- Support vector machine: Kernel trick, Mercer’s Theorem
- SVM Kernel functions
- Vector Calculus: Understanding the dot product
- Kernels

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Completion Model vs Chat Model: Python Examples - June 30, 2024
- LLM Hosting Strategy, Options & Cost: Examples - June 30, 2024
- Application Architecture for LLM Applications: Examples - June 25, 2024
Leave a Reply