In this post, you will learn about the how to read one or more text files using NLTK and process words contained in the text file. As data scientists starting to work on NLP, the Python code sample for reading multiple text files from local storage will be very helpful.
Python Code Sample for Reading Text File using NLTK
Here is the Python code sample for reading one or more text files. Pay attention to some of the following aspects:
- Class nltk.corpus.PlaintextCorpusReader reader is used for reading the text file. The constructor takes input parameter such as corpus root and the regular expression representing the files.
- List of files that are read could be found using method such as fileids
- List of words from specific files can be found using method such as words on instance pf PlaintextCorpusReader
from nltk.corpus import PlaintextCorpusReader
#
# Root folder where the text files are located
#
corpus_root = '/Users/apple/Downloads/nltk_sample/modi'
#
# Read the list of files
#
filelists = PlaintextCorpusReader(corpus_root, '.*')
#
# List down the IDs of the files read from the local storage
#
filelists.fileids()
#
# Read the text from specific file
#
wordslist = filelists.words('virtual_global_investor_roundtable.txt')
Other two important methods on PlaintextCorpusReader are sents (read sentences) and paras (read paragraphs).
Once the words found in specific file is loaded, you can do some of the following operations for processing the text file:
- Filter words meeting some criteria: In the code below, words with length greater than 3 character is filtered
filtered_words = [words for words in set(wordslist) if len(words) > 3]
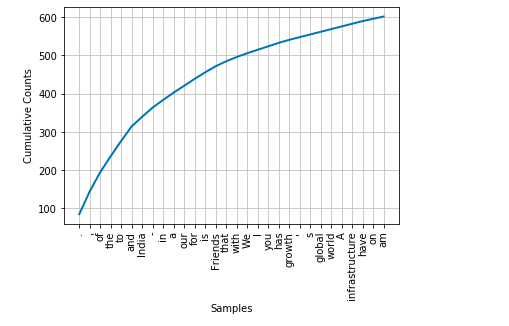
- Plot frequency distribution: Plot the frequency distribution of words. The code is followed by the frequency distribution plot.
from nltk.probability import FreqDist
#
# Frequency distribution
#
fdist = FreqDist(wordslist)
#
# Plot the frequency distribution of 30 words with
# cumulative = True
#
fdist.plot(30, cumulative=True)
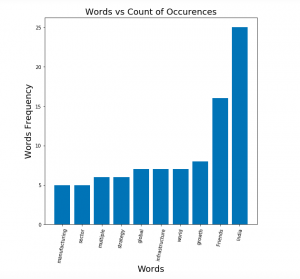
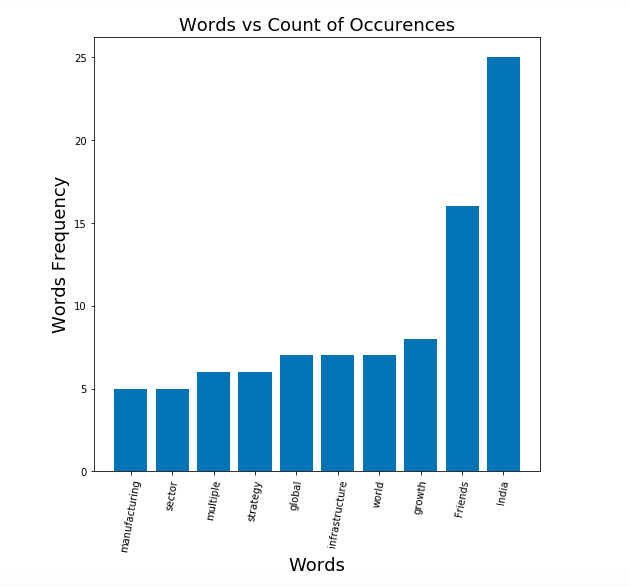
- Create Bar Plot for frequently occurring words: Here is the Python code which can be used to create the bar plot for frequently occurring words. This can be very useful in visualising the top words used in the text. One of the areas where it can be very helpful is to come up with the title of the text. For example, the text taken in this post is from our prime minister speech in recently held virtual global investor summit, Shri Narendra Modi. After looking at the below plot, I could think of title for the associated news as the following – India’s PM Narendra Modi stresses for investment in the manufacturing & infrastructure sector. Here is the Python code and related plot.
import matplotlib.pyplot as plt
from nltk.probability import FreqDist
#
# Frequency distribution
#
fdist = FreqDist(wordslist)
#
# Print words having 5 or more characters which occured for 5 or more times
#
frequent_words = [[fdist[word], word] for word in set(wordslist) if len(word) > 4 and fdist[word] >= 5]
#
# Record the frequency count of
#
sorted_word_frequencies = {}
for item in sorted(frequent_words):
sorted_word_frequencies[item[1]] = item[0]
#
# Create the plot
#
plt.bar(range(len(sorted_word_frequencies)), list(sorted_word_frequencies.values()), align='center')
plt.xticks(range(len(sorted_word_frequencies)), list(sorted_word_frequencies.keys()), rotation=80)
plt.title("Words vs Count of Occurences", fontsize=18)
plt.xlabel("Words", fontsize=18)
plt.ylabel("Words Frequency", fontsize=18)
Conclusions
Here is the summary of what you learned in this post regarding reading and processing the text file using NLTK library:
- Class nltk.corpus.PlaintextCorpusReader can be used to read the files from the local storage.
- Once the file is loaded, method words can be used to read the words from the text file.
- Other important methods are sents and paras.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Latest posts by Ajitesh Kumar (see all)
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I have a text file that I need to parse to find the most often used words. How do I do this using python and nltk?