This article represents tips on how to get started with Apache Spark on Windows using Dockers. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
If you are familiar with Dockers, the instructions below would help you get started with Spark in no time.
- Download the Spark from https://spark.apache.org/downloads.html page. Remember to select a package type with option such as “Pre-built…”. Once the zipped files are downloaded, unzip the files under the location “C:\Users\<Username>”
- Build Java8 image and start the container. Follow the instructions on this page, http://vitalflux.com/dockers-how-to-get-started-with-java8-dev-environment/.
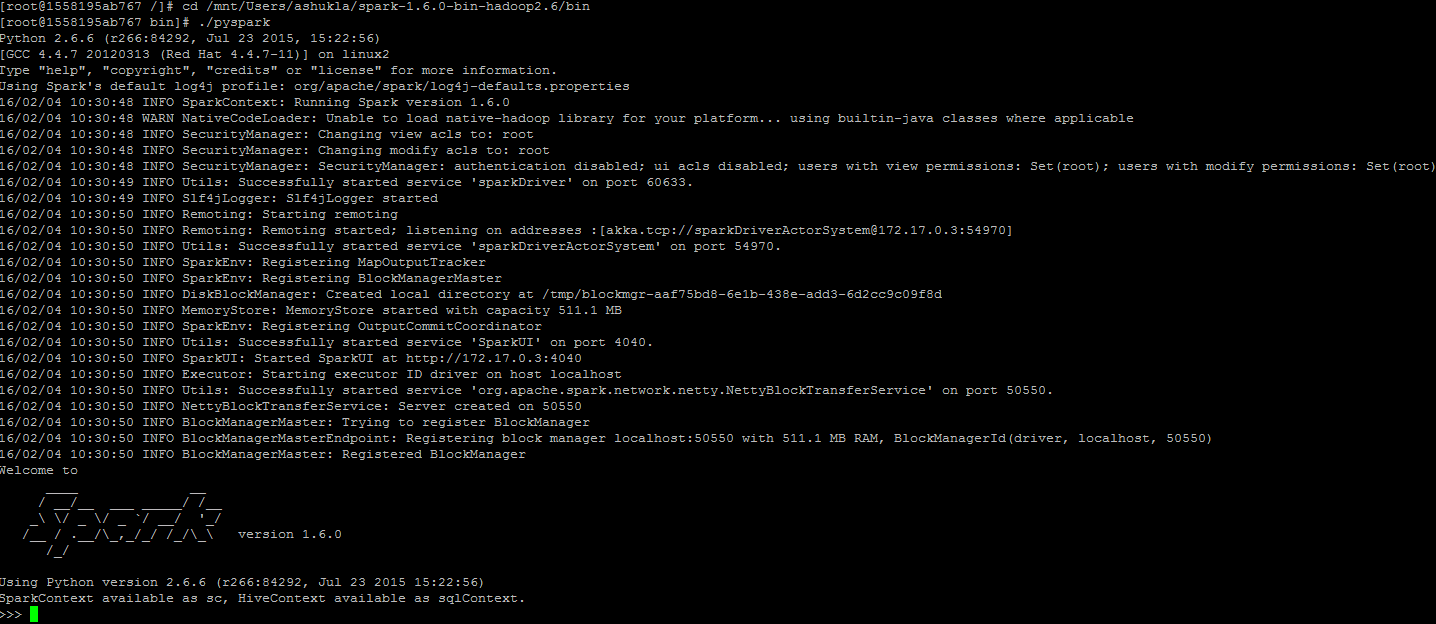
- Once the container is started, go to the folder where you would find spark files. Go to bin folder. The path could look like cd /mnt/Users/<Your_Username>/spark-1.6.0-bin-hadoop2.6/bin.
- Execute the command “./pyspark” and you will get started with following screenshot:

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. For latest updates and blogs, follow us on Twitter. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking. Check out my other blog, Revive-n-Thrive.com
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking. Check out my other blog, Revive-n-Thrive.com
Latest posts by Ajitesh Kumar (see all)
- Logistic Regression in Machine Learning: Python Example - April 26, 2024
- MSE vs RMSE vs MAE vs MAPE vs R-Squared: When to Use? - April 25, 2024
- Gradient Descent in Machine Learning: Python Examples - April 22, 2024
Leave a Reply