Category Archives: AI
What is Explainable AI? Concepts & Examples
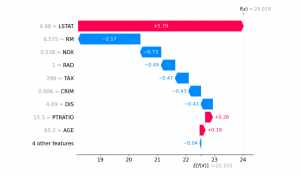
What is explainable AI (XAI)? This is a question that more people are asking, as they become aware of the potential implications of artificial intelligence. Simply put, explainable AI is the form of AI that can be understood by humans. It is AI that provides an explanation for its decisions and actions. It provides humans with the ability to explain how decisions are made by machines. This helps people trust and understand what’s happening, instead of feeling like their information is being taken advantage of or used without their permission. This is important, as many people are concerned about the increasing use of AI in our lives, especially in healthcare. …
Different Success / Evaluation Metrics for AI / ML Products

In this post, you will learn about some of the common success metrics that can be used for measuring the success of AI / ML (machine learning) / DS (data science) initiatives / projects / products. If you are one of the AI / ML stakeholders including product managers, you would want to get hold of these metrics in order to apply right metrics in right business use cases. Business leaders do want to know and maximise the return on investments (ROI) from AI / ML investments. Here is the list of success metrics for AI / DS / ML initiatives: Business value metrics / key performance indicators (KPIs): Business …
E-commerce Machine Learning Use Cases: Examples

In e-commerce, machine learning can be used to improve a number of decisions thereby resulting in creating a positive business impact. Not only does it help e-commerce organizations increase conversion rates and find the best deals for their customers, but it also helps them understand the customer better. This blog post will look at various different use cases where AI/machine learning and deep learning have been used in eCommerce. What are some key machine learning use cases in eCommerce? Here are some key areas in eCommerce where AI/machine learning can be leveraged: Product recommendation: One of the key use cases where machine learning has been used is to provide product …
Cybersecurity Machine Learning Use Cases: Examples

Cybersecurity professionals are increasingly finding cybersecurity machine learning use cases in their work. The reason for this is that cybersecurity has become more complicated and the scale of cybersecurity threats is growing exponentially. Machine learning can help to combat these cybersecurity threats by providing security teams with real-time alerts, but there are many cybersecurity machine learning use cases beyond just cybersecurity. Artificial intelligence (AI) technologies, in particular, machine learning models such as logistic regression, SVM and random forest, etc., and deep neural networks models such as CNN, LSTM, etc., have been widely used to fight against cyberattacks. In this blog post, we will look into how machine learning is being …
Free AI / Machine Learning Courses at Alison.com
Are you interested in learning about AI / machine learning / data sicence and looking for free online courses? As per MANUELA M. VELOSO, Herbert A. Simon University Professor at CMU,Machine Learning (ML) is a fascinating field of Artificial Intelligence (AI) research and practice where we investigate how computer agents can improve their perception, cognition, and action with experience. Machine Learning is about machines improving from data, knowledge, experience, and interaction. Machine Learning utilizes a variety of techniques to intelligently handle large and complex amounts of information build upon foundations in many disciplines, including statistics, knowledge representation, planning and control, databases, causal inference, computer systems, machine vision, and natural language …
12 Weeks Free course on AI: Knowledge Representation & Reasoning (IIT Madras)

Are you interested in learning about exploring a variety of representation formalisms and the associated algorithms for reasoning in Artificial intelligence? IIT Madras is going to offer a free online course on AI: knowledge representation and reasoning. This course will help you understand the basics of knowledge representation and reasoning. You’ll learn how to solve problems using logic, how to build intelligent systems that can interpret natural language, reason using formal methods and more. The course is taught by Professor Deepak Khemani, who has over 20 years of experience teaching at IIT Madras. Prof. Khemani is a Professor at Department of Computer Science and Engineering. He’s also written several books …
NIT Warangal offers one-week online training on AI, Machine Learning

Are you interested in learning about AI and Machine Learning, or refresing your concepts? NIT Warangal offers one-week online paid training (minimal fees) on AI, Machine Learning. This program is a great opportunity for students to learn about AI & machine learning basics and advanced concepts. It is organized by the Department of Electronics and Communication Engineering & Department of R&D in association with Center of Continuing Education. It will be taught by experience professors who have years of experience in their respective fields. The course will take place between 30th November to 4th December 2021, and it is open to all Faculty/ Research Scholars/Industry professionals/ and other eligible students …
Machine Learning Examples from Daily Life

Machine learning is a powerful machine intelligence technique that can be used in a variety of settings to generate data insights. In this blog post, we will explore real-world or real-life machine learning / deep learning / AI examples from daily life. We’ll see how machine-learning techniques have been successfully applied to solve real-life problems. The idea is to make you aware of how machine learning and data science applications are everywhere. What are some real-world examples of machine learning from daily life? Here are some real-world examples of machine learning that we use in our daily life: Best driving directions (Google Maps): A bunch of machine learning / deep …
Data Science / AI Team Structure – Roles & Responsibilities

Setting up a successful artificial intelligence (AI) / data science or advanced analytics practice or center of excellence (CoE) is key to success of AI in your organization. In order to setup a successful data science COE, setting up a well-organized data science team with clearly defined roles & responsibilities is the key. Are you planning to set up the AI or data science team in your organization, and hence, looking for some ideas around data science team structure and related roles and responsibilities? In this post, you will learn about some of the following aspects related to the building data science/machine learning team. Focus areas Roles & responsibilities Data Science Team – Focus …
Sentiment Analysis & Machine Learning Techniques

Artificial intelligence (AI) / Machine learning (ML) techniques are getting more and more popular. Many people use machine learning to analyze the sentiment of tweets, for example, to make predictions related to different business areas. In this blog post, you will learn about different machine learning / deep learning and NLP techniques which can be used for sentiment analysis. What is sentiment analysis? Sentiment analysis is about predicting the sentiment of a piece of text and then using this information to understand users’ (such as customers) opinions. . The principal objective of sentiment analysis is to classify the polarity of textual data, whether it is positive, negative, or neutral. Whether …
Procure-to-pay Processes & Machine Learning
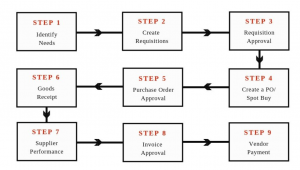
The procure-to-pay (P2P) cycle or process consists of a set of steps that must be taken in order for an organization to procure and pay for goods and services. Procurement is the process by which organizations purchase goods, supplies, equipment, or services from outside sources. The procurement function may also serve as an intermediary between two internal departments or divisions that have overlapping needs. In this blog post, we will discuss how AI / machine learning can be leveraged to automate certain procure-to-pay processes such that procure-to-pay teams can focus on core business goals. What is the procure-to-pay cycle or process? The procure-to-pay (P2P) cycle or process is defined as …
Demand Forecasting & Machine Learning Techniques
Machine learning is a technology that can be used for demand forecasting in order to make demand forecasts more accurate and reliable. In demand forecasting, machine learning techniques are used to forecast demand for a product or service. There are different types of machine learning/deep learning techniques used in demand forecastings such as neural networks, support vector machines, time series forecasting, and regression analysis. This blog post will introduce different machine learning & deep learning techniques for demand forecasting and give an overview of how they work. What is the demand forecasting process? The demand forecasting process is defined as the creation of demand forecasts, demand planning, and demand decision …
Drug Discovery & Deep Learning: A Starter Guide
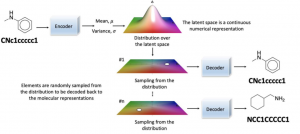
The drug discovery process is tedious, time-consuming, and expensive. A drug company has to identify the compounds that are most likely to be successful in drug development. The drug discovery process can take up to 15 years with an average cost of $1 billion for each drug candidate that passes clinical trials. With AI and deep learning models becoming more popular in recent years, scientists have been looking at ways to use these tools in the drug discovery process. This article will explore how deep learning generative models (GANs) could be used as a starting point for data scientists to get started drug discovery AI projects! What is the drug …
Supplier risk management & machine learning techniques
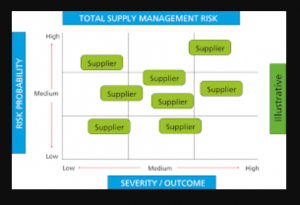
Supplier risk management (SRM) is a serious issue for procurement professionals. Suppliers can be unreliable, have poor quality products, or fail to meet specifications. In this blog post we will discuss AI / machine learning algorithms / techniques that you can use to manage supplier risk and make your procurement process more efficient. What is supplier risk management? Supplier Risk Management (SRM) also known as Supplier Risk Optimization (SRO), refers to policies and technology that enables organizations to manage risks related with suppliers. This can be done by analyzing data about past purchases from the supplier, predicting future risks related with purchases from this particular company. It’s crucial for procurement …
Key Deep Learning Techniques for Disease Diagnosis
The disease diagnosis process has been the same for decades- a physician would analyze symptoms, perform lab tests, and refer to medical diagnostic guidelines. However, recent advances in AI/machine learning / deep learning have made it possible for computers to diagnose or detect diseases with human accuracy. This blog post will introduce some machine learning / deep learning techniques that can be used by data scientists for training models related to disease diagnosis. What are different types of diseases that can be diagnosed using AI-based techniques? The following is a list of different types of diseases that can be diagnosed using machine learning or deep learning-based techniques: Cancer prognosis and …
Data Analytics – Different Career Options / Opportunities

Data analytics career paths span a wide range of career options, from data scientist to data engineer. Data scientists are often interested in what they can do with the data that is analyzed, while data engineers are more focused on the analysis itself. Whether you’re looking for a career as a data scientist, data analyst, ML engineer, or AI researcher, there’s something for everyone! In this blog post, we will different types of jobs and careers available to those interested in data analytics and data science. What are some of the career paths in data analytics? Here are different career paths for those interested in data analytics career: Data Scientists: …
I found it very helpful. However the differences are not too understandable for me