This blog represents What’s The Funda (WTF) around consistent hashing and DHT (Distributed Hash Tables), Databases use cases where it is used.
Problems with Traditional Hashing Mechanism
Lets understand the traditional hashing mechanism using following diagram:
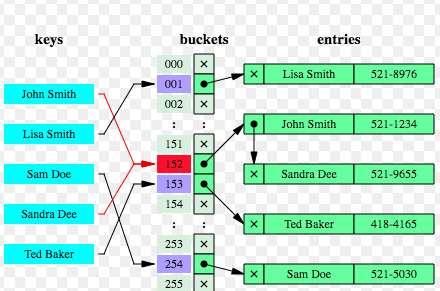
Figure 1. How does Hash Table/Map works?
Pay attention to some of the following aspects as per the above diagram:
- Hash table/map is an array with each of the array index pointing to a linked list having each node representing a key-value pair.
- Keys are passed through a hash function. The index of the array (bucket) to which a specific key-value pair would get associated is a function of hash value and total size of the array. For example, in above diagram, key such as “Sam Doe” is hashed and evaluated to get associated with index, 254. Keys such as “John Smith” and “Sandra Dee” gets associated with same index such as 152.
- So far so good.
- What if the size of the array changes (increases or decreases)? In other words, what if the hash table is resized?
- Given that the key-value pair and its positioning in the array is a function of hash value and size of the array, the change in size of array would lead to re-assignment/remapping of buckets for nearly all key-value pair.
Lets see if we can apply the traditional technique such as above to store a record (having some key) to a specific computer (node) out of a list of computers (nodes).
The hashing technique, thus, can be said to be inconsistent.
Apply traditional hashing to store key-value in network of computer nodes
The requirement is to store key-value pairs on different computer nodes as a function of hash of key value and number of computer nodes.
Let us say the hash value is calculated as following:
hash_value = hash(key);
Computer on which the data gets stored is calculated as following:
computerThatStoresRecord = func(hash_value, noOfComputerNodes);
So far so good. The above calculation can be done on a centralized node and the data/record is appropriately sent to the node and stored/written/persisted there. The same function is used for reading/retrieving the data/record from a specific node.
Problem arises when the the value of noOfComputerNodes changes. This can change due to the fact that the one can add one or more nodes or, one or more nodes can shut down.
Due to the way that record’s node location s determined, it would start getting wrong. This is because different value of computerThatStoresRecord would get calculated as a result of changed value of noOfComputerNodes. As a result, all the records may end up getting written on different nodes.
So, there is a problem. How to solve this problem? Consistent Hashing is the answer.
What is Consistent Hashing?
Consistent hashing is a special hashing technique using which only a set of key-value pairs get relocated to new buckets unlike traditional hashing technique such as that mentioned above. Following happens in case of consistent hashing:
- Each bucket gets a unique key (index/number etc) associated with it based on the hash value generated as a function of unique name/label of the bucket.
- Each bucket is assigned a range of keys. In the diagram given below, all the buckets are specified key values. Bucket 1 has key value as 78. Bucket2 has key value as 180. Item with key value 150 would get stored in bucket2.
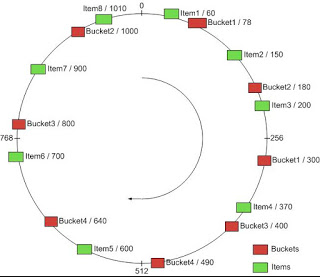
Figure 2. Consistent hashing explained
- A key-value pair is mapped to bucket based on the range of keys it is associated with and, thus, the bucket.
- Each time a key-value pair needs to be stored or retrieved, the partition key is determined using a hash function which takes the input as key. The range of number (keys) is then determined and, thus, the bucket gets determined which stores the key-value pair. In the diagram given above, the bucket 2 will store all the key-value pairs having partition key falling in the range of 78-180 . Thus, bucket 2 will store item with key as 150, bucket 3 will store item with with key as 370 etc.
- In case, a bucket gets removed, only a set of key-value pairs get remapped to new bucket unlike the traditional hashing technique where nearly all keys get remapped to newer buckets. Thus, if bucket2 is removed, item with key as 150 will get stored in bucket 3. In fact all keys which were getting stored in bucket2 will get remapped to bucket 3. Other key-value pairs will not get impacted.
Apply consistent hashing to store key-value pair in network of computer nodes
Let’s apply consistent hashing technique to store key-value pair in the network of computer nodes.
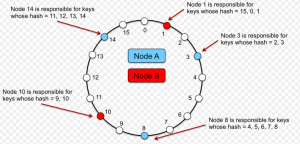
- Each node in the network holds a key value; In that manner, two nodes in the network represent a range of key values. In the diagram given below, there are four nodes represented using numeric value such as 1, 3, 8, 10, 14. Node 3 would store record whose value of key falls in the range of 1-3 with 1 being excluded. Similarly, node 8 would store record whose key falls in the range of 3-8.
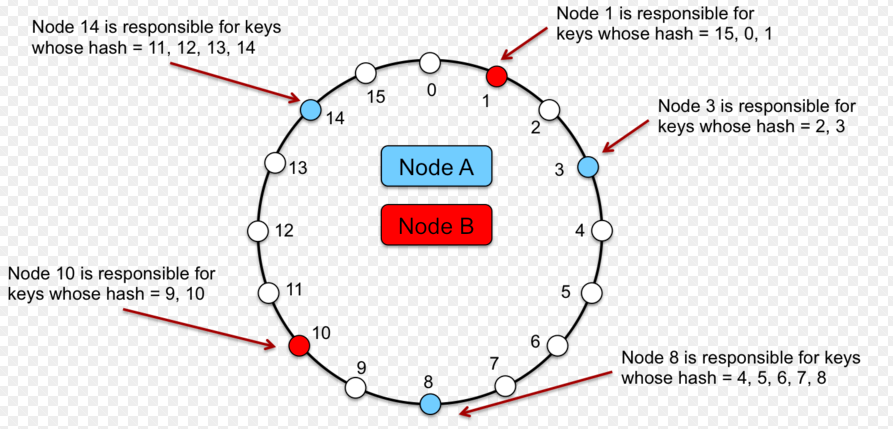
Figure 3. Consistent Hashing Ring
- The key of record to be stored (or whose data needs to be retrieved) is passed through a hash function and the value of partition key is calculated. Based on the partition key value, the range of values is determined in which the key value falls. Appropriately, the computer node is determined which will be used for accessing data or storing data.
- In case, node 3 gets shut down, the value in range 1-3 is mapped to node 8.
- In case, a new node is added, say node 6. In that case, the value such as 4 and 5 gets mapped to node 6.
- This avoids issue of remapping nearly all the records to newer nodes when traditional hashing technique is used.
Consistent Hashing & Databases/DHT
Consistent hashing is used for distributing data across the database cluster. This is used to minimize data reorganization when nodes are added or removed. Following are some of the databases where consistent hashing technique is used:
- Amazon Dynamo and database partitioning
- Data partitioning in Cassandra
- Couchbase database partitioning
- GlusterFS, a network-attached storage file system
Consistent hashing is used in the system based on Distributed Hash Tables, or, in other words, distributed key-value stores. For example, web caching, distributed file system etc.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me