This article represents detailed view on what happens when a driver program (spark application) is started on one of the worker node when working with Spark standalone cluster. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
Following are the key points described later in this article:
- Snapshot into what happens when Spark Standalone Cluster Starts?
- Snapshot into what happens when a spark application (Spark Shell) starts on one of the worker nodes?
- Snapshot into what happens when a spark application (Spark Shell) stops on the worker node?
Snapshot into what happens when Spark Standalone Cluster Starts?
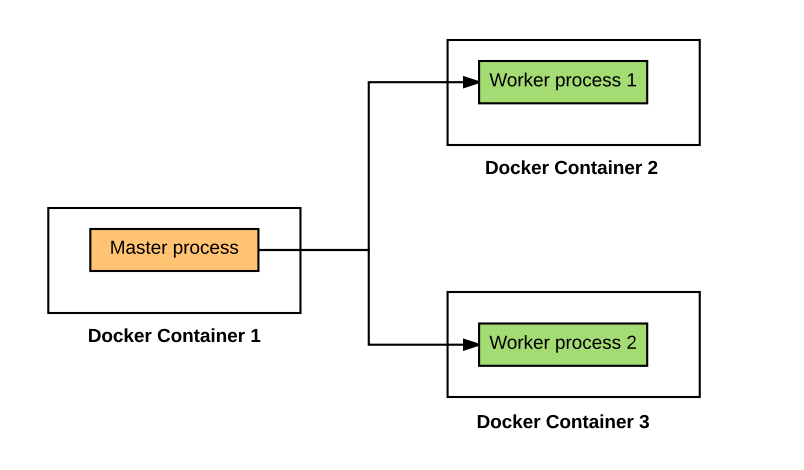
In our example, we are starting a cluster with one master and two worker nodes. Following is the Docker-compose file used to start the cluster. For detailson setting up Spark standalone cluster, access this page on how to setup Spark standalone cluster using Dockers. Following is what happens when the cluster starts:
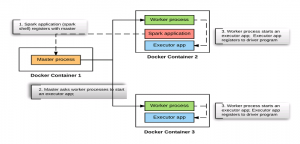
Spark cluster when no spark application is running
- Master Node: On master node, a java process started using class “org.apache.spark.deploy.master.Master”.
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.master.Master -h spark-master
- 2 Worker Nodes: On both the worker nodes, java processes started with following command. Make a note of class “org.apache.spark.deploy.worker.Worker” passed to Java command.
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker spark://spark-master:7077
In following section, we will see processes which start upon starting a spark shell application.
Snapshot into what happens when a spark application (Spark Shell) starts on one of the worker nodes?
Let us start a Spark application (Spark Shell) using command such as following on one of the worker nodes and take a snapshot of all the JVM processes running in each of the worker nodes and master node. Note that the Spark shell gets started in client mode.
spark-shell --master spark://192.168.99.100:7077
As the spark application gets started on the worker node, following is the snapshot of all the JVMs processes running in different nodes:
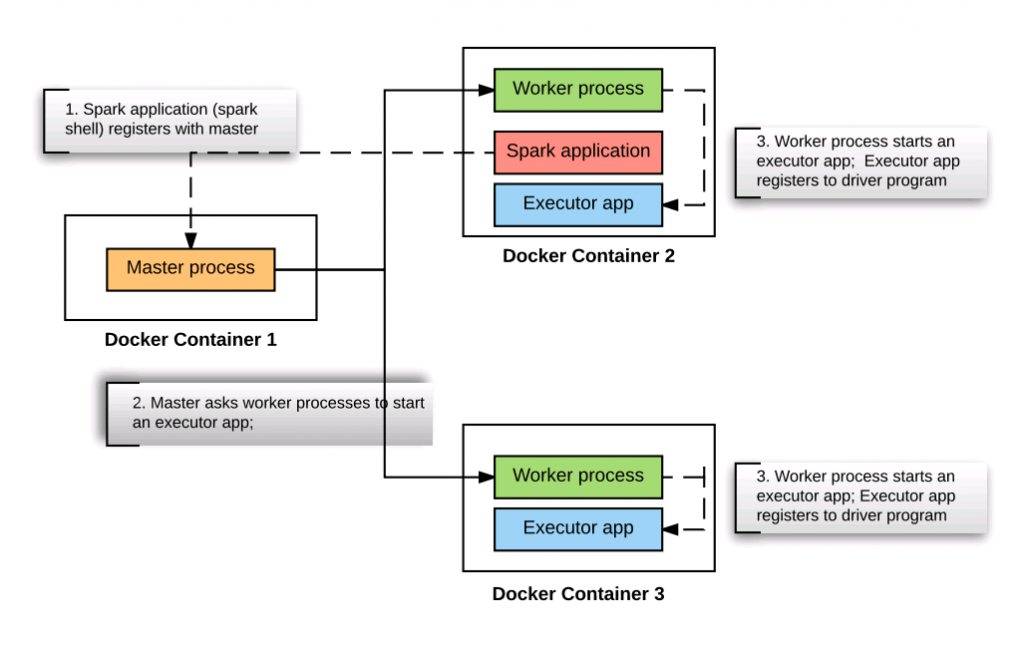
Detailed view of Spark cluster when spark application is started
- Master Node: On master node, no change. Only one java process such as following is found.
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.master.Master -h spark-master
- Worker Node on which Spark Shell got started: Following are three Java processes found to be running:
- JVM running Worker: This is the process which started when worker node started.
- JVM running org.apache.spark.deploy.SparkSubmit: This is the process that got started as a result of invoking “spark-shell” program on the worker node. Following is how the command looks like:
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Dscala.usejavacp=true -Xmx1g org.apache.spark.deploy.SparkSubmit --master spark://192.168.99.100:7077 --class org.apache.spark.repl.Main --name Spark shell spark-shell
- JVM running org.apache.spark.executor.CoarseGrainedExecutorBackend: This is the executor process started for the driver program (spark-shell app) to run the tasks. Following is how the command looks like:
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Xmx1024M -Dspark.driver.port=40442 org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@172.17.0.3:40442 --executor-id 1 --hostname 172.17.0.3 --cores 2 --app-id app-20170104100629-0000 --worker-url spark://Worker@172.17.0.3:8881
Pay attention to some of the following facts:
- The executor process is another Java process (org.apache.spark.executor.CoarseGrainedExecutorBackend).
- It is registered with Driver using a URL such as spark://CoarseGrainedScheduler@172.17.0.3:40442.
- It is running on host with IP as 172.17.0.3
- The worker node URL on which executor process is running is spark://Worker@172.17.0.4:8881.
- Another Worker Node: Following are two different Java processes found on another worker node:
- JVM running Worker: This is the process which started when worker node started.
- strong>JVM running org.apache.spark.executor.CoarseGrainedExecutorBackend: This is the executor process started for the driver program (spark-shell app) to run the tasks. Following is how the command looks like:
/usr/lib/jvm/java-8-oracle/bin/java -cp /conf/:/usr/local/spark-2.0.0-bin-hadoop2.7/jars/* -Xmx1024M -Dspark.driver.port=40442 org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@172.17.0.3:40442 --executor-id 0 --hostname 172.17.0.4 --cores 2 --app-id app-20170104100629-0000 --worker-url spark://Worker@172.17.0.4:8882
Pay attention to some of the following facts:
- The executor process is another Java process (org.apache.spark.executor.CoarseGrainedExecutorBackend).
- It is registered with Driver using a URL such as spark://CoarseGrainedScheduler@172.17.0.3:40442.
- It is running on host with IP as 172.17.0.4
- The worker node URL on which executor process is running is spark://Worker@172.17.0.4:8882.
Snapshot into what happens when a spark application (Spark Shell) stops on the worker node?
Once the spark-shell program exit, executor app on both the workers are killed. Worker processes are asked to kill the executor app by master process. Worker processes then cleans up local directories created for the executor app.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me