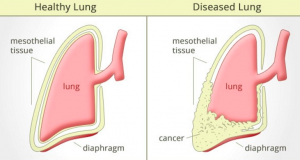
In this article, I would introduce different aspects of the building machine learning models to predict whether a person is suffering from malignant or benign cancer while emphasizing on how machine learning can be used (predictive analysis) to predict cancer disease, say, Mesothelioma Cancer. The approach such as below can as well be applied to any other diseases including different types of cancers.
Predicting Mesothelioma Cancer – Supervised Learning Problem
Machine learning problems are classified into different kinds of learning problem. Most important of them are following:
- Supervised learning
- Unsupervised learning
Supervised Learning
In supervised learning, you have a history of data with each record being labeled. Thus, in case of predictive analysis of Mesothelioma cancer, there is a history of data (blood tests, X-ray reports / imaging scan, Biopsies) of patients record with a label whether a patient was found to be suffering from the disease or not. The following would represent the data record with labels:
Unsupervised learning (for features identification)
In case of unsupervised learning, there is a history of data but there are no labels associated with the data. In case of predictive analysis of Mesothelioma cancer, unsupervised learning can be used to do feature identification. The following represents the detail:
- Historical data for patients suffering from Mesothelioma cancer will be taken
- The unsupervised learning algorithm such as K-Means could be run on the dataset
- The cluster of data could be found and labeled.
- The label then becomes the feature which can be used to identify the future patients or made part of feature set of supervised learning algorithm.
Predicting Mesothelioma Cancer – Classification Problem
Predicting whether a person is suffering from cancer is a classification problem. In classification problem, what is predicted is discrete valued output such as Yes or No, or different classes such as A, B or C. In this case, the goal is to predict whether a person is suffering malignant or benign cancer. Thus, the classes which need to be predicted are following:
- Malignant cancer
- Benign cancer
One of the key thing to note is that whatever model is built, the goal is to avoid Type II error (false negative). Other type of error is Type I error (false positive). Lets quickly understand what would be Type I and Type II error given the current context of mesothelioma cancer.
Null Hypothesis Formulation for predicting Mesothelioma Cancer
As part of predictive analysis, hypothesis formulation is the key step. In current case of predicting whether it is a malignant or benign mesothelioma cancer, one or more features (independent variables such as age, gender, location, blood tests parameters etc.) will be taken into consideration as the reason (s) for the cancer to happen. The following null hypothesis will be formulated:
The set of independent variables taken into consideration are not responsible for the Mesothelioma cancer to happen. In other words, Mesothelioma cancer has happened by chance and not due to one or more considered features.
Type I and Type II Error when predicting Mesothelioma Cancer
As mentioned above, Type II Error are cases when it is falsely predicted that person is not suffering from Mesothelioma cancer when he / she is actually suffering from the cancer. This type of error would be called as Type II error (false negative). Idea is to minimize such error due to obvious reasons that you would rather want to falsely alert a person that he / she is suffering from the cancer (Type I error – false positive) rather than falsely tell him / her that he / she is not suffering from the disease when he is actually suffering from the disease.
Classification Algorithms for Predictive Analysis of Cancer
Once it is identified that we are talking about classification problem, there are different machine learning algorithms which can be used for prediction of cancer disease such as Mesothelioma cancer. The following represents some of them:
- Support vector machine
- Random forest
- Neural networks / Deep Learning (Multilayer Perceptron – Deep Feedforward Neural network)
One should run the data through different algorithms and look for prediction accuracy. Which algorithm should be used depends upon the problem compexity, data availability etc.
Feature Set Identification
One of the key steps of predictive analysis is identification of predictor (independent) and response (dependent) variables. The following can be the feature list (for Mesothelioma cancer) one can get started with:
- Age
- Gender
- Exposure to asbestos
- Exposure to Zeolites mineral
- Exposure to radiation
- Infection with Simian (SV40) virus
Data Gathering / Preparation
Once the feature set has been identified, the next step is to gather the data from different sources. Subsequently, one would require to prepare the data in required formats appropriate to be fed into the model. Many a times, data also needs to be normalized to appropriate scale.
Training / Test Formulation Strategy
Next step is to get started with training and testing models based on different classification algorithms. One of the common strategy is to split the data into three different types:
- Training dataset
- Validation dataset
- Test data set
All of the above data set consists of pairing of input data with output labels. Validation dataset is used for tuning the parameters of the classifier.
Programming Tools for Prediction Analysis
You can use R-programming or Python programming for doing predictive analysis. Both of them comes with packages for classification algorithms.
You can also make use of cloud computing tools such as AWS Machine learning for exploring the classification models.
Machine Learning Tutorial
You want to get started with machine learning, then, here is a great Machine Learning Course by Andrew Ng on Coursera.org.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me