In machine learning, ridge classification is a technique used to analyze linear discriminant models. It is a form of regularization that penalizes model coefficients to prevent overfitting. Overfitting is a common issue in machine learning that occurs when a model is too complex and captures noise in the data instead of the underlying signal. This can lead to poor generalization performance on new data. Ridge classification addresses this problem by adding a penalty term to the cost function that discourage complexity. This results in a model that is better able to generalize to new data. In this post, you will learn about Ridge classifier in detail with the help of Python example.
How does Ridge Classification Work?
Ridge classification works by adding a penalty term to the cost function that discourages complexity. The penalty term is typically the sum of the squared coefficients of the features in the model. This forces the coefficients to remain small, which prevents overfitting. The amount of regularization can be controlled by changing the penalty term. A larger penalty results in more regularization and a smaller coefficient values. This can be beneficial when there is little training data available. However, if the penalty term is too large, it can result in underfitting.
The loss function of Ridge classifier is not cross-entropy loss as like Logistic Regression. Rather the loss function is mean square loss with L2 penalty. It works in the following manner for the binary classification problems by making use of Ridge regression algorithm:
- Converts the target variable into +1 and -1 appropriately
- Train a Ridge model with loss function as mean square loss with L2 regularization (ridge) as penalty term
- During prediction, if the predicted value is less than 0, it predicted class label is -1 otherwise the predicted class label is +1.
Ridge classifier is trained in a one-versus-all approach for multi-class classification. LabelBinarizer is used to achieve this objective by learning one binary classifier per class. Take a look at the source code of RidgeClassifier on this page – Ridge source code on Github.
Ridge Classifier Python Example
In the code given below IRIS data set is used. Note that LabelBinarizer is used to achieve the multi-class classification. There are three binary classification models trained. The same will be depicted when coefficients are printed.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.linear_model import RidgeClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#
# Load IRIS dataset
#
iris = datasets.load_iris()
#
# Create dataframe from IRIS dataset
#
df = pd.DataFrame(iris.data, columns=["sepal_length", "sepal_width", "petal_length", "petal_width"])
df["class"] = iris.target
#
# Create training and test dataset
# As IRIS is multi-class dataset, only two classes (Setosa, Versicolour) have been
# taken into consideration for training purpose for testing
# binary classification
#
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:,0:4],
df.iloc[:, -1],
test_size=0.3,
random_state=1,
stratify=df.iloc[:, -1])
#
# Create standardized training dataset
#
sc = StandardScaler()
X_train_norm = sc.fit_transform(X_train)
X_test_norm = sc.transform(X_test)
#
# Create RidgeClassifier instance
#
rdgclassifier = RidgeClassifier()
rdgclassifier.fit(X_train_norm, y_train)
#
# Score the classifier
#
rdgclassifier.score(X_test_norm, y_test)
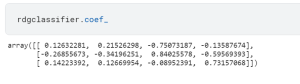
The coef_ attribute when invoked on the ridge classifier instance (rdgclassifier) will print coefficients in 3×4 matrix.

Conclusion
In this blog post, we provided an overview of ridge classification concepts and demonstrated how to build a ridge classifier in Python. We hope you found this information helpful. If you have any questions or feedback, please let us know.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me