In data science, variables are the building blocks of any analysis. They allow us to group, compare, and contrast data points to uncover trends and draw conclusions. But not all variables are created equal; there are different types of variables that have specific uses in data science. In this blog post, we’ll explore the different variable types and their uses in data science.
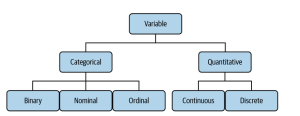
The picture below represents different types of variables one can find when working on statistics / data science projects:
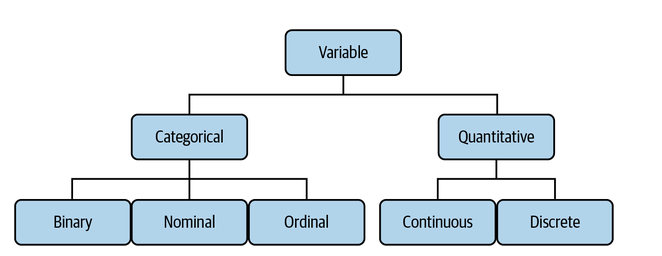
Lets understand each types of variables in the following sections.
Categorical / Qualitative Variables
Categorical variables are a type of data that can be grouped into categories, based on certain characteristics. They are typically used in statistical analysis to measure the relationships between different factors in a study. Categorical variables are also known as qualitative variables because they represent values without any numerical significance. The following include different types of categorical variables:
- Binary / Boolean variables: Binary variables are commonly used when measuring dichotomous outcomes and whether someone is classified as belonging to a particular group or not. Examples could include gender (male / female), current employment status (yes/no), etc.
- Nominal variables: Nominal variables are generally used when there are multiple categories that need to be identified but cannot be compared against each other due to their qualitative nature. Examples include eye color, nationality and religious beliefs. The following are some of the examples of nominal variables.
- Profession is another example of a nominal categorical variable in which there could be many different categories depending on the context. A person’s profession could fall into categories such as doctor, nurse, lawyer, engineer, etc., without any order to their relative importance or priority.
- Marital status is yet another example of a nominal categorical variable with possible values including single, married, divorced and widowed. Again there is no ordering between these states; they are all equally important.
- Another common example of a nominal categorical variable is political party affiliation. Categories may include Republican, Democrat, Independent or other minor parties depending on the country being studied. In this case too the various parties have no ranking nor do they take precedence over one another.
- Ordinal variables: Ordinal categorical variables are variables that represent categories of data in which the order of the categories has meaning. The categories are ranked, so that one is “greater than” or “less than” the other. For example, an ordinal categorical variable such as educational level might have categories from lowest to highest such as none, primary school, secondary school, college or university degree. The following are some of the examples of ordinal variables:
- A survey about a customer’s satisfaction with a product or service on a scale from 1-5, where 1 is extremely dissatisfied and 5 is extremely satisfied. In this situation, the higher numbers represent a greater amount of satisfaction.
- A survey question asking respondents to rate their agreement with a statement on a scale from strongly disagree to strongly agree. Here again it can easily be seen that one opinion is greater than the other when it comes to agreement with the statement.
- A survey question asking respondents to rank their feelings towards something on a scale from hate to love. Though not technically quantitative data since there are only five pre-defined terms used in this example; once again it can be seen that one feeling is greater than another when it comes to ranking emotions towards something.
Numerical / Quantitative Variables
Numerical variables are a type of variable used in data analysis to quantify or measure the characteristics of an entity or phenomenon. They are also known as quantitative variables because they involve counting, measuring, or assigning values to a particular characteristic. Numerical variables can be divided into two main types: continuous and discrete.
The following are two different kinds of quantitative variables as shown in the above diagram:
- Continuous variables: Continuous quantitative variables provide us with numerical information that can be measured within a given range without any breaks. Examples of continuous quantitative variables include things such as weight, height, length, pressure, temperature, speed, and time. These are all characteristics that have no definite beginning or end point in the range and can be measured to very precise levels. Weight is perhaps the most commonly used continuous variable as it can be measured from any starting point up to virtually any given level with precision using scales such as a balance beam scale or digital scale. Height is also a common continuous variable which is typically measured in centimeters or inches depending on the unit of measurement used. Length is another example of a continuous variable which usually refers to the distance between two points on an object and is often measured in feet or meters depending on the context. Temperature is another important continuous variable which measures how hot or cold something is with respect to a set reference point and is usually measured in degrees Celsius (°C) or Fahrenheit (°F).
- Discrete variables: A discrete quantitative variable is a variable that takes on either a finite or countable number of values. Examples of discrete quantitative variables include the number of siblings in a family, the number of cars owned by an individual, or the number of members in a sports team. Another example could be the age of an individual, which can have discrete values such as 18, 19, 20, etc., but not 12.45 or 10.7, for example. Another example is the number of pets owned by an individual. This could be used to keep track of how many animals are being kept as pets in households around the world, as well as to provide information on animal welfare standards. Additionally, it could provide insights into how different types of pets are being kept – such as cats versus dogs – or what breeds are most popular. This could even be broken down further into specific cities or states to gain more detailed insights on pet ownership trends in certain areas.
Conclusion
In conclusion, there are many different types of data variables available for use in data science tasks – quantitative, categorical (binary or Boolean, nominal & ordinal) – each with its own advantages and applications depending on what kind of analysis needs to be done. Understanding these different types will help you select the right one for your project and ensure that you get accurate results from your analysis! With this comprehensive overview now under your belt, you should have no problem selecting the appropriate variable type for your next dataset!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me