Last updated: 6th Dec, 2023
As a data scientist, we are tasked with building machine learning (ML) models that can accurately predict outcomes based on input data. However, one of the biggest challenges in building ML models is dealing with class imbalance. Class imbalance occurs when the distribution of classes in your dataset is uneven, with one class significantly outnumbering one or more other classes. Class imbalance is a common problem when building machine learning models for different problems including fraud detection, medical diagnosis, and customer churn prediction, to name a few.
Handling class imbalance correctly is crucial for data scientists, as it can have a significant impact on the performance of machine learning models. Failure to address class imbalance can lead to models that are biased towards the majority class and have poor predictive power for the minority class.
“Nearly all existing studies refer to class imbalance as a proportion imbalance, where the proportion of training samples in each class is not balanced. The ignorance of the proportion imbalance will result in unfairness between/among classes and poor generalization capability”. – Rethinking Class Imbalance in Machine Learning
In this blog post, we’ll explore details on what is class imbalance, different methods for handling class imbalance in machine learning models, and discuss their pros and cons. In addition, you will learn about how to deal with class imbalance by adjusting class weight while solving a machine learning classification problem. This will be illustrated using Sklearn Python code example.
What is Class Imbalance?
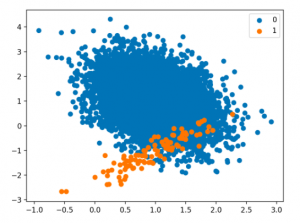
Class imbalance refers to a problem in machine learning where the classes in the data are not equally represented. For example, if there are 100 data points and 90 of them belong to Class A and 10 belong to Class B, then the classes are imbalanced. Class imbalance is a significant challenge in training machine learning models, particularly in supervised learning scenarios where the goal is to classify data points into distinct categories. This imbalance occurs when the number of instances of one class significantly outweighs the number of instances of other classes in the training dataset. Here is what the class imbalance would look like. Note how one one class (the majority class labeled as 0) significantly outnumbers the other class (the minority class labeled as 1)
Examples of Real-world Problems having Class Imbalance Issue
Class imbalance has been found to be one of the most common issues when solving machine learning classification problems related to the healthcare domain, banking (fraud) domain, etc. Here are few examples of use cases with imbalanced dataset:
- Fraud detection: In a dataset of credit card transactions, the majority of transactions are likely to be legitimate, while only a small percentage may be fraudulent. This leads to class imbalance, where the majority class is “legitimate transactions” and the minority class is “fraudulent transactions.”
- Medical diagnosis: In a dataset of patient records, rare diseases may be vastly outnumbered by more common ones. This leads to class imbalance, where the majority class is “common diseases” and the minority class is “rare diseases.”
- Customer churn prediction: In a dataset of customer records, the majority of customers are likely to remain loyal, while only a small percentage may churn (i.e., cancel their subscription or service). This leads to class imbalance, where the majority class is “loyal customers” and the minority class is “churned customers.”
- Anomaly detection: In a dataset of network traffic logs, the majority of traffic is likely to be normal, while only a small percentage may be anomalous or malicious. This leads to class imbalance, where the majority class is “normal traffic” and the minority class is “anomalous or malicious traffic.”
Challenges: Building High Performance Models with Imbalanced Dataset
Building high-performance models with imbalanced datasets presents several challenges. Imbalanced classification problems occur when the distribution of classes in the training data is highly skewed. Here are some of the key challenges and examples:
- Poor Generalization for Minority Class: In a spam detection system, if ‘non-spam’ emails significantly outnumber ‘spam’ emails, the model might become very good at identifying ‘non-spam’ but fail to correctly classify ‘spam’ emails. This can lead to many spam emails being missed.
- Difficulty in Assessing Model Performance: In credit card fraud detection, if fraudulent transactions are rare, a model might achieve high accuracy by predicting all transactions as non-fraudulent. However, this high accuracy is misleading as the model fails to identify the rare but important fraudulent cases
- Tendency to Overfit Majority Class: In predictive maintenance for machinery, if data on machine failures (minority class) are scarce compared to normal operation data (majority class), the model may overfit to the normal operation patterns and fail to predict failures accurately.
- Risk of Model Bias: In hiring algorithms, if the dataset contains more examples of successful candidates from a certain demographic, the model might develop a bias towards that demographic, leading to unfair hiring practices.
- Balancing Precision and Recall: In legal document analysis for identifying relevant documents, it’s crucial to balance precision (ensuring documents identified are relevant) and recall (ensuring all relevant documents are identified), as both false positives and false negatives carry significant consequences.
Techniques for Handling Class Imbalance
Class imbalance may not always impact performance, and using imbalance-specific methods can sometimes worsen results. Xu-Ying Liu, Jianxin Wu, and Zhi-Hua Zhou, Exploratory Undersampling for Class-Imbalance Learning
Above said, there are different techniques such as the following for handling class imbalance when training machine learning models with datasets having imbalanced classes.
- Class weighting: Using class weight is a common method used to address the class imbalance in machine learning models. Class imbalance occurs when there is a discrepancy in the number of observations between classes, often resulting in one class being over-represented relative to the other. The idea behind class weighting is to assign different weights to each class during the training phase so that the contribution of each class is balanced. The weights assigned to each class are typically inversely proportional to their frequency in the dataset. For example, if a dataset has two classes, A and B, with class A occurring more frequently than class B, then the weight assigned to class A would be lower than the weight assigned to class B. This means that during training, the algorithm will pay more attention to class A and less attention to class B, ensuring that both classes are given equal importance. This means that class weighting adjusts the cost function of the model so that misclassifying an observation from the minority class is more heavily penalized than misclassifying an observation from the majority class.
There are several ways to assign weights to different classes, and the specific method used depends on the algorithm being used. For example, in the logistic regression algorithm, weights can be assigned using the class_weight parameter. In the decision tree algorithm, weights can be assigned by modifying the splitting criterion to favor the minority class. If the weights are not chosen appropriately, the model may become biased towards one class and may perform poorly on the other. Cross-validation techniques can be used to find the optimal weights for each class.
One of the benefits of class weighting is that it is a simple and effective way to handle class imbalance without requiring any additional data or preprocessing steps. It can also be easily implemented in most machine learning algorithms. However, it may not work well in extreme class imbalance scenarios, where the minority class is significantly smaller than the majority class. In such cases, other techniques, such as resampling or synthetic sampling, may be more effective.
This approach can help to improve the accuracy of the model by rebalancing the class distribution. However, it is important to note that class weighting does not create new data points, and it cannot compensate for a lack of data. As such, it should be used in conjunction with other methods, such as oversampling. - Under-sampling data related to majority class: Under-sampling is a common technique used to address the issue of class imbalance in machine learning models. Class imbalance occurs when the training data is not evenly distributed between classes, which can lead to biased models. Under-sampling involves randomly removing samples from the majority class with or without replacement until the class distribution is more balanced. This can be done either before or after splitting the data into train and test sets. This is also called random undersampling. Although under-sampling can improve model performance, it may also reduce the overall accuracy of the model if the minority class is very small. Therefore, it is important to carefully consider whether under-sampling is the right approach for your data set.
- Over-sampling data related to minority classes: Oversampling is a technique used to solve the class imbalance problem in machine learning models. It involves randomly selecting samples from the minority class and replicating them until the classes are balanced. This technique can improve the performance of machine learning models because it ensures that the model is trained on data that is representative of the test data. Moreover, oversampling can also help to reduce the variance of the model, which can further improve performance. This technique is especially useful when the dataset is small and there is a danger of overfitting. By oversampling, we can ensure that the model is trained on a balanced dataset and that all classes are represented equally.
- Synthetic sampling: Synthetic sampling is a technique used to address class imbalance in machine learning models by generating new synthetic samples from the minority class. The idea behind synthetic sampling is to create new samples that are similar to the minority class, thus increasing the representation of the minority class in the dataset. One of the most widely used algorithms for synthetic training examples is Synthetic Minority Over-sampling Technique (SMOTE). SMOTE works by creating new synthetic data samples that are similar to existing data samples in the minority class based on finding its k nearest neighbors. These synthetic data samples can then be used to train the machine learning model, providing a more balanced training set. In addition, SMOTE can also help to improve the generalizability of the model by increasing the number of training examples.
For example, let’s say we have a dataset of credit card transactions where the majority of transactions are legitimate and only a small percentage are fraudulent. This leads to class imbalance, with the minority class being “fraudulent transactions.” We can use SMOTE to generate synthetic samples of fraudulent transactions by selecting a fraudulent transaction and finding its k nearest neighbors (legitimate transactions). SMOTE then creates new synthetic fraudulent transactions by randomly selecting one of the k neighbors and generating a new sample at a point along the line between the original sample and its selected neighbor.
Python packages such as Imbalanced Learn can be used to apply techniques related to under-sampling majority classes, upsampling minority classes, and SMOTE. In this post, techniques related to using class weight will be used for tackling class imbalance.
How to create a Sample Dataset having Class Imbalance?
In this section, you will learn about how to create an imbalanced dataset (imbalance class distribution) using the Sklearn Breast cancer dataset. Let’s take the Sklearn data set representing to breast cancer. Although the class distribution is 212 for malignant class and 357 for benign class, an imbalanced distribution could look like the following:
Benign class – 357
Malignant class – 30
This is how you could create the above mentioned imbalanced class distribution using Python Sklearn and Numpy:
from sklearn import datasets
import numpy as np
bc = datasets.load_breast_cancer()
X = bc.data
y = bc.target
X_imb = np.vstack((X[y == 1], X[y == 0][:30]))
y_imb = np.hstack((y[y == 1], y[y == 0][:30]))
The above code creates a new Numpy array by appending 30 records vertically (numpy vstack method) whose label is 0 (malignant) to the 357 records whose label is 1 (benign) taking the total record count to 387. Similarly, it appends 30 malignant labels to 357 benign labels horizontally (numpy hstack method).
Handling Class Imbalance using Class Weight – Python Example
In this section, you will learn about techniques that can be used for handling class imbalance while training the models using Python Sklearn code. Every classification algorithm has a parameter namely class_weight. The different type of inputs to this parameter allows you to handle class imbalance using a different manner. By default, when no value is passed, the weight assigned to each class is equal e.g., 1. In case of class imbalance, here are different values representing different types of inputs:
- balanced: When passing balanced as class_weight results in the values of y (label) automatically adjusting weights inversely proportional to class frequencies in the input data. The same can be calculated as n_samples / (n_classes * np.bincount(y))
- {class_label: weight}: Let’s say, there are two classes labeled as 0 and 1. Passing input to class_weight as class_weight={0:2, 1:1} means class 0 has weight 2 and class 1 has weight 1.
In the code sample given below, the class_weight of format {class_label: weight} is illustrated. Watch out the code,
pipeline = make_pipeline(StandardScaler(), LogisticRegression(random_state=1, class_weight={0:3, 1:1}))
#
# Create training and test split out of imbalanced data set created above
#
X_train, X_test, y_train, y_test = train_test_split(X_imb, y_imb, test_size=0.3, random_state=1, stratify=y_imb)
#
# Create pipeline with LogisticRegression and class_weight as {0:3, 1:1}
#
pipeline = make_pipeline(StandardScaler(), LogisticRegression(random_state=1, class_weight={0:3, 1:1}))
#
# Create a randomized search for finding most appropriate model
#
param_distributions = [{'logisticregression__C': sc.stats.expon(scale=100)}]
rs = RandomizedSearchCV(estimator=pipeline, param_distributions = param_distributions, cv = 10, scoring = 'accuracy', refit = True, n_jobs = 1,random_state=1)
#
# Fit the model
#
rs.fit(X_train, y_train)
#
# Find the best score, params and accuracy on the test dataset
#
print('Best Score:', rs.best_score_, '\nBest Params:', rs.best_params_)
print('Test Accuracy: %0.3f' % rs.score(X_test, y_test))

Conclusions
Here is what you learned about handling class imbalance in the imbalanced dataset using class_weight
- An imbalanced classification problem occurs when the classes in the dataset have a highly unequal number of samples.
- Class imbalance means the count of data samples related to one of the classes is very low in comparison to other classes.
- One of the common techniques is to assign class_weight=”balanced” when creating an instance of the algorithm.
- Another technique is to assign different weights to different class labels using syntax such as class_weight={0:2, 1:1}. Class 0 is assigned a weight of 2 and class 1 is assigned a weight of 1
- Other popular techniques for handling class imbalance in machine learning classification problems include undersampling of the majority class, oversampling of the minority class, and generating synthetic training examples (SMOTE).
- Python packages such as Imbalanced Learn can be used to implement techniques such as SMOTE, undersampling of majority class, and oversampling of the minority class.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me