Last updated: 3rd Jan, 2024
Machine learning is a machine’s ability to learn from data. It has been around for decades, but machine learning is now being applied in nearly every industry and job function. In this blog post, we’ll cover a detailed introduction to what is machine learning (ML) including different definitions. We will also learn about different types of machine learning tasks, algorithms, etc along with real-world examples.
What is machine learning & how does it work?
Definition 1: Simply speaking, machine learning can be defined as an approach to model our beliefs about real-world events. For example, let’s say a person came to a doctor with a certain blood report. A doctor based on his belief system learned using his/her experience & knowledge, predicts (decides essentially) whether the person is suffering from a disease or otherwise. When the human belief system is not good enough for reasons such as evaluating a large amount of different data to arrive at a decision, we can, then, replace “human belief system” with a AI / machine learning system (one or more models) and “experience and knowledge” with data which is fed into this AI / ML system. Doctors can as well use ML models trained using past data along with his experience & intelligence to predict whether the person suffers from a disease or not.
When human and machine learning intelligence is used in combination, it is also termed as an augmented system. When the system can rely solely on the AI-based decisions, the system can be called as an autonomous system. How well these beliefs correspond with reality is what is learned by the doctor over a period of time. In the machine learning world, we have a “cost function” or “loss function” that is learned to ensure that the prediction is closer to reality.
Definition 2: Technically speaking, machine learning can be defined as a technology where in machine learns to perform a prediction/estimation task based on past experience represented by a historical data set. There are three key aspects of machine learning which are the following:
- Task: Task can be related to prediction problems such as classification, regression, clustering, etc.
- Experience: Experience represents the historical dataset.
- Performance: The goal is to perform better in the prediction tasks based on the past datasets. Different performance measures exist for different kinds of machine learning problems. Read my related blog on key techniques for evaluating machine learning models.
Definition 3: Mathematically speaking, building machine learning models can be defined as an approach to approximating mathematical functions (equations) representing real-world scenarios. These mathematical functions are often referred to as “mathematical models” or just models. Machine learning models can as well be defined as mathematical equations/functions that represent or model real-world problems/scenarios. The reason why machine learning models are called function approximations is because it will be extremely difficult to find exact functions which can be used to exactly represent the real-world and predict or estimate real-world scenarios. Here is an illustration of simple mathematical function which can be learned using the data.
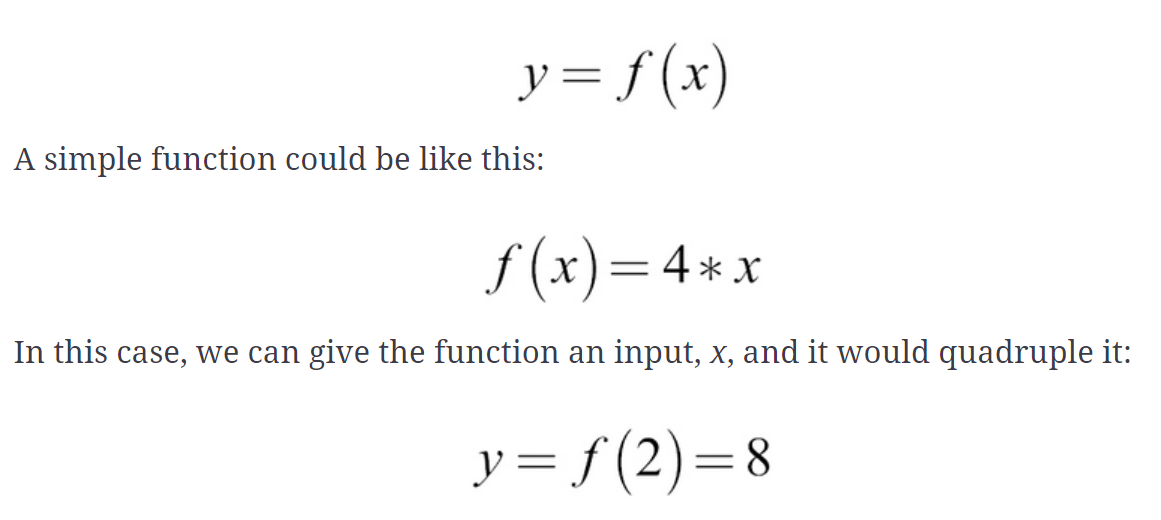
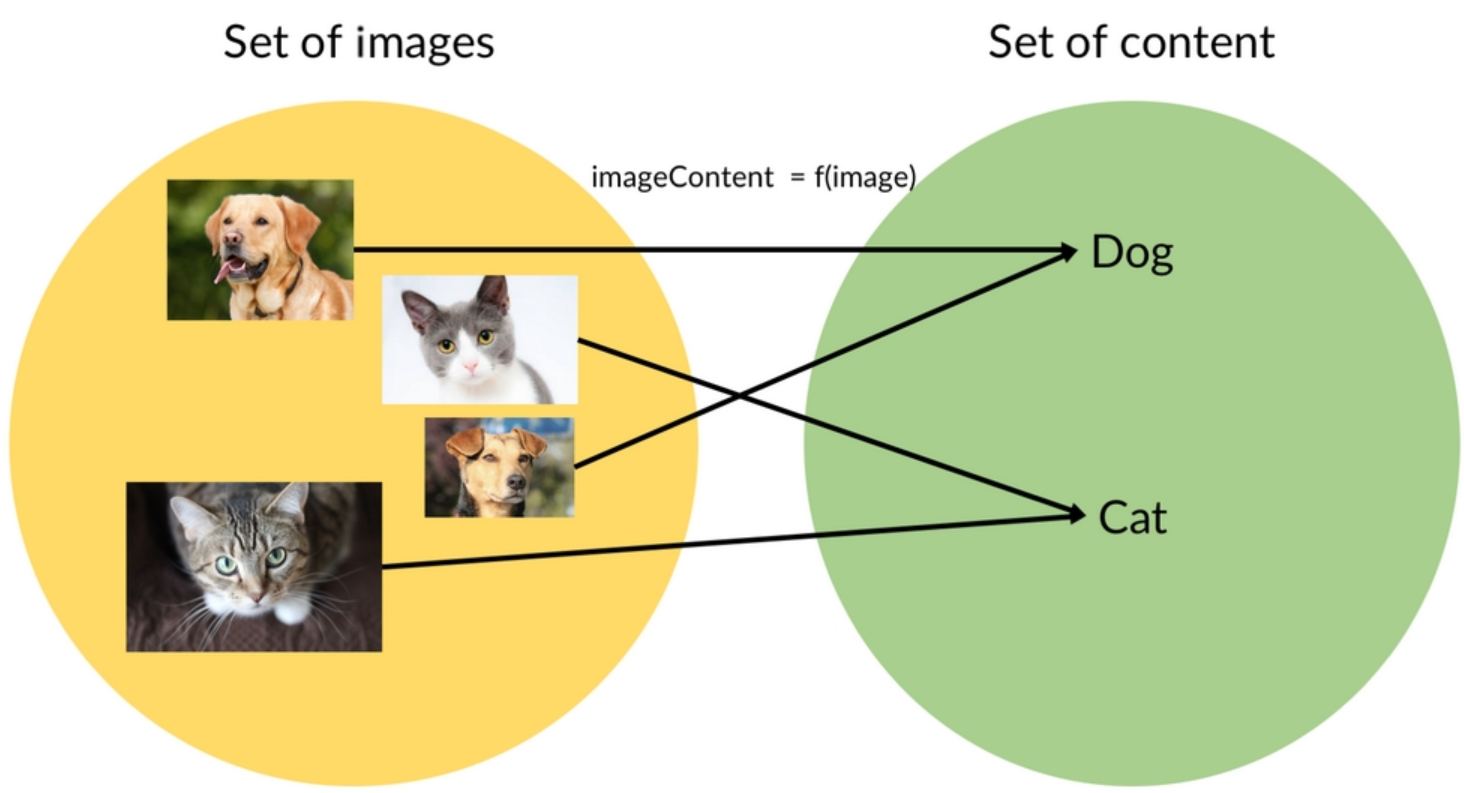
The function could as well be used to map the image to the image content or label. Here is the illustration:
imageContent = f(image)
The picture below represents how the above function could be used to map cat in the picture to cat and dog in the picture to dog.
The diagram below represents two different kinds of mathematical functions, one representing the line (left) that divides the data points, and the other representing the line (right – regression) which can be used to predict the data points. The left line represents the decision boundary of classification function or model which is learned with the given data points. The right line (regression – best fit line) can be called a regression function or model which is learned from the given data points.

Models can be reduced to mathematical functions that map an input (the observed data) to a result (the predictions). Some mathematical functions are more complex than others, in the number of internal parameters they have and in the ways they use them. – The Kaggle Book
Here is the philosophical way to look at machine learning.
Definition 4: Machine learning can be defined as a technology that can be used to create a “mathematical form” or “mathematical being” or a “machine” that is capable to perform certain pre-defined tasks (estimate or predict) given a set of inputs. The “mathematical form” or the “machine” is composed of a set of levers that work together to create a pre-defined desired output. The “levers” can be thought of as “features”. How the “mathematical form” or “machine” needs to work together depends upon different algorithms called machine learning algorithms. Different “machines” or models get created based on the historical dataset and different algorithms. These “mathematical forms” are created by what we call “data scientists” or machine learning engineers. And, there are well-defined processes and tools that can be used for creating these “machines” (training/testing process). The most fundamental aspects of building machine learning models include computations based on the given data, that can be used to learn to build a model representing real-world problems/scenarios.
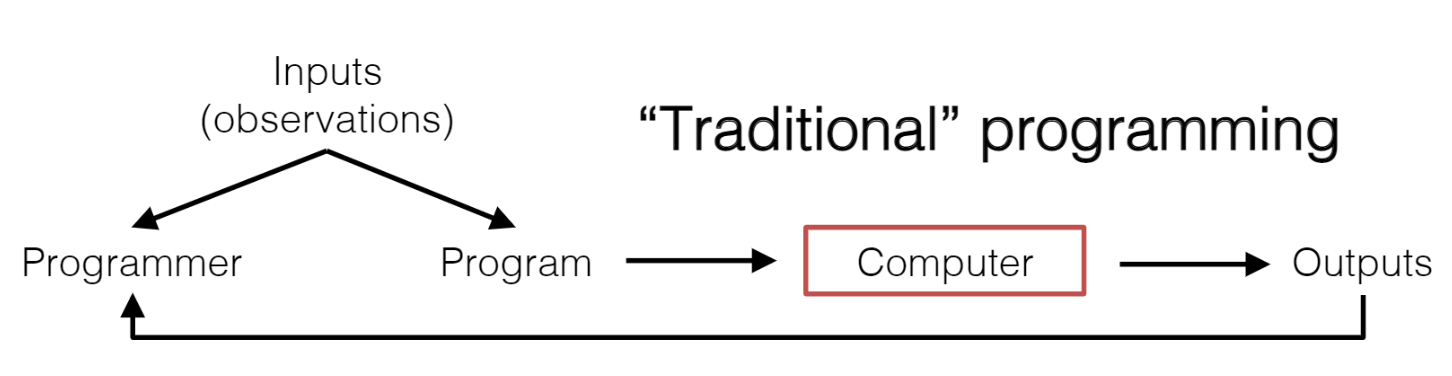
Machine learning is different from traditional programming in the way that the output in the case of machine learning is the rules based on which predictions are made whereas the input is answered (labels) and data. Input and output data are used with machine learning algorithms to output rules/programs (model). The picture below represents this difference:
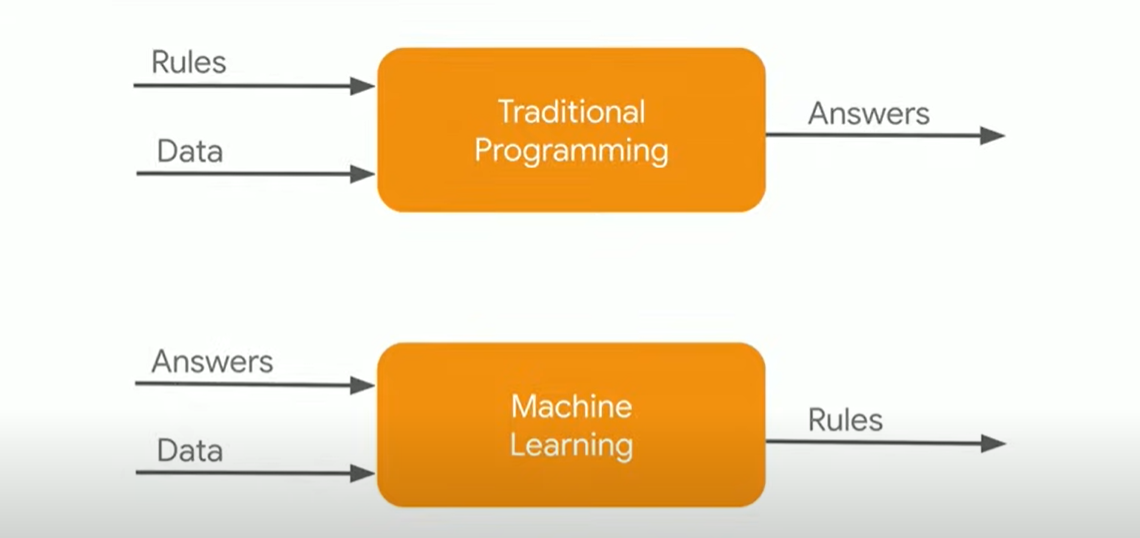
Fig 1. Difference between Machine learning and traditional programming
Here is another way of looking at how machine learning is different than the traditional programming:

The diagram below represents machine learning models in the training and inference (prediction) phase.
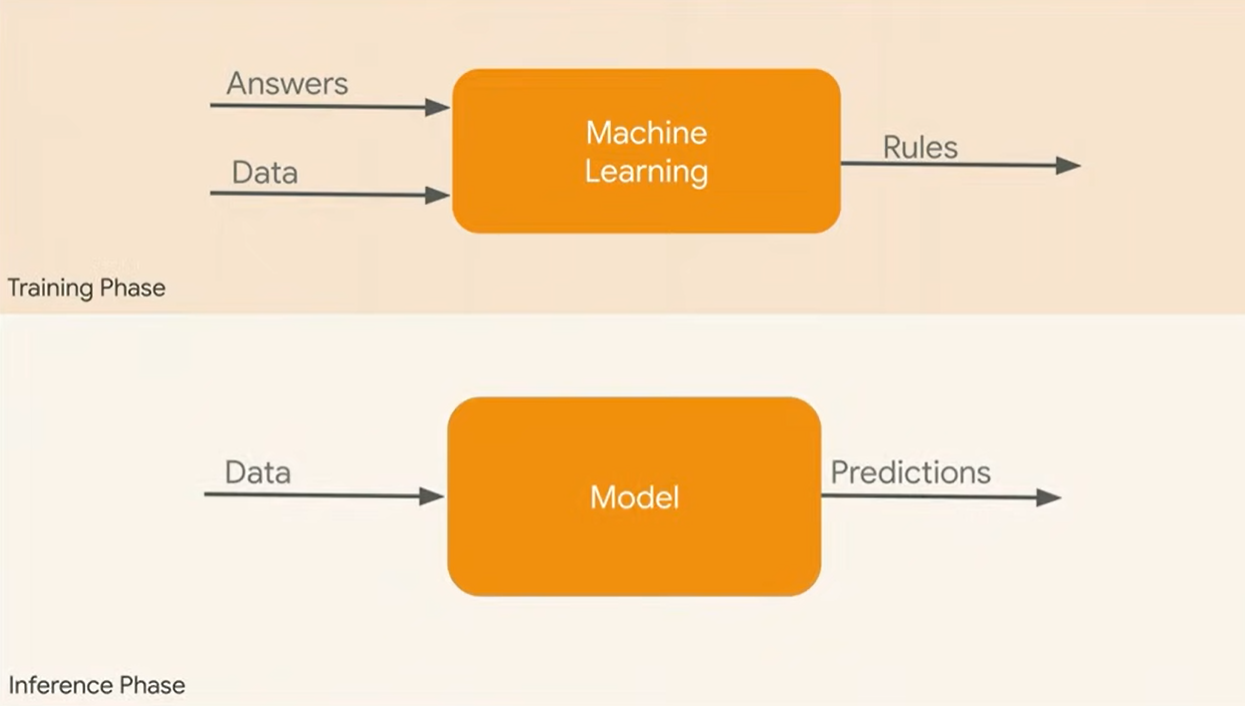
Fig 2. Machine learning models used for predictions
Check out my related blog on machine learning terminologies for beginners. You may also want to check out the following video from Google:
Machine learning is also referred to as deep learning depending on the algorithms used to build the models. When neural network algorithms are used, model building is termed deep learning.
How do we come up with the approximate functions or machine learning models?
The following represents different aspects related to how machine learning models are trained for making predictions. The diagram below represents supervised learning models where the training data consists of features information and related labels. The training data is used to train the model which them makes prediction (prediction labels) on the test data.
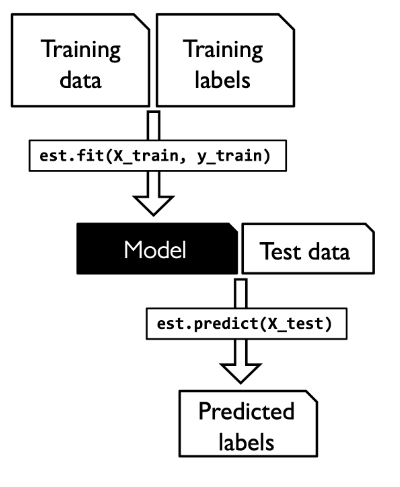
There are eight key components of a machine learning model.
- Data: The most fundamental aspect of building a machine learning model is data or historical data. The data can also be termed as experience when referring to the learning aspect of building models.
- Algorithms: Different algorithms can be used for solving different types of problems such as regression, classification, or clustering. Based on the problem, appropriate algorithms can be used to train one or more models.
- Mathematical model/function (approximation): These are the actual functions that are learned from the data. Examples of machine learning functions or models are simple linear equations or multi-linear equations.
- Output variable: This is also called a dependent variable or response variable. This is the variable we want the machine learning model to predict or estimate.
- Input variables/features: These represent the input data that you feed into machine learning models or mathematical equations in order for it to learn the parameters/coefficients (third aspect) and make predictions about your output: dependent variable. These variables are also called independent variables or predictor variables. These are also called as features.
- Parameters/coefficients: These are the coefficients of mathematical equations (models) that machine learning algorithm will learn based on the historical data and the loss or cost function.
- Hyperparameters: Hyperparameters are different from the parameters. Hyperparameters are the machine learning model’s initial configuration or setting that you need to determine before training machine learning models. These are parameters which are used with loss function or cost function during training for estimating the parameters discussed in the earlier point. You will use hyperparameters as input for the loss function which will return a set of machine learning parameters/coefficients with different values based on your chosen hyperparameter settings.
- Loss or cost or objective function: The loss function is a way of measuring how accurate machine learning model’s predictions are. The loss function takes in machine learning parameters/coefficients and the predicted output variable, compares them with the actual value (training data) for that particular set of machine learning parameter settings, then returns a number that is used to adjust or update machine learning parameters so that final outcome of machine learning model will be more accurate. Loss function measures the loss for every prediction – how far the prediction is from the actual value. The loss function is also called a cost or objective function. The idea is to minimize the loss of the objective function. In another word, the optimization of objective function results in the selection of the most appropriate parameters and hyperparameters of machine learning models.
Here is another view of how a machine learning model is trained and tested based on supervised learning.
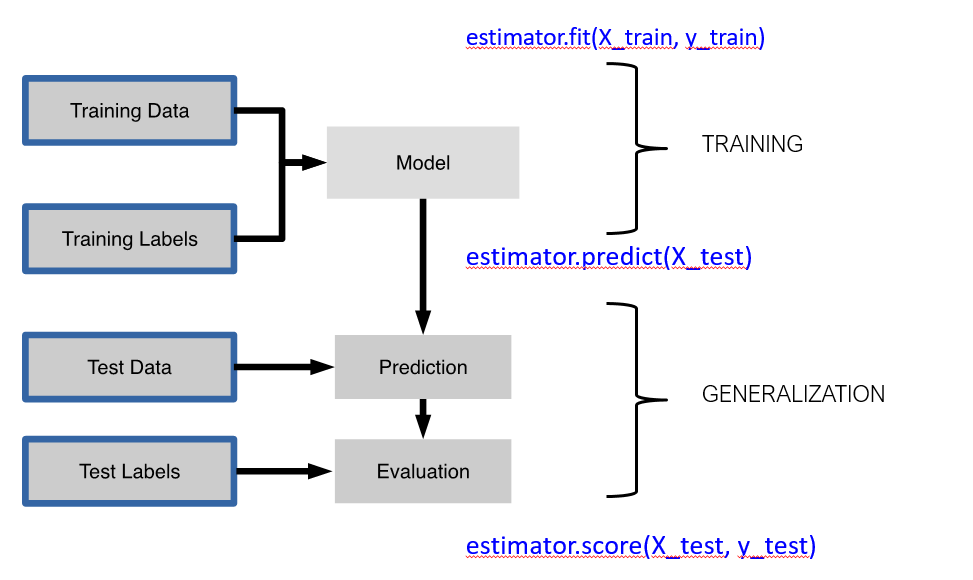
Based on the above, one can understand how machine learning models are built for supervised learning problems. There are two functions involved in machine learning. One is a function (approximation) representing a machine learning model and the other is an objective function that needs to be optimized. While optimizing the objective function, the parameters and hyperparameters are learned.
What are some simple examples of machine learning models?
The following are some of the examples of machine learning models or function approximations:
- Y = mX + b + error: This is a simple linear regression model/equation which is used to predict or estimate the value of Y for a given value of variable X. Y is the observed value. In this model, we will need a loss function or cost or objective function to determine the value of the parameter, m, and b. The loss function popularly used is called a mean square loss. What is needed is data to use the loss function to estimate the parameters.
- Y = a1*X1 + a2*X2 + a3*X3 + b + error: This is a multi-linear regression model. Here, X1, X2, and X3 are independent or predictor variables, Y is the observed value, and b is bias.
- Y = a1X1*sin(X1) + a2X2 + error: You may note that this looks to be a non-linear regression model.
Why / When Use Machine Learning?
When human intelligence is not good enough to make decisions based on past experience and available data, one can rely on artificial intelligence to help make decisions. When the decisions (based on the predictions) need to be made based on large number of parameters which makes it difficult for humans, machine learning can be used. Artificial intelligence systems such as the machine learning systems comprising of one or more models help make predictions by learning from historic data set. That said, the decisions made based on the output (predictions) of machine learning models need to be monitored over a period of time in order to adopt the ML system across the enterprise. This aspect of decision making driven by the data is also called as data-driven decision-making and ML systems play a key role in this.
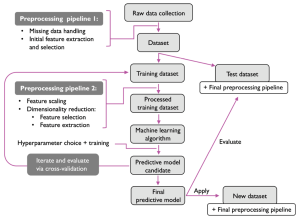
Stages of Training Machine Learning Models
The following represents some of the key stages in which machine learning models are trained, deployed, and monitored. Check out the related post.
- Data collection
- Data preparation and processing
- Feature engineering
- Feature selection / extraction
- Model building
- Model evaluation
- Algorithm selection
- Model selection
- Model deployed in hyper care mode
- Model goes live
- Model retraining based on constant performance evaluation
Here is a diagram representing different stages of building machine learning models.
The following is the detailed workflow for building machine learning model. The image is taken from the book, Machine Learning with PyTorch and Scikit-Learn. This is a great book if you would like to learn about machine learning concepts with PyTorch and Scikit-learn.

Machine Learning Algorithms & Types
Machine learning algorithms are algorithms that are used to solve a different kinds of problems by learning machine learning parameters, hyperparameters, etc. The following are different kinds of machine learning algorithms:
- Regression algorithms: Regression algorithms are used for machine learning problems where the model has to predict/estimate the value of a continuous variable. Regression machine learning algorithms are used for both types, namely supervised and unsupervised machine learning problem sets. Examples of regression algorithms include linear regression, decision tree regression, Ridge/Lasso Regression, random forest, gradient boosting algorithms, support vector machine regressors, etc. Example of regression problems includes stock price prediction, housing pricing prediction, payment-related predictions such as payment delay, etc.
- Classification algorithms: Classification algorithms are used for machine learning problems where the model has to predict/estimate the value of a discrete variable. The discrete response variable can represent the category or class of data. Examples of classification algorithms include logistic regression, random forest, decision tree classifier, gradient boosting algorithms, support vector machine (SVM) classifier, etc. Examples of classification problems include medical or disease diagnosis, and weather forecasting.
- Clustering algorithms: Clustering algorithms machine learning algorithms are used for machine learning problems where the machine has to identify patterns in data. Examples of clustering machine learning algorithms include the K-means algorithm, hierarchical clustering, Gaussian mixture model, etc. Examples of clustering algorithms include customer segmentation, market segmentation, etc.
- Recommendation algorithms: Recommendation machine learning algorithms are used where the model has to predict/estimate whether a given item is likely to be liked or bought by other users based on their behavior, purchase history etc. These machine learning algorithm types can also be called content-based machine learning algorithms. Examples of recommendation machine learning algorithms include user-based collaborative filtering, item-based collaborative filtering etc.
- Reinforcement learning algorithms: Reinforcement learning algorithms are one that learns/optimizes to respond appropriately to a given environment. Examples of reinforcement learning algorithms include Q-learning algorithm, SARSA, policy gradient machine, etc.
- Deep learning algorithms: Deep learning algorithms are machine learning algorithms that makes use of the multi-layered neural network to solve machine learning problem. Examples include deep neural networks, recurrent neural networks, long short-term memory, deep belief networks etc.
- Dimensionality reduction algorithms: The dimensionality reduction machine learning algorithm is one that reduces the number of dimensions (variables) without losing much information from the variables under consideration. Examples of dimensionality reduction algorithms include principal component analysis (PCA), singular value decomposition, etc.
Difference: Machine Learning Algorithms vs Models
Machine learning algorithms are used to train one or more machine learning models having different parameters and hyperparameters. Model selection techniques are then used to select the most appropriate machine learning model from the set of machine learning models that have been trained. Note that the most appropriate machine learning model is the one that generalizes well to the unseen data.
A problem can be solved using different machine learning algorithms and for each machine learning algorithm, there can be multiple different models. One can go for algorithm and model selection techniques to select the most appropriate algorithm and model.
Types of Machine Learning Tasks
The following are the five most common types of machine learning tasks:
- Supervised learning: Supervised learning is a machine learning task where we have data with both inputs and correct labels/answers/output. We also know the correctness of answers based on labels or tags attached to them during training phase. For example, you can take a set of images tagged as “cat”. You train a machine learning model with these cat pictures so that machine learning model learns how to distinguish if an image is a cat or not.
- Unsupervised Learning: Unsupervised machine learning is machine learning task where we don’t have data with correct answers/labels and input variables also contain incorrect/noisy values during training phase. For example, if you take images of people without their labels attached to them for the machine learning model to learn from them so the machine learning model can correctly classify images of people when the machine learns from data with incorrect labels.
- Reinforcement Learning: Reinforcement machine learning is machine learning task where machine learn how to act in different scenarios by receiving rewards or punishment for its actions. The reward function determines if an action taken was correct and the punishment function tells whether that action will result in loss.
- Semi-supervised learning: Semi-supervised learning tasks are machine learning tasks where data has both labeled and unlabelled examples. Semi-supervised machine learning helps us in obtaining labels for example, images that are not labeled yet or have incorrect/inconsistent tags. Various types of problems arising in
applications, including classification, regression, or ranking tasks, can be framed as instances of semi-supervised learning. - Self-supervised learning: In the case of self-supervised machine learning tasks, data does not have any correct/incorrect labels. In other words, input variables are random or a subset of all possible inputs to the machine learning model and the model learns to create its own labels from noisy data.
How’s Machine Learning related to Deep Learning, AI, and Data science?
AI is a much broader field that includes machine learning. Machine Learning can be called a subset of Artificial Intelligence which deals specifically with using algorithms that can learn from data without being explicitly programmed.
Deep learning can be called a subset of machine learning which deals with algorithms that can learn from data using many hidden layers in the model. Deep learning is used to learn the complex representations of data which helps build better machine learning models. Note that another word for representation is the feature. Better selection of features or representations can result in better models and this is where deep learning comes of great help. Complex problems related to image classifications, machine translations, natural language processing tasks, etc. can be solved using deep learning algorithms.
Data science is a field that includes machine learning/deep learning, linear algebra, probability and statistics, and computer programming. Data scientists are people who apply machine learning algorithms to large datasets to create useful products from the data like predictive models etc. Read a detailed post on what is data science?
Do I need to know programming languages to implement AI / ML?
The answer is Yes and No. If you are a data scientist who is very familiar with programming, you could use programming languages like Python, R, or Julia to implement machine learning algorithms. However, product managers and/or machine learning engineers usually use tools and libraries which can be used without programming languages so they don’t need to be familiar with the programming language data scientists use for the implementation of machine learning models.
There are various cloud services that have machine learning algorithms implemented in them so you don’t need to know how they are working internally. Some machine learning tools and libraries include TensorFlow, Scikit-learn, etc. These machine learning tools can be used with programming languages or without knowing any language making it easy for product managers/machine Learning engineers who want to create predictive models. You might want to check services such as Google cloud bigquery ML which makes it so easy to train the model.
The following are different popular cloud services that provide machine learning algorithms implemented in them so you don’t need to know how machine learning models are working internally.
- Google Cloud ML services
- Amazon Machine Learning services: Check out my related post on 20 machine learning services on Amazon cloud.
- Azure ML services
Skills required to get started with Machine Learning
Those who build machine learning models are called data scientists. People who are data scientists usually have the following skills/knowledge:
- Machine learning algorithms
- Statistics and probability
- Mathematics topics such as linear algebra
- Good understanding of business problems
- Good programming skills in languages like Python, R, etc. which can be used for machine learning implementation. Good with SQL knowledge to get data from the RDBMS database. That said, there are several cloud-based data democratization tools that can be used to get access to the data if the data resides in the data lake.
- In case you are not good with programming, you could learn cloud ML services such as Google, Amazon and Azure cloud ML services.
- Communication skills such that the insights could be shared with stakeholders such as product managers, product owners, etc.
Automated Machine Learning
Automated machine learning (AutoML) is the automation of building machine learning models. AutoML automates different machine learning tasks in machine learning workflow such as data cleaning, feature engineering, hyperparameter tuning, etc. such that data scientists could focus on business problems and making machine learning models better instead of spending time on the tedious machine learning tasks. There are different AutoML libraries available for machine learning problems such as Auto-sklearn, H20.ai, etc.
Machine learning is a subset of artificial intelligence that deals specifically with machine learning algorithms that are able to learn from data without being explicitly programmed. Data Science, Deep Learning, and Machine Learning are all related but have different purposes – deep learning is focused on machine algorithms that can learn from data using many hidden layers while machine learning focuses more broadly on machine algorithm’s ability to learn by itself. Another class of learning is reinforcement learning which trains agents to act in different scenarios by receiving rewards or punishment for their actions; this type of machine learning allows machines to make decisions based on what will give them the most reward. There are machine learning tools and libraries which can be used without programming languages making it easy for product managers, machine learning engineers and data scientists/analysts to create predictive models by using machine learning algorithms that learn from data partially or fully labeled. If you are looking to learn more about machine learning and different applications, please reach out to us.!

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me