Are you curious about how AI / machine learning is revolutionizing the underwriting process? Have you ever wondered how machine learning models are reshaping risk assessment and decision-making in industries like insurance, lending, and securities? Underwriting has long been a critical process for assessing risks and making informed decisions, but with the advent of machine learning, the possibilities have expanded exponentially. By harnessing the immense capabilities of machine learning algorithms and the abundance of data available, organizations can extract actionable insights, achieve higher accuracy, and streamline their underwriting practices like never before. In this blog, we will learn about how machine learning models can be used effectively for underwriting processes, uncovering real-world examples that showcase the power of this convergence.
Underwriting Explained with Examples
Underwriting is the process of evaluating risks, assessing creditworthiness, and making informed decisions in various industries, including insurance, lending, and securities. It involves analyzing relevant data, such as financial information, credit history, market trends, and other factors, to determine the terms, conditions, and pricing of a financial product or service. The goal of underwriting is to manage and mitigate potential financial losses by evaluating the level of risk associated with a particular transaction or investment.
In insurance underwriting, for example, underwriters assess the risks involved in insuring a person, property, or event. They evaluate factors such as the applicant’s health status, past claims history, location, and other relevant information to determine the appropriate premium, coverage limits, and deductibles. By thoroughly examining these risk factors, underwriters ensure that the insurance policy aligns with the risk profile and adequately protects against potential losses.
In lending, underwriting involves assessing the creditworthiness of borrowers to determine their eligibility for loans. Underwriters analyze factors such as credit scores, income, employment history, and debt-to-income ratios. Based on this evaluation, they determine the loan amount, interest rate, and repayment terms. For example, a mortgage underwriter evaluates the risk associated with a home loan application, considering factors such as the borrower’s credit history, down payment amount, and the property’s appraised value. This assessment helps in determining the loan’s approval, interest rate, and other terms to mitigate the risk of default.
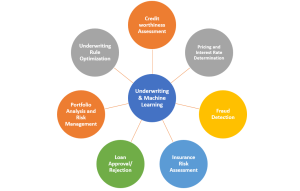
Underwriting & Machine Learning Modeling Use Cases
Underwriting processes are leveraging predictive modeling / machine learning models for transforming the way risks are evaluated and decisions are taken across different industries. By leveraging the capabilities of machine learning algorithms, organizations are extracting valuable actionable insights from large datasets, automating complex processes, and achieving more accurate risk evaluations. Let’s explore the how machine learning models are becoming game changers for underwriting processes. We will learn about different use cases, questions / decision points and how predictive analytics / machine learning models are helping take decisions.
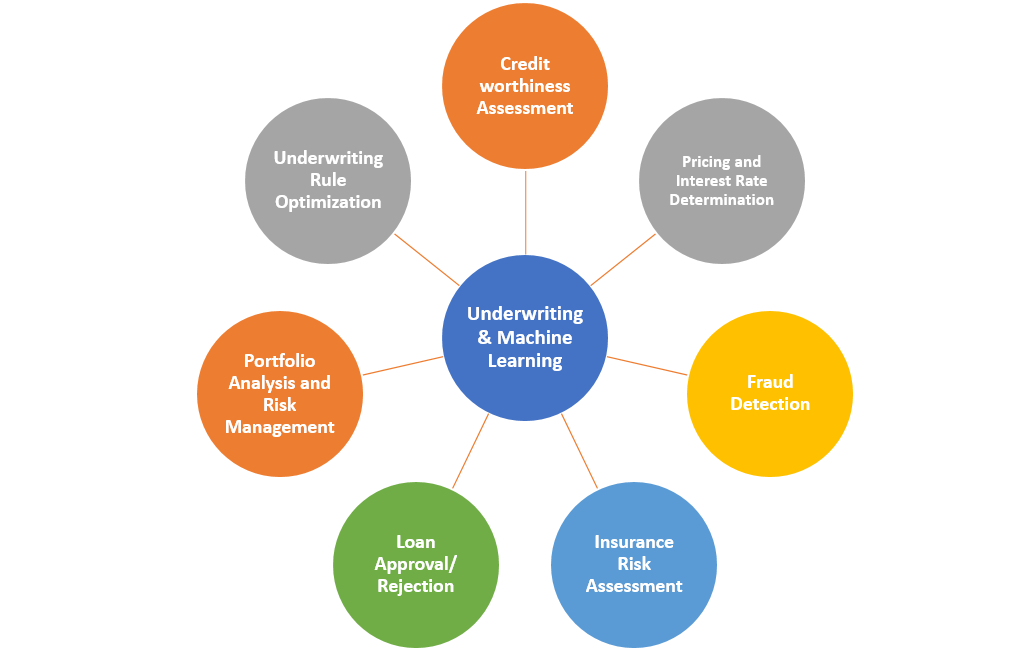
Creditworthiness assessment
Creditworthiness assessment is about evaluating the applicant’s ability to repay a loan based on their financial history, credit score, income, and other relevant factors. The questions that need to be answered are some of the following:
- What is the likelihood of timely repayments based on the applicant’s credit history?
- How does the applicant’s income and debt-to-income ratio impact their creditworthiness?
The following represents how machine learning models can help in making decisions by answering some of the above questions regarding creditworthiness assessment:
- To assess the likelihood of timely repayments based on an applicant’s credit history, machine learning models and algorithms can be employed to analyze historical data and identify patterns that correlate with repayment behavior. Logistic regression models can be used to predict the probability of timely repayments based on an applicant’s credit history. By considering variables such as previous payment patterns, credit utilization, and delinquency records, the model can estimate the likelihood of on-time repayments. This information aids underwriters in evaluating creditworthiness and making informed decisions. Gradient boosting algorithms, such as XGBoost or LightGBM, can handle complex relationships in credit data.
- Regarding the impact of an applicant’s income and debt-to-income ratio on their creditworthiness, machine learning models can provide valuable insights into this relationship. Decision tree models can analyze an applicant’s income and debt-to-income ratio to predict their creditworthiness. By splitting data based on income thresholds and debt-to-income ratio ranges, the model can classify applicants into different creditworthiness categories. This helps underwriters understand the influence of income and debt-to-income ratio on creditworthiness.
Pricing and interest rate determination
One of the key business need is setting appropriate pricing and interest rates for loans or insurance policies based on the assessed risk of default or loss. The questions that need to be answered are some of the following:
- What is the appropriate interest rate to align with the risk profile of the applicant?
- How does the applicant’s creditworthiness impact the pricing of the loan or insurance policy?
The following represents how machine learning models can help in making decisions by answering some of the above questions regarding how to determine most appropriate pricing and interest rates:
- One common machine learning modeling use case is regression analysis. Underwriters can utilize regression models to identify relationships and quantify the impact of different risk factors on pricing and interest rates. For instance, a multiple linear regression model can be employed to analyze historical data and determine how variables such as credit score, income level, loan-to-value ratio, and debt-to-income ratio affect the pricing and interest rates for loans or insurance policies.
- Another use case is the usage of decision tree models. Underwriters can construct decision tree models that split data based on different risk attributes and variables. By traversing the tree, the model can classify applicants into different risk categories, allowing underwriters to assign appropriate pricing and interest rates based on the identified risk levels. Ensemble methods, such as random forests or gradient boosting, can also be employed for higher accuracy.
Fraud detection
There is a need to identify and prevent fraudulent activities, such as false claims or misrepresentation of information. The questions that need to be answered are some of the following:
- Are there any suspicious patterns or anomalies in the applicant’s information?
- What are the indicators that suggest a potential fraudulent activity?
To detect suspicious patterns or anomalies in an applicant’s information and identify potential fraudulent activity, machine learning models and algorithms can be employed to analyze data and flag abnormal behaviors. Various machine learning techniques can be used in this context:
- Anomaly detection: Anomaly detection models, such as random forest can identify unusual patterns or outliers in the applicant’s information. By training on a dataset of normal behaviors, these models can learn to differentiate between regular and suspicious activities. Deviations from normal behavior, such as unusual transaction patterns, inconsistent information, or unexpected changes in behavior, can be flagged as potential indicators of fraud.
- Fraud scoring models: Fraud scoring models, based on techniques like logistic regression or random forests, can assign a fraud score to an applicant based on their characteristics and historical fraud patterns. By considering features such as past fraud records, behavior patterns, and demographic information, these models can calculate a risk score that indicates the likelihood of potential fraud. Higher scores indicate a higher probability of fraudulent activity.
- Network analysis: Network analysis models can examine connections and relationships between applicants and other entities to identify potential fraud networks. By analyzing social connections, transaction networks, or linkages with known fraudulent entities, these models can uncover suspicious networks and flag applicants associated with fraudulent activities. Graph-based algorithms, such as community detection or centrality analysis, can be utilized to identify patterns indicative of fraud.
- Natural Language Processing (NLP): NLP techniques can be used to analyze textual data, such as application forms or supporting documents, for indications of potential fraud. Sentiment analysis, named entity recognition, or topic modeling can be employed to identify inconsistencies, contradictory information, or suspicious statements that might suggest fraudulent intent.
Insurance risk assessment
Insurance analyst has the challenge to evaluate the potential risks associated with insuring a person, property, or event. The questions that need to be answered are some of the following:
- What is the level of risk associated with the insured property or individual?
- How does the applicant’s past claims history impact the risk assessment?
The following represents how machine learning models can help in making decisions by answering some of the above questions regarding assessment of risk associated with insuring person, property or event:
- Property risk evaluation: By considering factors such as property location, property type, age, construction quality, and historical loss data, machine learning models can assess the risk associated with the insured property. Models can analyze geospatial data, demographic information, and historical loss patterns to estimate the likelihood of perils, natural disasters, or other risks.
- Individual risk profiling: Machine learning models can evaluate various attributes of an individual, such as demographics, behavior patterns, and historical data, to estimate their risk level. Models can assess an individual’s credit history, driving record, health conditions, or other relevant factors to determine their risk profile. This analysis helps underwriters understand the level of risk associated with insuring the individual.
- Claims frequency and severity analysis: Machine learning models can analyze an applicant’s past claims data to assess the frequency and severity of their claims. By considering variables such as the number of claims filed, the cost of each claim, and the time between claims, models can quantify the impact of the applicant’s claims history on risk assessment. This analysis aids in determining the likelihood of future claims and estimating potential losses.
Loan approval/rejection
The ask from the business is to make the appropriate decision on whether to approve or reject a loan application based on the applicant’s creditworthiness and risk profile. The questions that need to be answered are some of the following:
- Is the applicant’s risk level within an acceptable range for loan approval?
- What factors contribute to the decision of approving or rejecting the loan application?
To determine if an applicant’s risk level falls within an acceptable range for loan approval, underwriters can leverage machine learning models and algorithms to assess various factors and make informed decisions. Several machine learning techniques can be applied in this context:
- Credit scoring models: Credit scoring models, such as logistic regression or support vector machines, can evaluate an applicant’s credit history, payment patterns, and other financial indicators. By training on historical data, these models can learn patterns and assign a credit score that represents the applicant’s risk level. The credit score helps underwriters determine if the applicant meets the threshold for loan approval.
- Explainable AI: Explainable AI techniques, such as rule-based models or local interpretable model-agnostic explanations (LIME), can provide insights into the factors contributing to loan approval or rejection decisions. These models can generate explanations by highlighting the most influential variables or rules that affect the decision outcome. Explainable AI aids in understanding the specific factors that drive the approval or rejection of a loan application.
Portfolio analysis and risk management
There is a constant need to analyze the overall risk exposure of a portfolio and implementing strategies to mitigate risk. The questions that need to be answered are some of the following:
- What is the level of risk in the current portfolio, and how does it align with the organization’s risk appetite?
- What risk management strategies should be implemented to minimize potential losses?
Machine learning models can play a crucial role in evaluating the level of risk in the current portfolio and aligning it with the organization’s risk appetite. Additionally, these models can aid in identifying and implementing effective risk management strategies to minimize potential losses.
- Machine learning models can analyze historical data, market trends, and portfolio characteristics to assess the level of risk in the current portfolio. By employing techniques such as clustering or classification algorithms, underwriters can group assets or customers based on risk profiles. These models can evaluate factors such as creditworthiness, payment behavior, market volatility, and diversification. By quantifying risk measures and comparing them to the organization’s risk appetite, underwriters can identify areas of the portfolio that may be overexposed or underperforming, thus helping align risk levels with the organization’s risk tolerance.
- Machine learning models can provide insights and predictions regarding future risks, enabling proactive risk management. Some strategies and techniques that machine learning models can facilitate include:
- Risk segmentation: Machine learning algorithms can segment the portfolio based on risk factors, allowing underwriters to prioritize high-risk assets or customers. This segmentation facilitates targeted risk mitigation strategies.
- Portfolio optimization: By leveraging optimization algorithms, machine learning models can help underwriters optimize the composition of the portfolio, considering risk levels and potential returns. This process aims to achieve a balance between risk exposure and performance.
Underwriting rule optimization
In order to achieve optimal performance, there is a need to refining and optimizing underwriting rules to improve accuracy, efficiency, and decision-making. The questions that need to be answered are some of the following:
- Which variables and factors are most relevant in underwriting decisions?
- How can underwriting rules be optimized to align with the organization’s risk objectives and improve overall performance?
Machine learning models can play a pivotal role in optimizing underwriting rules to align with an organization’s risk objectives and enhance overall performance. Here’s how machine learning can aid in this process:
- Rule-based optimization: Machine learning models can analyze historical data and outcomes to identify patterns and relationships between various underwriting rules and performance metrics. By assessing the effectiveness of existing rules, models can suggest modifications or updates to align with the organization’s risk objectives. For example, the model might identify specific thresholds or criteria that can be adjusted to optimize risk assessment accuracy or streamline the underwriting process.
- Feature importance analysis: Machine learning models can assess the importance of various underwriting features or variables in predicting outcomes or risk levels. By using algorithms such as random forests or gradient boosting, models can rank features based on their impact. Underwriters can utilize this information to prioritize or fine-tune underwriting rules, giving more weight to the most influential variables in achieving risk objectives.
- Automation and decision support: Machine learning models can automate the evaluation and adjustment of underwriting rules. By continuously monitoring performance, models can detect patterns, identify suboptimal rules, and suggest updates in real-time. This automation streamlines the rule optimization process and ensures that underwriting rules are aligned with risk objectives as the market conditions or risk landscape evolve.
Conclusion
The integration of machine learning into underwriting has revolutionized risk assessment and decision-making across industries. Machine learning models offer insights that enhance creditworthiness assessment, pricing determination, fraud detection, insurance risk evaluation, loan approval/rejection, portfolio analysis, and risk management. They enable accurate predictions, align risk levels with organizational objectives, and facilitate the implementation of effective risk mitigation strategies. However, challenges such as ethical considerations, data quality, interpretability, and ongoing model validation must be addressed. By embracing machine learning, underwriters can unlock new opportunities, improve decision-making, and navigate the modern business landscape with confidence.
Predictive models enable data-driven decisions, drives innovation, and fosters improved risk management practices. The future of underwriting lies in leveraging machine learning to optimize processes, enhance risk assessments, and meet evolving market demands. If you would like to learn anything specific, please drop a message and I would reach out to you.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me