When it comes to relational databases, scaling can be a difficult process. As data volume increases, the performance of the database can suffer. To ensure that your database continues to perform at its best, you must scale it properly. In this blog post, we’ll explore some of the techniques used to scaling up and scaling out the relational databases for maximum performance.
Scaling up
Scaling up (vertical scaling) of a relational database is the practice of increasing the capacity of a single server, either by adding more memory, processors, and/or storage to the existing setup. As a matter of fact, this technique can also be used for non-relational databases. This approach is best suited for databases that are relatively small and have low traffic volume. It can be used to increase performance and capacity in order to meet a company’s current needs and demands. The scaling up technique can be used for scaling databases when the database has reached its maximum capacity for a single server and needs to be expanded to support additional users or data. The following picture represents the aspect of scaling up technique:
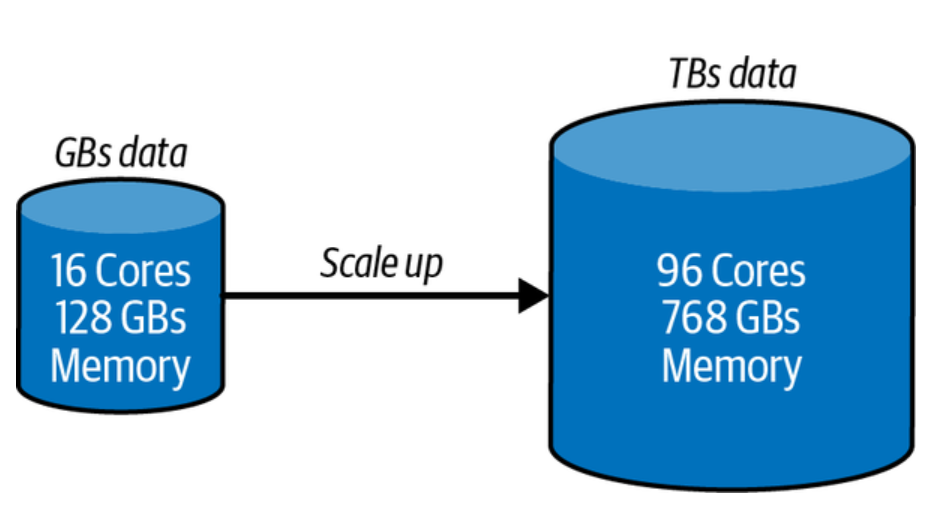
A great benefit of scaling up technique is that it is less expensive than buying an entirely new server or cluster, since only specific components such as memory, processors, or storage need to be upgraded. This makes it easier to scale up when necessary without having to invest in additional hardware and software solutions. Additionally, many databases like MySQL are designed in such a way as to allow them to take advantage of multiple CPUs and more memory which can greatly improve their performance when scaling up vertically. The scaling up technique can be an effective solution for increasing the capacity of a database in the short term, but it can become costly and difficult to manage as the database grows larger and requires more resources.
In order to properly scale up a relational database, there are several steps that need to be taken first. Some of them are the following:
- It’s important to assess what type of hardware will best suit the current needs. This ensures that any future updates or upgrades are compatible with the existing system architecture.
- Databases should be monitored closely so administrators can identify any potential bottlenecks before they become serious issues.
- Proper maintenance should be conducted regularly via backups and data integrity checks so any changes don’t cause any unexpected results or problems down the line.
- Specific guidelines should be created for how much data each component can handle so they know when it’s time to upgrade their hardware configuring accordingly so their systems can remain stable even under increased load levels over time.
Scaling out
Scaling out technique is another effective approach to scaling relational databases. This technique involves breaking down a single large database into multiple smaller and distinct databases that are distributed across different hardware or software systems. The primary benefit of this approach is that it allows for efficient use of resources by distributing the workload across multiple nodes. There are several techniques for scaling out a relational database, which allows it to handle increased workload and expand its capacity.
- Scaling out database using read replicas
- Scaling out database based on data partitioning: Partitioning data in a relational database represents distributing the database over multiple independent disk partitions and database engines across different database servers.
Scaling out through Read Replicas
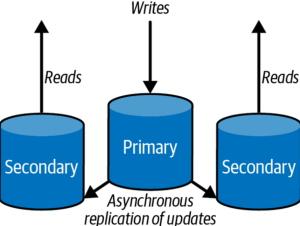
Read replicas scaling out is a technique used to scale relational databases by creating multiple copies of the same data across multiple nodes, primarily created to support data reads. Read replica scaling is often used when there is an increased demand for read operations relative to write operations. The read replica copies of database allows for more efficient querying, as well as an increase in read capacity and fault tolerance. The main database node is called as primary and read replicas are called as secondary. The picture below the read replicas.
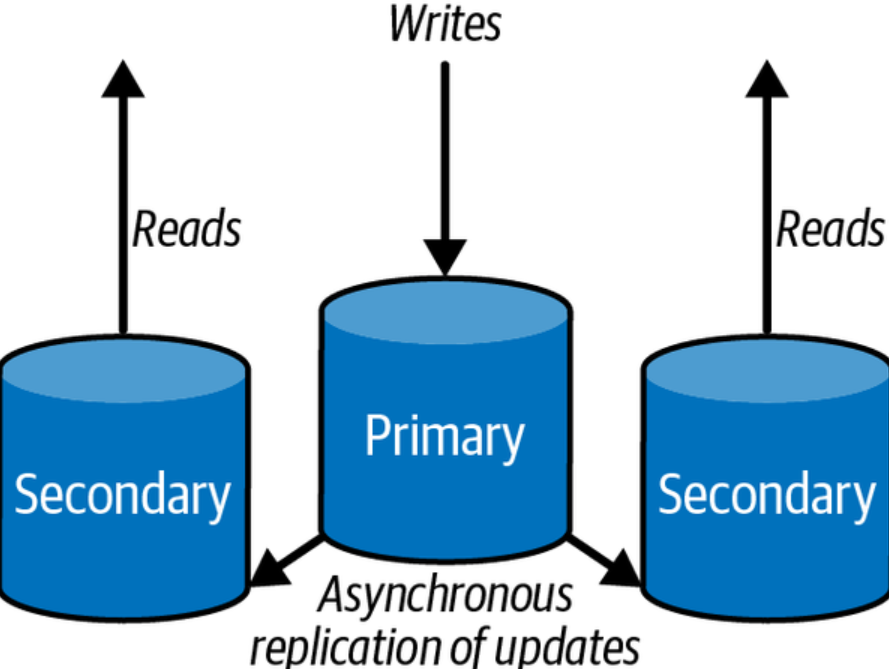
As shown in the above picture, each node contains one or more replicated copies of the same database instance. The primary instance receives all write operations from clients, while the read replicas are synchronized with the primary instance using asynchronous replication techniques such as Log Shipping or Database Mirroring. By utilizing this replication system, each node can serve both read and write requests in parallel, enabling the system to scale out horizontally with minimal performance degradation.
Scaling out – Vertical Partitioning
Vertical partitioning of databases is a data management strategy that involves breaking down a table into different sections based on the columns in a row. This provides organizations with the ability to organize and store large amounts of data efficiently and securely, as opposed to having all the data stored in one large table. This method of dividing the table can be used when certain rows contain more data than others, thereby allowing for more efficient and higher performance query execution. By separating the columns into different blocks, each block will contain only the data that is relevant to that particular query. This makes it easier for users to access the data without having to search through all of the rows at once.
Vertical partitioning allows for better index utilization by keeping frequently accessed fields together in one block and keeping infrequently accessed fields together in another block. This reduces disk I/O, which improves query response times significantly as well as overall system performance.
Vertical partitioning allows administrators to better manage large datasets by segmenting them into multiple blocks so they can be monitored more closely and managed more efficiently over time. For example, if one block contains sensitive information such as financial records or customer information, administrators can set up rules restricting access only to those who have been granted specific privileges within their organization’s access control policies.
Scaling out – Horizontal Partitioning
Horizontal partitioning of databases involves splitting a single logical table into multiple physical partitions, which can be spread across different physical nodes. Each partition contains only a portion of the data from the original table. For instance, if the original table was composed of 10 million records, it could be broken down into five separate partitions with each containing two million records. This allows individual nodes in a distributed system to access only those records that are necessary for their particular function instead of having to request all 10 million records from the central node. This greatly reduces latency and network traffic as only those records needed by the node are being requested instead of every record in the database. Additionally, when dealing with larger datasets, this approach also helps protect against scalability issues as more nodes can be added or removed from a cluster without having to modify or redeploy any code on existing nodes.
Another advantage of horizontal scaling is that it provides enhanced disaster recovery capabilities due to its ability to store data in multiple locations at once. In traditional systems where all data resides in one location, if something were to happen to one location then all data would be lost whereas with horizontal scaling each partition can exist independently allowing for one or more partitions to remain intact during an event such as a natural disaster or server failure.
Horizontal scaling also helps with improved manageability since operations can be performed on individual partitions rather than on the entire dataset at once. This makes it easier for developers and administrators alike to make changes quickly and efficiently when needed as well as providing better visibility into what’s happening within each partition at any given time.
Conclusion
Scaling relational databases is essential if you want your systems to run smoothly and efficiently when dealing with large amounts of data. Scaling up technique is useful when you need a quick fix but may not be suitable for larger operations due to hardware limitations; Scaling out using read replicas offers scalability, cost-effectiveness, and redundancy. Scaling out using data partitioning makes it easier to manage large datasets with improved query performance and reduced contention issues from concurrent accesses from multiple users or applications. All three techniques should be considered when deciding how best to scale your relational database for maximum performance and reliability.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me