In machine learning, regularization is a technique used to avoid overfitting. This occurs when a model learns the training data too well and therefore performs poorly on new data. Regularization helps to reduce overfitting by adding constraints to the model-building process. As data scientists, it is of utmost importance that we learn thoroughly about the regularization concepts to build better machine learning models. In this blog post, we will discuss the concept of regularization and provide examples of how it can be used in practice.
What is regularization and how does it work?
Regularization in machine learning represents strategies that are used to reduce the generalization or test error of a learning algorithm. Note that the goal of regularization is to reduce test or generalization error and NOT the training error. By reducing the test error, the gap between training and test error gets reduced thereby reducing the model overfitting.
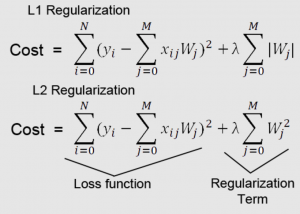
Regularization involves including constraints and penalties in the optimization process. The objective is to find the set of weights that minimize both the training error and the penalty. This can also be termed parameter norm penalty. Linear models such as linear regression and logistic regression allow for regularization strategies such as adding parameter norm penalties to the objective function. The following represents the modified objective function
[latex]Modified J(\theta; X, y) = J(\theta; X, y) + \lambda*ParamaterNorm[/latex]
Where ParameterNorm can take values such as L1 norm, L2 norm, etc, and the value of [latex]\lambda[/latex] decides on the contribution of parameter norm penalty. If the value is zero, there is no contribution from the parameter norm penalty term.
Other forms of regularization include ensemble methods that combine multiple hypotheses there by reducing generalization error.
An effective regularization method is the one that reduces variance significantly while not overly increasing bias.
Regularization is important in machine learning because it can help to improve the performance of a learning algorithm. In particular, it can help to avoid overfitting and therefore improve the generalizability of the model. Regularization can be used in conjunction with other techniques, such as cross-validation, to further reduce overfitting.
Types of regularization algorithms
There are different types of regularization algorithms, and each has its own advantages and disadvantages. The most common types of regularization algorithms are lasso, ridge, and elastic net.
- Lasso Regularization: Lasso is a type of regularization that uses L1-norm Regularization. Lasso regularization works by adding a penalty to the absolute value of the magnitude of coefficients. This forces certain coefficients to be equal to zero, which in turn helps to reduce overfitting. It is useful for feature selection, as it can help to identify which features are most important for the model. The formula given below is a representation of Lasso regularization for linear regression model. The linear regression model with the below modified cost function is also termed Lasso regression.
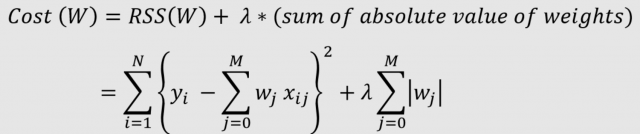
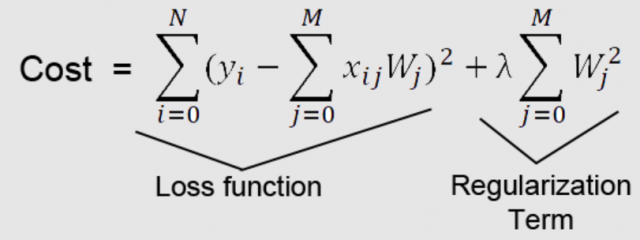
- Ridge Regularization: Ridge is a type of regularization that uses L2-norm Regularization. Ridge regularization works by adding a penalty to the square of the magnitude of coefficients. This forces all coefficients to be close to zero but does not allow them to be equal to zero. It is effective at reducing overfitting, and can also help to improve the interpretability of the model. The formula below represents the modified cost function of the linear regression model with L2 norm or L2 regularization. The linear regression model with a modified cost function is called the Ridge regression model.
- Elastic net Regularization: Elastic net is a type of regularization that combines L1-norm Regularization and L2-norm Regularization. It is effective at both reducing overfitting and improving interpretability.
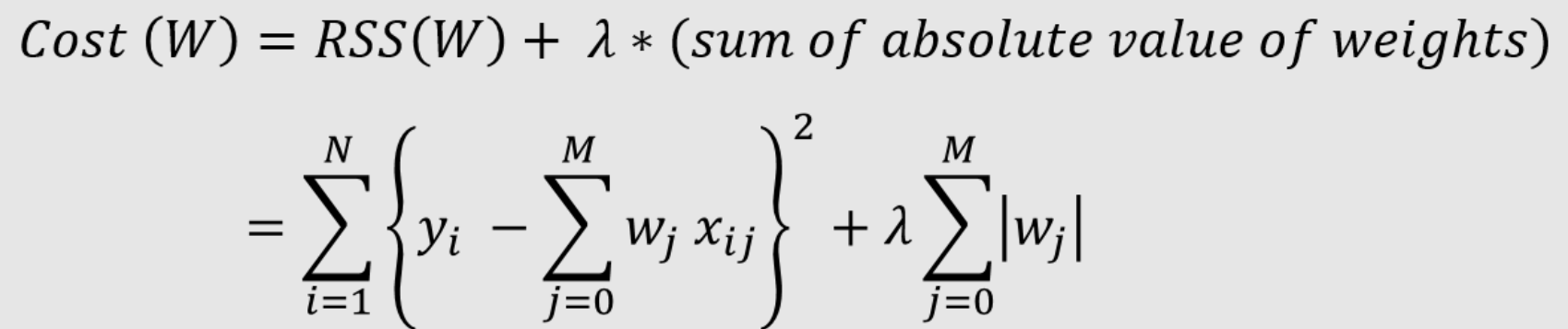
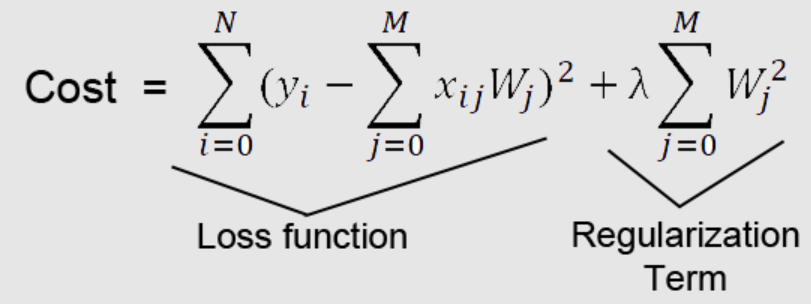
Different types of regularization algorithms will be more or less effective depending on the specific data set and machine learning model. As such, it is important to experiment with different types of regularization to find the best approach for a given problem.
In conclusion, regularization is a technique used in machine learning to reduce the generalization or test error thereby reducing the model overfitting. Regularization can be done in a number of ways, but typically involves adding penalties or constraints to the optimization process. This helps to find a set of weights that minimize both the training error and the penalty. Regularization is important because it can help improve the performance of a machine learning algorithm. In particular, it can help avoid overfitting and improve the generalizability of the model.

Check out my books titled as Designing Decisions, and First Principles Thinking.
- The Watermelon Effect: When Green Metrics Lie - January 25, 2026
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025

I found it very helpful. However the differences are not too understandable for me