Building a RAG Application with LangChain: Example Code

The combination of Retrieval-Augmented Generation (RAG) and powerful language models enables the development of sophisticated applications that leverage large datasets to answer questions effectively. In this blog, we will explore the steps to build an LLM RAG application using LangChain. Prerequisites Before diving into the implementation, ensure you have the required libraries installed. Execute the following command to install the necessary packages: Setting Up Environment Variables LangChain integrates with various APIs to enable tracing and embedding generation, which are crucial for debugging workflows and creating compact numerical representations of text data for efficient retrieval and processing in RAG applications. Set up the required environment variables for LangChain and OpenAI: Step …
Building an OpenAI Chatbot with LangChain

Have you ever wondered how to use OpenAI APIs to create custom chatbots? With advancements in large language models (LLMs), anyone can develop intelligent, customized chatbots tailored to specific needs. In this blog, we’ll explore how LangChain and OpenAI LLMs work together to help you build your own AI-driven chatbot from scratch. Prerequisites Before getting started, ensure you have Python (version 3.8 or later) installed and the required libraries. You can install the necessary packages using the following command: Setting Up OpenAI API Key To use OpenAI’s services, you need an API key, which you can obtain by signing up at OpenAI’s website (OpenAI) and generating a key from the …
How Indexing Works in LLM-Based RAG Applications
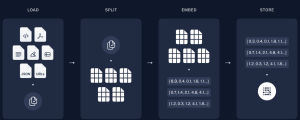
When building a Retrieval-Augmented Generation (RAG) application powered by Large Language Models (LLMs), which combine the ability to generate human-like text with advanced retrieval mechanisms for precise and contextually relevant information, effective indexing plays a pivotal role. It ensures that only the most contextually relevant data is retrieved and fed into the LLM, improving the quality and accuracy of the generated responses. This process reduces noise, optimizes token usage, and directly impacts the application’s ability to handle large datasets efficiently. RAG applications combine the generative capabilities of LLMs with information retrieval, making them ideal for tasks such as question-answering, summarization, or domain-specific problem-solving. This blog will walk you through the …
What are AI Agents? How do they work?
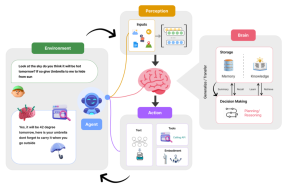
Artificial Intelligence (AI) agents have started becoming an integral part of our lives. Imagine asking your virtual assistant whether you need an umbrella tomorrow, or having it remind you of an important meeting—these agents now help us with weather forecasts, managing daily tasks, and much more. But what exactly are these AI agents, and how do they work? In this blog post, we’ll break down the inner workings of AI agents using an easy-to-understand framework. Let’s explore the key components of an AI agent and how they collaborate to enable seamless interactions, such as providing weather updates or managing tasks efficiently. What are AI Agents? AI agents are artificial entities …
Agentic AI Design Patterns Examples

In the ever-evolving landscape of agentic AI workflows and applications, understanding and leveraging design patterns is crucial for building effective and innovative solutions. Agentic AI design patterns provide structured approaches to solving complex problems. They enhance the capabilities of AI agents by enabling reasoning, planning, collaboration, and tool integration. For instance, you can think of these patterns as a blueprint for constructing a well-oiled team of specialists in a workplace—each with unique roles and tools, working in harmony to tackle a project efficiently and innovatively. Imagine a team of engineers collaborating on designing a new car, where one member focuses on aerodynamics, another on engine performance, and a third on …
List of Agentic AI Resources, Papers, Courses

In this blog, I aim to provide a comprehensive list of valuable resources for learning Agentic AI, which refers to developing intelligent systems capable of perception, autonomous decision-making, reasoning, and interaction in dynamic environments. These resources include tutorials, research papers, online courses, and practical tools to help you deepen your understanding of this emerging field. This blog will continue to be updated with relevant and popular papers periodically, based on emerging trends and the significance of newly published works in the field. Additionally, feel free to suggest any papers that you would like to see included in this list. This curated list highlights some of the most impactful and insightful …
Understanding FAR, FRR, and EER in Auth Systems

Have you ever wondered how systems determine whether to grant or deny access, and how they balance the risk of false acceptance with usability? This tutorial explores the fundamental concepts behind evaluating authentication systems or classification models using False Acceptance Rate (FAR), False Rejection Rate (FRR), and Equal Error Rate (EER). These metrics are essential for assessing the balance between usability and security in auth systems. Gaining a good understanding of these terms can greatly enhance both theoretical insights and practical application in designing reliable machine learning systems. What is False Acceptance Rate (FAR)? The False Acceptance Rate measures how frequently a system incorrectly grants access to an unauthorized individual. …
Top 10 Gartner Technology Trends for 2025

What revolutionary technologies and industries will define the future of business in 2025? As we approach this pivotal year, the technological landscape continues to evolve rapidly, reshaping industries and redefining business strategies. Gartner has unveiled its top 10 strategic technology trends for 2025, emphasizing advancements in AI, computing, and human-machine interaction. Here’s a closer look at these transformative trends: Agentic AI Agentic AI systems are designed to autonomously plan and execute tasks based on user-defined goals. These virtual assistants are poised to enhance productivity by automating decision-making processes. By 2028, Gartner predicts that at least 15% of daily work decisions will be autonomously handled by agentic AI, a significant leap …
OpenAI GPT Models in 2024: What’s in it for Data Scientists

For data scientists and machine learning researchers, 2024 has been a landmark year in AI innovation. OpenAI’s latest advancements promise enhanced reasoning capabilities and multimodal processing, setting new industry benchmarks. Let’s dive into these milestones and their practical implications for data scientists. May 2024: Launch of GPT-4o OpenAI introduced GPT-4o (“o” for “omni”), a multimodal powerhouse designed for text, image, and audio processing. With faster response times and improved performance across multilingual and vision tasks, GPT-4o offers a great tool for developing advanced AI applications. Early adopters have reported up to 40% efficiency gains in tasks requiring multimodal analysis (Smith et al., 2024). GPT-4o’s ability to process and integrate multi-modal …
Collaborative Writing Use Cases with ChatGPT Canvas

ChatGPT Canvas is a cutting-edge, user-friendly platform that simplifies content creation and elevates collaboration. Whether drafting detailed research papers, crafting visually engaging presentations, or writing professional emails, ChatGPT Canvas has the tools to make your work efficient and impactful. This guide explores leveraging Canvas effectively, tailored for college-level users and professionals alike. Developing Blogs, Articles or Research Essays Research essays, blogs & articless demand clarity, depth, and methodical organization. ChatGPT Canvas streamlines the entire process by offering tools to explore topics, verify facts, and refine your arguments. Its readability and visual integration features ensure that your essays are both compelling and accessible. Topic Exploration: Use web searches to dive into …
When to Use ChatGPT O1 Model

Knowing when to use the LLM such as the ChatGPT O1 model is key to unlocking its full potential. For example, the O1 model is particularly beneficial in scenarios such as analyzing large datasets for patterns in genomics, designing experiments to test novel chemical reactions, or creating algorithms to optimize workflows in computational biology. These applications highlight its ability to address diverse and intricate challenges. Designed to address complex, multifaceted challenges, the O1 model shines when diverse expertise—spanning data analysis, experimental design, coding, and beyond—is required. Let’s delve into these capabilities to understand when and how they can be effectively applied to drive groundbreaking advancements across various fields. Data Analysis …
Agentic Reasoning Design Patterns in AI: Examples

In recent years, artificial intelligence (AI) has evolved to include more sophisticated and capable agents, such as virtual assistants, autonomous robots, and conversational large language models (LLMs) agents. These agents can think, act, and collaborate to achieve complex goals. Agentic Reasoning Design Patterns help explain how these agents work by outlining the essential strategies that AI agents use for reasoning, decision-making, and interacting with their environment. What is an AI Agent? An AI agent, particularly in the context of LLM agents, is an autonomous software entity capable of perceiving its environment, making decisions, and taking actions to achieve specific goals. LLMs enable these agents to understand natural language and reason …
LLMs for Adaptive Learning & Personalized Education

Adaptive learning helps in tailoring learning experiences to fit the unique needs of each student. In the quest to make learning more personalized, Large Language Models (LLMs) with their capability to understand and generate human-like text, offer unprecedented opportunities to adaptively support and enhance the learning process. In this blog, we will explore how adaptive learning can leverage LLMs by integrating Knowledge Tracing (KT), Semantic Representation Learning, and Automated Knowledge Concept Annotation to create a highly personalized and effective educational experience. What is Adaptive Learning? Adaptive learning refers to a method of education that levereges technology to adjust the type and difficulty of learning content based on individual student performance. …
Sparse Mixture of Experts (MoE) Models: Examples
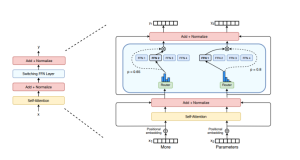
With the increasing demand for more powerful machine learning (ML) systems that can handle diverse tasks, Mixture of Experts (MoE) models have emerged as a promising solution to scale large language models (LLM) without the prohibitive costs of computation. In this blog, we will delve into the concept of MoE, its history, challenges, and applications in modern transformer architectures, particularly focusing on the role of Google’s GShard and Switch Transformers. What is a Mixture of Experts (MoE) Model? Mixture of Experts (MoE) model represents a neural network architecture that divides a model into multiple sub-components (neural network) called experts. Each expert is designed to specialize in processing specific types of …
Anxiety Disorder Detection & Machine Learning Techniques

Anxiety is a common mental health condition that affects millions of people around the world. Characterized by excessive worry, fear, and apprehension about everyday situations, anxiety can significantly impact a person’s quality of life. Traditional diagnosis of anxiety largely relies on subjective assessments, including self-reports and clinical observations, which can often be unreliable. In recent years, machine learning has emerged as a promising solution to address the challenges in detecting anxiety disorders with greater accuracy and objectivity. In this blog, we will learn about how machine learning models can be used for detecting anxiety disorders and what kind of data and ML algorithms can be used. The Challenge of Diagnosing …
Confounder Features & Machine Learning Models: Examples
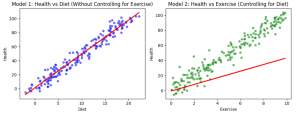
In machine learning, confounder features or variables can significantly affect the accuracy and validity of your model. A confounder feature is a variable that influences both the predictor and the outcome or response variables, creating a false impression of causality or correlation. This makes it harder to determine whether the observed relationship between two variables is genuine or merely due to some external factor. Example of Confounder Features For instance, consider a model that predicts a person’s likelihood of heart disease based on their diet. You may conclude that people eating a balanced diet are less likely to have heart disease, but this relationship could be confounded by exercise habits. …

I found it very helpful. However the differences are not too understandable for me