
Meta Researchers have, yesterday, unveiled a groundbreaking new model, namely Segment Anything Model (SAM), alongside an immense dataset, the Segment Anything Dataset (SA-1B), which together promise to revolutionize the field of computer vision. SAM’s unique architecture and design make it efficient and effective, while the SA-1B dataset provides a powerful resource to fuel future research and applications.
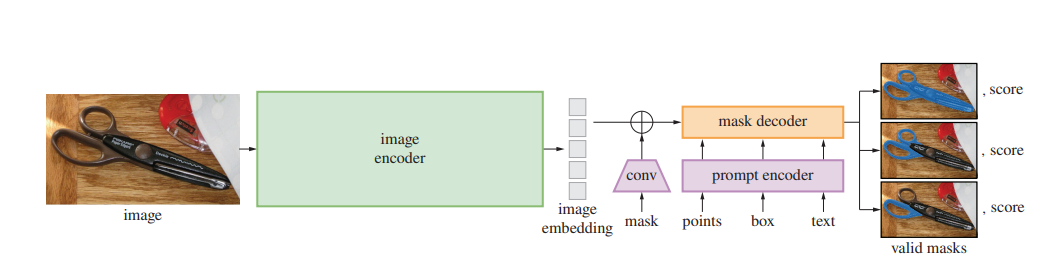
The Segment Anything Model is an innovative approach to promptable segmentation that combines an image encoder, a flexible prompt encoder, and a fast mask decoder. Its design allows for real-time, interactive prompting in a web browser on a CPU, opening up new possibilities for computer vision applications. One of the key challenges SAM addresses is ambiguity in segmentation tasks. By predicting multiple output masks for a single prompt, the model can resolve common ambiguities and provide more accurate segmentations. The following is a representation of three key components of foundation SAM model.
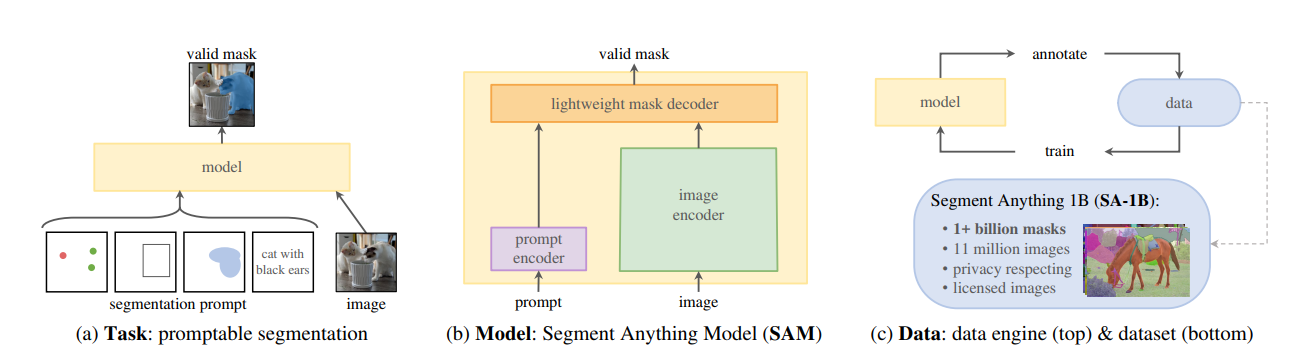
The following represents a high level overview on neural network architecture around SAM. Note the usage of encoder-decoder architecture used for training SAM model.
To support the development of SAM, researchers built the Segment Anything Data Engine, which amassed an impressive 1.1 billion mask dataset, known as SA-1B. The data engine has three stages: assisted-manual, semi-automatic, and fully automatic. The first stage saw professional annotators label masks using an interactive tool powered by SAM, while the second stage used automatically detected confident masks to guide annotators. In the final stage, SAM generated masks without any annotator input.
The SA-1B dataset consists of 11 million high-resolution, licensed, and privacy-protecting images, accompanied by 1.1 billion high-quality segmentation masks. It has been released to aid future development of foundation models for computer vision, with a favorable license agreement for certain research uses and protections for researchers.
Data scientists stand to benefit significantly from SAM and the SA-1B dataset. The unique architecture of SAM and its real-time capabilities make it a powerful tool for interactive computer vision tasks. With the ability to work efficiently in a web browser, SAM opens up opportunities for new applications and collaborations between researchers and practitioners.
The SA-1B dataset, on the other hand, provides a comprehensive resource for training and validating computer vision models. The dataset’s size and diversity ensure that models trained on it will be robust and effective in a wide range of applications. The high-quality masks included in the dataset make it an invaluable resource for researchers and developers alike.
Great thing is that the SA-1B dataset is released under a favorable license agreement means that data scientists can access and utilize the dataset without legal concerns, fostering innovation and collaboration within the computer vision community. As a result, SAM and the SA-1B dataset have the potential to greatly accelerate progress in the field, enabling researchers to push the boundaries of what is possible in computer vision.
Summary
The Segment Anything Model and Segment Anything Dataset together represent a significant breakthrough in computer vision research and development. With the potential to reshape the landscape of the field, SAM and SA-1B offer data scientists a powerful combination of innovative modeling techniques and an extensive dataset to advance their work. As the computer vision community continues to explore the possibilities offered by these resources, the future of the field looks brighter than ever.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me