In the rapidly evolving world of artificial intelligence, large language models (LLMs) have emerged as a game-changing force, revolutionizing the way we interact with technology and transforming countless industries. These powerful models can perform a vast array of tasks, from text generation and translation to question-answering and summarization. However, unlocking the full potential of these LLMs requires a deep understanding of how to effectively scale these LLMs, ensuring optimal performance and capabilities. In this blog post, we will delve into the crucial concept of scaling techniques for LLM models and explore why mastering this aspect is essential for anyone working in the AI domain.
As the complexity and size of LLMs continue to grow, the importance of scaling cannot be overstated. It plays a pivotal role in improving a model’s performance, generalization, and capacity to learn from massive datasets. By scaling LLMs effectively, researchers and practitioners can unlock unprecedented levels of AI capabilities, paving the way for innovative applications and groundbreaking solutions. Whether you are an AI enthusiast, a researcher, or a developer, learning the techniques for scaling LLM models is crucial for staying ahead in this competitive landscape and harnessing the true power of generative AI. In this blog, we will discuss about generative AI scaling techniques, discussing the key aspects of scaling LLM models, including model size, data volume, compute resources, and more.
What are Foundational LLM Models?
Foundation Large Language Models (LLMs) are a class of pre-trained machine learning models designed to understand and generate human-like text based on the context provided. They are often built using deep learning techniques, such as the Transformer architecture, and trained on massive amounts of diverse text data. Examples of foundation LLMs include OpenAI’s GPT-3, Google’s BERT, and Facebook’s RoBERTa, etc.
These LLMs are called “foundational” because they serve as a base for building and fine-tuning more specialized models for a wide range of tasks and applications. Foundation LLMs learn general language understanding and representation from vast amounts of data, which enables them to acquire a broad knowledge of various domains, topics, and relationships. This general understanding allows them to perform reasonably well on many tasks “out-of-the-box” without additional training.
These foundational LLMs, owing to them being pre-trained, can be fine-tuned on smaller, task-specific datasets to achieve even better performance on specific tasks, such as text classification, sentiment analysis, question-answering, translation, and summarization. By providing a robust starting point for building more specialized AI models, foundation LLMs greatly reduce the amount of data, time, and computational resources required for training and deploying AI solutions, making them a cornerstone for many applications in natural language processing and beyond.
Scaling Techniques for Foundational LLMs
In the context of Large Language Models (LLMs), scaling techniques primarily involve increasing the model size, expanding the training data, and utilizing more compute resources to improve their performance and capabilities. The following are the details for some of these techniques along with some of the associated challenges.
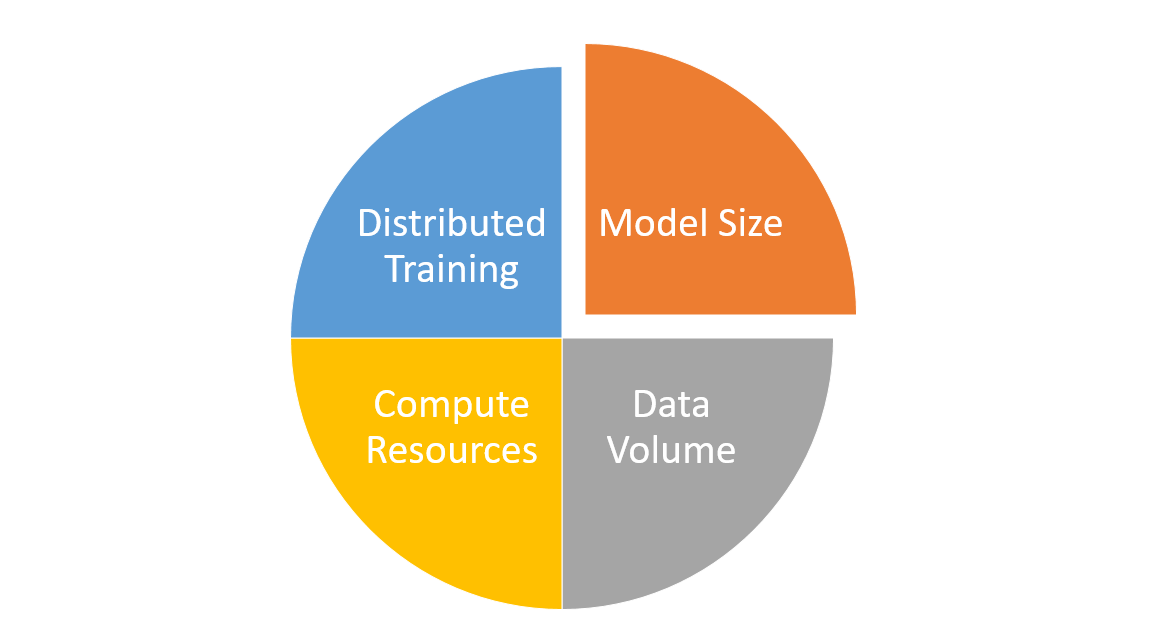
- Model size: Scaling the model size typically involves increasing the number of layers and parameters in the transformer neural network architecture. Larger language models have a higher capacity to learn and represent complex patterns in the data. However, increasing the model size comes with challenges such as longer training times, higher computational costs, and the possibility of overfitting, especially when training data is limited. Additionally, larger models may require specialized hardware and optimizations to manage memory and computational constraints effectively.
- Training data volume: Expanding the training data means using more diverse and larger text corpora to train the LLMs. More data helps mitigate the risk of overfitting and enable the models to better generalize and understand various domains, topics, and language nuances. However, acquiring and processing large volumes of high-quality training data can be challenging. Data collection, cleaning, and labeling (when required) can be time-consuming and expensive. Moreover, ensuring data diversity and addressing biases present in the data are essential to prevent models from perpetuating harmful stereotypes or producing unintended consequences.
- Compute resources: Scaling compute resources involves using more powerful hardware (such as GPUs or TPUs) and parallelizing the training process across multiple devices or clusters. This enables LLMs to be trained faster and more efficiently, allowing researchers to experiment with different model architectures and hyperparameters. However, increasing compute resources comes with higher energy consumption, financial costs, and environmental concerns. Additionally, access to such resources may be limited for smaller organizations or individual researchers, potentially widening the gap between well-funded institutions and others in the AI research community.
- Distributed training: Employing distributed training techniques allows LLMs to be trained across multiple devices or clusters, making it possible to handle larger models and datasets efficiently. This approach can significantly reduce training time and enable better exploration of model architectures and hyperparameters. However, distributed training comes with its own set of challenges, such as increased communication overhead, synchronization issues, and the need for efficient algorithms to handle data and model parallelism. Moreover, implementing distributed training requires expertise in both machine learning and distributed systems, which can be a barrier for smaller teams or individual researchers.
Conclusion
foundational Large Language Models (LLMs) have emerged as powerful tools in the field of AI, capable of generating human-like text and understanding complex patterns across various domains. These models are called “foundational” because they serve as a base for a wide array of applications, from natural language processing tasks to even aiding in fields such as computer vision and audio processing. Throughout this blog, we have explored several scaling techniques crucial for enhancing the performance and capabilities of foundational LLMs. These techniques include increasing the model size, expanding the training data volume, utilizing more compute resources, and employing distributed training. Each of these methods contributes to the overall effectiveness of LLMs but also brings forth challenges in terms of computational costs, data quality, resource accessibility, and technical expertise.
As we move forward, it is essential for researchers and practitioners to strike a balance between these scaling techniques and the associated challenges, ensuring the responsible development and deployment of LLMs. This will enable us to harness the full potential of generative AI and create groundbreaking applications across numerous domains. If you have any questions or require further clarification on any aspect of scaling techniques for foundational LLMs, please feel free to reach out to us.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me