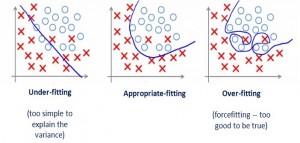
This article represents technique that could be used to identify whether the Learning Algorithm is suffering from high bias (under-fitting) or high variance (over-fitting) problem. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos.
Following are the key problems related with learning algorithm that are described later in this article:
- Under-fitting Problem
- Over-fitting Problem
Diagnose Under-fitting & Over-fitting Problem of Learning Algorithm
The challenge is to identify whether the learning algorithm is having one of the following:
- High bias or under-fitting: At times, our model is represented using polynomial equation of relatively lower degree, although a higher degree of polynomial would give lower value from cost or error function. In this scenario, the model could be said to be having high bias or under-fitting problem. Following diagram represents the learning algorithm with under-fitting problem. In the diagram below, the regression line is represented by polynomial of degree 1. For instance, h(x) = a + bx. However, the coordinates seem to represent the quadratic polynomial.
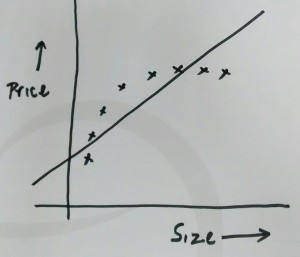
under-fitting example
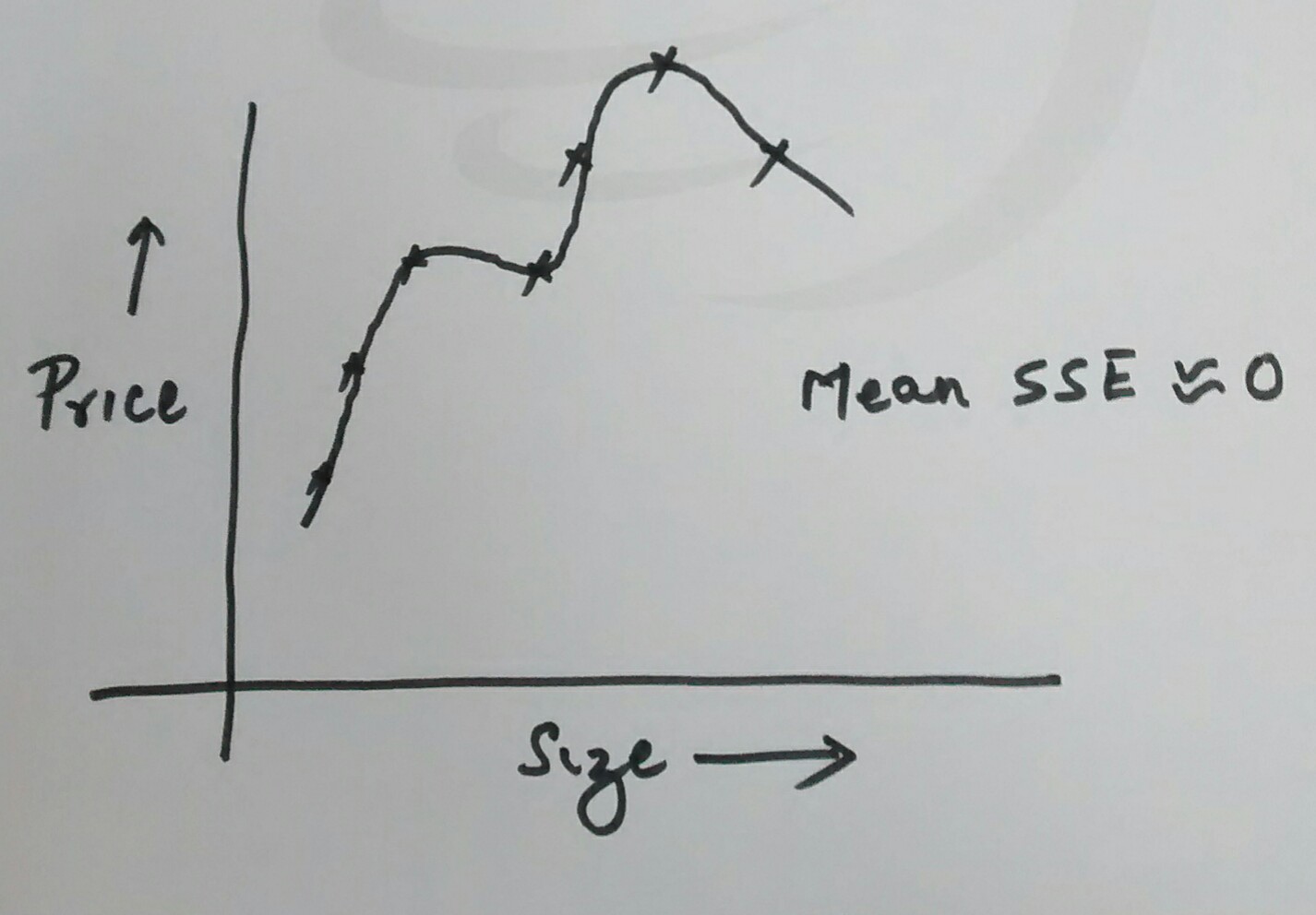
- High variance or over-fitting: When the polynomial representing the model fits the data very well such that the error or cost function is minimal, there are chances of over-fitting. Following diagram represents the learning algorithm with over-fitting problem. Note that for over-fitting problem, the mean sum of squared error can be found to be close to zero.
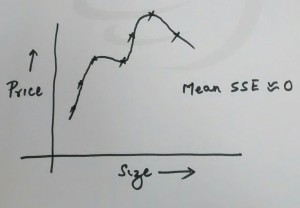
over-fitting example
Following technique can be used to identify the case of high bias (under-fitting) or high variance (over-fitting) given that the data set is split into training, cross-validation set and test set and, training dataset is used to determine the parameters that makes the best fit (least error value).
- Under-fitting Problem: In scenario where the error value of training data set and cross-validation data set are both higher and similar, the learning algorithm can be said to have under-fitting problem. Here the assumption is that the data set is large enough. For very small data set, the learning algorithm may have error value of training data set close to zero but the error of cross-validation data set would still be large enough.
- Over-fitting Problem: In case the training data set error is low and cross-validation data set is comparatively very high, the algorithm can be said to have over-fitting problem.

I have been recently working in the area of Data analytics including Data Science and Machine Learning / Deep Learning. I am also passionate about different technologies including programming languages such as Java/JEE, Javascript, Python, R, Julia, etc, and technologies such as Blockchain, mobile computing, cloud-native technologies, application security, cloud computing platforms, big data, etc. I would love to connect with you on Linkedin.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
Latest posts by Ajitesh Kumar (see all)
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me