In today’s business world, data is king. The more data you have, the more insights you can glean about your customers, your products, and your operations. And the best way to collect and store all that data is in a data lake. A data lake is a data management and analytics platform that offers several benefits over traditional data warehouses. Data lakes have gained in popularity in recent years due to the growing volume of data being generated by businesses and organizations of all sizes. But before you can reap the benefits of a data lake, you need to design it correctly. The people who should be involved in designing a data lake are the business users, business analysts and data analysts who will be using the data lake to analyze data and find insights. The Data Architect and Data Engineer should be involved in designing the data lake, but they should be working with the business users to understand their needs and design a platform that meets their requirements. In this blog, we will discuss some principles and best practices to keep in mind when designing your data lake.
What is a data lake and why do you need one?
A data lake is a large repository of data, usually in its original form, that can be accessed and analyzed by business users and data scientists. In other words, a data lake is a file system that stores data in its original format. This can include both structured and unstructured data, making it an ideal repository for big data management and analytics. Data lakes are often compared to Data warehouses, which store data in a pre-defined structure for reporting and analysis. Data lake can said to be a data management and analytics platform that offers several benefits over traditional data warehouses, including the ability to store data in its original format, access data quickly and easily, and enrich data with additional data from external sources. Data lakes offer several advantages over traditional data warehouses:
- Data is stored in its original format, so it can be accessed and analyzed more easily.
- Data can be accessed quickly and easily by business users and data scientists.
- Data can be easily enriched with additional data from external sources.
- Data can be processed and analyzed in real time.
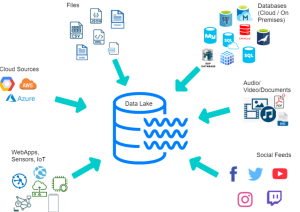
Data lake stores different types of data
The picture below represents different types of data that can be stored in data lake.
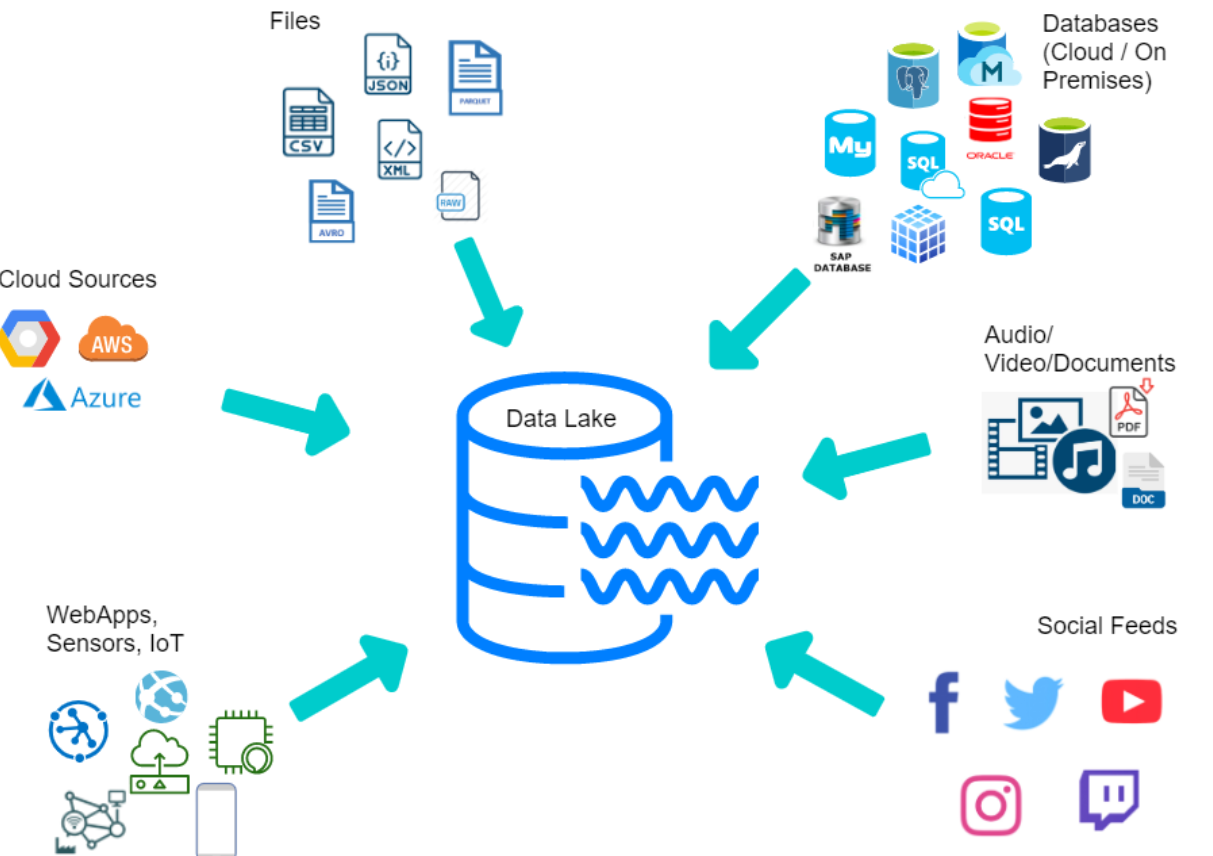
A data lake can store a variety of data types, including structured data, unstructured data, and semi-structured data.
- Structured Data: Structured data is data that is organized in a pre-determined manner. It is usually stored in databases and can be accessed easily by business users and data scientists. The most common type of structured data is relational data, which is organized in tables with columns and rows. Structured data can be found in a variety of places, including databases, data warehouses, and Excel spreadsheets. The most common type of structured data is relational data, which is organized in tables with columns and rows. Relational data is easy to access and can be easily analyzed by business users and data scientists.
- Unstructured Data: Unstructured data is data that is not organized in a pre-determined manner. It is usually stored in files or documents and can be accessed easily by business users and data scientists. The most common type of unstructured data is text data, which is text that is not organized in a specific format. Some examples of unstructured data include:-
- Text data
- Data in the form of emails
- Data in the form of PDFs or Word documents
- Data in the form of images
- Data in the form of audio / video files
- Semi-Structured Data: Semi-structured data is data that has some structure, but not enough to be stored in a database. It is usually stored in files or documents and can be accessed easily by business users and data scientists. The most common type of semi-structured data is XML Data, which is XML documents that are not organized in a specific format.
Benefits of Data Lake
The benefits of a data lake can be described as follows:
- Reduced costs: A data lake can result in reduced costs in several ways. First, it eliminates the need for expensive data warehouses and ETL (extract, transform, load) tools. Second, it allows you to store all your data in one place, so you can access it quickly and easily. Third, it allows you to enrich your data with additional data from external sources. Finally, it enables you to process and analyze your data in real time, so you can make better decisions faster. In one example, a large insurance company was able to reduce its data processing costs by 80% after implementing a data lake. The company had been using an expensive data warehouse and ETL tools to process its data. After switching to a data lake, the company was able to store all of its data in one place and process it in real time. This resulted in significant cost savings for the company.
- Improved flexibility: A data lake allows you to store all your data in one place, so you can access it quickly and easily. It also allows you to enrich your data with additional data from external sources. A data lake can offer improved flexibility for big data management and analytics because it provides a centralized repository for all data, both structured and unstructured. This allows for more efficient data processing, analysis, and decision-making. For example, imagine you are a retailer who wants to analyze customer purchase data in order to improve marketing campaigns. With a data lake, you can easily access all of your customer purchase data, regardless of where it is stored, and run sophisticated analyses on it to identify trends. As a result, you can make more informed decisions about your marketing campaigns and improve your bottom line. Data lakes can accommodate a variety of data formats, including both structured and unstructured data. This flexibility makes them ideal for big data management and analytics. For example, a data lake can be used to store all of the data collected by a company’s sensors and devices, making it easier to analyze and gain insights into how the company is performing.
- Improved performance: A data lake can provide significant performance improvements for data handling by allowing you to store data in its original format, without the need for pre-processing. This can save time and reduce the complexity of your data pipeline. For example, a retailer wanted to use a data lake to improve the performance of their big data analytics pipeline. The retailer was processing over 1 million transactions per day, and needed to analyze this data in near-real-time. They had been using a traditional data warehouse to process the data, but were finding that the performance was not meeting their needs. The retailer decided to try using a data lake instead. They were able to store all of the raw transaction data in its original format, without having to pre-process it. This allowed them to reduce the time it took to run their analytics pipeline from several hours to just a few minutes.
Expertise & Experience Required for Managing Data Lake
Managing a data lake requires expertise and experience in big data management and analytics. A data lake can offer significant performance improvements for data handling, but it must be designed and managed correctly in order to achieve these benefits. Data lakes are not a one-size-fits-all solution, and it is important to understand the specific needs of your organization before implementing one. Here are some tips for managing a data lake:
- Make sure you have the right tools and infrastructure in place. In order to take full advantage of a data lake, you need the right tools and infrastructure in place. This includes hardware, software, and personnel with the necessary expertise to manage and use the data lake effectively.
- Establish clear governance policies for the data lake. It is important to establish clear governance policies for the data lake in order to ensure that it is used effectively and efficiently. This includes specifying who has access to the data lake, what type of data can be stored, and how the data can be used.
- Train your personnel on how to use the data lake. It is important to train your personnel on how to use the data lake effectively in order to get the most out of it. This includes training them on how to access and analyze the data, as well as how to use the various tools and technologies involved in its operation.
- Manage the data carefully. It is important to manage the data carefully in order to ensure that it is used effectively and efficiently. This includes deleting or archiving old or unnecessary data, ensuring that the data is properly organized and labeled, and enforcing strict governance policies for its use.
- Monitor the performance of the data lake. It is important to monitor the performance of the data lake in order to identify any issues or bottlenecks. This includes monitoring the data ingestion rate, the processing time, and the output quality.
Data lake design principles
A data lake is a great way to store and manage big data. But before you can reap the benefits of a data lake, you need to design it correctly. Here are some principles to keep in mind when designing your data lake.
- Keep it simple: The more complex your data lake is, the more difficult it will be to use. Keep it as simple as possible so that everyone on your team can easily understand it.
- Store all your data in one place: Ideally, you should store all your data in one place so that you can easily access it and analyze it. When you store all your data in one place, it’s much easier to access and analyze. This can help you make better decisions about your business. Additionally, storing all your data in one place makes it easier to keep track of and comply with regulations.
- Make sure it’s scalable: Your data lake needs to be able to scale up or down as needed, depending on the amount of data you’re storing and processing. A data lake needs to be scalable so that it can easily handle the increasing volume of data being generated by businesses today. If your data lake isn’t scalable, it will quickly become overwhelmed and unusable. Make sure your data lake is designed for scalability from the beginning to avoid this problem.
- Make sure it’s secured: One important consideration when designing your data lake is security. You need to make sure that your data is safe and secure, and that only authorized users can access it. There are a number of ways to secure your data lake, including data encryption, role-based access control and data masking. Data encryption ensures that data is protected from unauthorized access. Role-based access control allows you to control which users can access which data. Data masking helps protect sensitive data by obscuring it or hiding it from view.
- Choose the right storage technology: The type of storage technology you choose will affect the performance of your data lake. Choose the right one for your needs. There are a number of cloud storage technologies which can be used for data lakes. The most popular options are Amazon Simple Storage Service (S3), Azure Blob Storage, and Google Cloud Storage.S3 is a popular option because it offers a lot of flexibility and scalability. You can use S3 to store any type of data, and it’s easy to scalable so you can add more storage as needed. Azure Blob Storage is also a good option, especially if you need to store large files. It offers good performance and scalability, and it’s affordable. Google Cloud Storage is another good option, especially if you’re already using other Google products. It offers good performance and reliability, and it’s easy to use.
- Define your governance model early on: Who will be responsible for managing and governing the data in your data lake? Define this early on so there are no surprises later on. There are a number of governance models that can be used for data lakes. The most popular option is the centralized governance model. With this model, all the data in the data lake is centrally managed by a single team. This team is responsible for ensuring that the data is properly organized and labeled, and that only authorized users can access it. Another popular governance model is the distributed governance model. With this model, the responsibility for managing and governing the data is distributed among several teams. Each team is responsible for managing a specific subset of the data in the data lake. This can help ensure that different parts of the data lake are managed by different teams, which can improve overall efficiency. A third option is the self-governance model. With this model, each user is responsible for managing their own data. This can be helpful if you want more control over your own data, but it can also lead to chaos if everyone manages their own data in different ways. Choose the right governance model for your needs and make sure to define it early on in the design process.
Data lake best practices
A data lake is a great way to store and analyze big data, but it’s important to design it correctly in order to get the most out of it. Here are some best practices to keep in mind when creating your data lake:
- Make sure the data is organized and easy to access: When you’re designing your data lake, make sure the data is well-organized and easy to access. This will make it easier to find what you’re looking for and reduce the time it takes to find and analyze the data.
- Include all relevant data: Don’t forget to include all of the relevant data in your data lake. This will ensure that you have a complete picture of the data and can get a better understanding of what’s going on.
- Use the right tools for the job: Make sure you’re using the right tools to analyze the data in your data lake. This will help you get the most out of the data and make it easier to interpret.
- Be prepared for changes: The big data landscape is always changing, so be prepared for changes when designing your data lake. This will help ensure that your data lake can keep up with these changes and continue to provide value.
Data lake use cases
There are a number of different ways to use a data lake. Here are three of the most popular data lake use cases:
- Data warehousing: A data warehouse is a great way to store and analyze historical data. A data lake can be used as a data warehouse, which can help improve performance and scalability.
- Data mining: Data mining is the process of extracting valuable information from large datasets. A data lake is a great place to do data mining, as it allows you to easily store and access large datasets.
- Predictive analytics: Predictive analytics is the process of using historical data to predict future events. A data lake is a great place to do predictive analytics, as it allows you to easily store and access large datasets.
Conclusion
Data lakes have gained in popularity in recent years due to the benefits they offer for big data management and analytics. But before you can reap these benefits, you need to design your data lake correctly. Here are some principles and best practices to keep in mind when designing your data lake. Data lakes provide a great way to store and analyze big data, but it’s important to design them correctly in order to get the most out of them. Make sure the data is well-organized and easy to access, include all relevant data, use the right tools for the job, and be prepared for changes. There are a number of different ways to use a data lake, so choose the one that best suits your needs. With these tips in mind, you can design a data lake that will provide value for years to come.
Did you find this article helpful? Share your thoughts with us in the comments below!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me