
As data scientists, we are constantly exploring new techniques and algorithms to improve the accuracy and efficiency of our models. When it comes to image-related problems, convolutional neural networks (CNNs) are an essential tool in our arsenal. CNNs have proven to be highly effective for tasks such as image classification and segmentation, and have even been used in cutting-edge applications such as self-driving cars and medical imaging. Convolutional neural networks (CNNs) are deep neural networks that have the capability to classify and segment images. CNNs can be trained using supervised or unsupervised machine learning methods, depending on what you want them to do. CNN architectures for classification and segmentation include a variety of different layers with specific purposes, such as a convolutional layer, pooling layer, fully connected layers, dropout layers, etc.
In this blog post, we will dive into the basic architecture of CNNs for classification and segmentation. We will cover the fundamentals of how CNNs work, including convolutional layers, pooling layers, and fully connected layers. By the end of this blog post, you will have a solid understanding of how CNNs can be used to tackle image-related problems and will be ready to apply this knowledge in your own projects. So, whether you’re a seasoned data scientist or just starting out, join us on this journey to discover the power of CNNs in image analysis.
Basic CNN architecture for Classification
Convolutional Neural Networks (CNNs) are a type of deep learning algorithm that have been developed specifically to work with images and other grid-like data, such as audio signals and time series data. The CNN architecture for image classification includes convolutional layers, max-pooling layers, and fully connected layers. The following is a description of different layers of CNN:
- Convolutional layers: CNNs are particularly effective at learning the spatial and temporal relationships between the pixels in an image. They do this by using a series of convolutional layers that apply a set of filters to the input image. Convolutional layers apply a set of filters to the input image to extract important features, such as edges, lines, textures, and shapes. Each filter is a small matrix of weights that is convolved with the input image to produce a feature map. Each feature map represents a particular feature or pattern that the CNN has learned to detect in the input image. The feature maps can be understood as the output of the convolution operation for each of the filters. By applying multiple filters, the convolutional layer generates multiple feature maps, each of which represents a different set of learned features. The output of convolution layer passes to activation layer (such as ReLU) to introduce non-linearity in training process. The output from activation layer is then passed to the pooling layer.
- Pooling layers: Apart from the convolutional layers, CNNs typically include pooling layers that down sample the feature maps produced by the convolutional layer. This helps to reduce the dimensionality of the feature maps, making them more computationally efficient to process and reducing the risk of overfitting. Max-pooling works by dividing the feature maps into non-overlapping regions and taking the maximum value of each region. This operation retains the most salient features of the feature maps and discards the rest, resulting in a compressed representation of the input image. The pooling operation also helps to enforce some degree of translation invariance in the features, which means that the network will be able to recognize an object regardless of its location in the input image. While convolution layers are meant for feature detection, max-pooling layers are meant for feature selection.
- Fully connected or dense layers: The output from the convolutional and pooling layers is passed through one or more fully connected layers (also known as dense layers), which use a standard neural network architecture to classify the input image or perform other tasks such as segmentation. The output of the convolutional and pooling layers in a CNN is a set of high-level features that represent the important characteristics of the input image. The role of the fully connected layers is to use these learned features to make a prediction about the class or label of the input image.
The diagram below represents the basic CNN architecture for image classification.
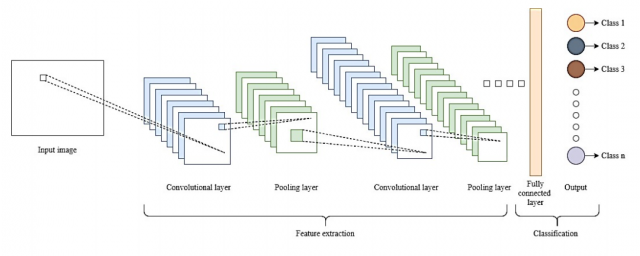
In the above architecture, the following are different layers:
- Input Layer: This layer takes in the input image data.
- Convolutional Layer 1: This layer applies a set of filters to the input image to extract low-level features, such as edges and corners. The output of convolutional layer is passed to, let’s say, rectified linear unit (ReLU) activation function. You can also use other activation functions as well. This introduces non-linearity into the model.
- Pooling Layer 1: This layer down-samples the feature maps produced by the first convolutional layer, reducing their dimensionality and making them more computationally efficient to process.
- Convolutional Layer 2: This layer applies a set of filters to the output of the first max pooling layer to extract more complex features, such as patterns and textures. The output of convolutional layer is passed to the rectified linear unit (ReLU) activation function. This introduces non-linearity into the model.
- Max Pooling Layer 2: This layer down-samples the feature maps produced by the second convolutional layer, further reducing their dimensionality.
The examples of classification learning task where CNN is used are image classification, object detection, and facial recognition.
Basic CNN architecture for Segmentation
Computer vision deals with images, and image segmentation is one of the most important steps. It involves dividing a visual input into segments to make image analysis easier. Segments are made up of sets of one or more pixels. Image segmentation sorts pixels into larger components while also eliminating the need to consider each pixel as a unit. It is the process of dividing image into manageable sections or “tiles”. The process of image segmentation starts with defining small regions on an image that should not be divided. These regions are called seeds, and the position of these seeds defines the tiles. The picture below can be used to understand image classification, object detection and image segmentation. Notice how image segmentation can be used for image classification or object detection.

Image segmentation has two levels of granularity. They are as following:
Semantic segmentation
Semantic segmentation classifies image pixels into one or more classes which are semantically interpretable, rather, real-world objects. Categorizing the pixel values into distinct groups using CNN is known as region proposal and annotation. Region proposals are also called candidate objects patches, which can be thought of as small groups of pixels that are likely to belong to the same object.
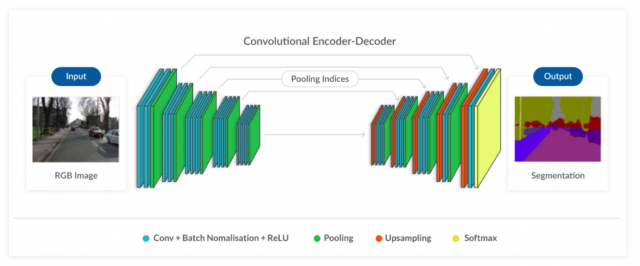
CNNs for semantic segmentation typically use a fully convolutional network (FCN) architecture, which replaces the fully connected layers of a traditional CNN with convolutional layers. This allows the network to process input images of any size and produce a corresponding output map of the same size, where each pixel is assigned a label.
The FCN architecture typically consists of an encoder-decoder structure with skip connections. The encoder consists of a series of convolutional and pooling layers, which gradually reduce the spatial resolution of the feature maps while increasing the number of channels. The decoder consists of a series of up sampling layers, which gradually increase the spatial resolution of the feature maps while reducing the number of channels. The skip connections allow the network to incorporate high-level features from the encoder into the decoding process, improving the accuracy of the segmentation.
During training, the network is typically trained using cross-entropy loss, which measures the difference between the predicted segmentation and the ground truth segmentation. The ground truth segmentation is a binary mask where each pixel is labeled with its corresponding class label.
During inference, the FCN takes an input image and produces a corresponding output map where each pixel is assigned a label. The output map can then be post-processed to produce a binary mask for each class, which identifies the pixels belonging to that class.
Instance segmentation
In case of instance segmentation, each instance of each object is identified. Instance segmentation requires the use of an object detection algorithm in addition to the CNN architecture. There are different approaches to doing instance based segmentation. They are as following:
- The object detection algorithm first identifies the location of each object in the image, and then the CNN architecture segments each object separately. This is typically achieved using object detection algorithms like Faster R-CNN, RetinaNet, or YOLO. The object detection algorithm typically uses a region proposal network (RPN) to generate candidate object locations in the image. The RPN takes an image as input and outputs a set of bounding boxes that are likely to contain objects. Each bounding box is then passed through a classification network that predicts the class label of the object within the box and refines the location of the box to better fit the object. In the segmentation stage, CNNs are used to extract features from the region of interest (ROI) defined by the bounding box. The ROI is then fed into a fully convolutional network (FCN) to perform instance segmentation. The FCN consists of a series of convolutional and pooling layers followed by an upsampling layer to recover the original image size. The output of the FCN is a binary mask that identifies the pixels belonging to the object of interest.
- Another approach for instance segmentation is Mask R-CNN, which combines object detection and segmentation in a single network. Mask R-CNN is an extension of the Faster R-CNN object detection framework, with an additional branch for generating object masks. The object detection branch identifies the object location and size, while the mask branch generates a binary mask for each object. The two branches are trained jointly using a multi-task loss function.
This type of segmentation is important in many computer vision applications, including autonomous driving, robotics, and medical image analysis.
What’s the difference between semantic and instance based image segmentation?
Semantic segmentation is the task of assigning a class label to each pixel in an image, where the label corresponds to a semantic category such as “person,” “car,” or “tree.” In other words, semantic segmentation aims to divide an image into regions that correspond to different object categories or classes, but does not differentiate between different instances of the same object class. For example, all instances of “person” in an image would be labeled with the same “person” class label.
Instance-based segmentation, on the other hand, is the task of identifying and separating each instance of an object in an image. This means that each object instance is assigned a unique label, and each pixel is labeled according to the object instance it belongs to. For example, in an image with multiple people, each person would be labeled with a different instance ID, and pixels belonging to each person would be labeled with the corresponding ID.
Here is a view of how encoder-decoder FCN architecture is used for image segmentation:
CNNs are a powerful tool for segmentation and classification, but they’re not the only way to do these tasks. CNN architectures have two primary types: segmentations CNNs that identify regions in an image from one or more classes of semantically interpretable objects, and classification CNNs that classify each pixel into one or more classes given a set of real-world object categories. In this article we covered some important points about CNNs including how they work, what their typical architecture looks like, and which applications use them most frequently. Do you want help with understanding more about CNN architectures? Let us know!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me