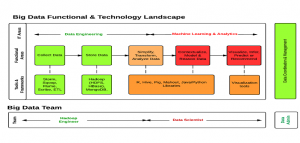
- Associate functional areas with technologies
- Reflect on demand vs supply by showing the boxes/texts in green which is readily available to that in red which is difficult to find
- Reflect on functional/technology areas with respect to easy/intermediate/difficult (green/amber/red)

Big Data Functional Technology Architecture
Following are two core areas of Big Data represented in the diagram above. We shall look into technologies as well as people aspect of each of the core areas in detail, later in this article.
- Data Engineering
- Data Science
Data Engineering
Data engineering includes following as key functional areas along with key technologies mentioned side-by-side:
- Collect Data: This is about collecting or gathering data from different data sources. For example, data could either be collected from one or more RDBMS databases or data could be streaming data such as log files (data from internal or external data sources). Different technologies such as following could be used to gather or collect data:
- Sqoop
- Flume
- Scribe
- Storm
- Store Data: Once data is collected, it needs to be stored for further processing. Different technologies (frameworks) such as following can be used for handling data storage:
- HDFS (Hadoop Distributed File System)
- HBase (NoSQL datastore)
- MongoDB (NoSQL datastore)
- Cassandra (NoSQL datastore)
- CouchDB (NoSQL datastore)
- Transform, Simplify and Analyze Data: The data, once gathered and stored, needs to be processed further for transforming the data into different forms for performing analytics activity on the data. Hadoop Map/Reduce jobs are run on the stored data which then gets stored on datastores such as HBase etc. From there on, the data analysis phase starts in which tools such as following comes into picture:
- Hive
- PIG
All of the above tasks may require data engineer with good knowledge of Hadoop technology stack. One may note that this part if comparatively easier than the data science.
Data Science
Once done with data engineering phases, the data analysis phase starts in which some of the following technologies (frameworks) come very handy:
- R programming language
- Mahout
- Pig
- Hive
- Java/Python libraries
The person working in data analysis phase need to be strong with following skills:
- Machine learning algorithms
- Mathematics & Statistics knowledge
This person can also be called as “Data Scientist” and is very much in demand as to find a person with above skills is a difficult task.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me