The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need.
Transformer Block – Core Building Block of Transformer Model Architecture
Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block.
The core building block of the Transformer architecture consists of multi-head attention (MHA)
followed by a fully connected network (FFN) as shown in the following picture (taken from the paper – Scaling down to scaling up: A guide to PEFT). The following transformer block represents a standard component of a transformer model, and multiple such transformer blocks can be stacked to form the full transformer model. At the heart of the transformer model is the attention operation or attention mechanism that allows the modeling of dependencies without regard to their distance in the input or output sequence of text (Attention is all you need). While prior deep learning architectures were based on attention mechanisms in conjunction with recurrent neural networks (RNN), the transformer architecture completely relied on the attention mechanism to draw global dependencies between input and output.
The following are the details of the key building block of the above-shown transformation architecture:
- Multi-head attention can be defined as an attention mechanism that allows the model to learn the complex relationship by focusing on different parts of the input sequence when predicting each part of the output sequence. Each attention head represents a distinct attention mechanism paying attention to different types of information so that the layer as a whole can learn more complex relationships. For example, Some heads, termed positional attention, may specialize in capturing positional relationships within the sequence while other heads, termed syntactic attention learn to focus on syntactic structures. Another attention head can be semantic attention which may capture semantic relationships.
- Residual connection (add) and layer normalization (norm): The residual connection allows the output of the multi-head attention layer to bypass the next sub-layer and go directly to the layer normalization step. This can help mitigate the vanishing gradient problem and allows for the training of deeper models. This is also found after a feed-forward fully connected network. It ensures that the transformations of the feed-forward layer are smoothly integrated into the model’s learning process.
- Feed-forward FFN: The third layer (in blue) represents a feed-forward fully connected network that applies the same transformation to each position separately and identically. This layer can learn complex combinations of the features.
Transformer Architecture Explained
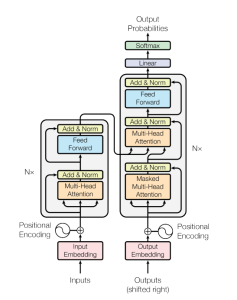
The following is the transformer model architecture (refer Attention is All You Need). The transformer model architecture consists of an encoder (left) and decoder (right) structure. The encoder maps an input sequence of symbol representations (x1, …, xn) to a sequence of continuous representations z = (z1, …, zn). Based on continuous representations, the decoder generates an output sequence (y1, …, ym) of symbols one element at a time.
The following is an explanation of the encoder and decoder blocks of the transformer model architecture shown above:
- Encoder: The encoder consists of N=6 identical layers stacked on top of each other. Each of the 6 layers is comprised of the two sub-layers namely multi-head attention (self-attention) and feed-forward fully connected network as described in the transformer block explained in the previous section. The output of these sub-layers is fed into Add & Norm as shown in the transformed block to mitigate the vanishing gradient problem and allow for the training of deeper models. All sub-layers and embedding layers produce outputs of a consistent size of dimension d=512.
- Decoder: The decoder also has N=6 identical layers, mirroring the encoder’s structure. Each decoder layer has a couple of other sub-layers apart from two sub-layers present in the encoder. Apart from MHA and FFN, there is a layer called masked multi-head attention whose output is fed into residual connections (add) and layer normalization (norm). In this attention mechanism, a mask is applied to ensure that the prediction for a given position can only depend on known outputs at positions before it. In addition, another layer represents multi-head attention which is fed with output from the encoder stack.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025
- RAG Pipeline: 6 Steps for Creating Naive RAG App - November 1, 2025
I found it very helpful. However the differences are not too understandable for me