Have you been wondering what sets apart two of the most prominent transformer-based machine learning models in the field of NLP, Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformers (GPT)? While BERT leverages encoder-only transformer architecture, GPT models are based on decoder-only transformer architecture. In this blog, we will delve into the core architecture, training objectives, real-world applications, examples, and more. By exploring these aspects, we’ll learn about the unique strengths and use cases of both BERT and GPT models, providing you with insights that can guide your next LLM-based NLP project or research endeavor.
Differences between BERT vs GPT Models
BERT, introduced in 2018, marked a significant advancement in the field of encoder-only transformer architecture. The encoder-only architecture just contains several repeated layers of bidirectional self-attention and a feed-forward transformation, both followed by a residual connection and layer normalization.
The GPT models, developed by OpenAI, represent a parallel advancement in the field of transformer architectures, specifically focusing on the decoder-only transformer model.
Instead of the next token prediction, the BERT model is based on a self-supervised Cloze objective, in which words/tokens from the input are randomly masked and a prediction is made. BERT uses bidirectional self-attention (instead of masked self-attention, which is used by decoder-only models such as GPT), the model can look at the entire sequence both before and after the masked token to make a prediction
The following represents the key differences between BERT and GPT models.
| Aspect | BERT | GPT |
|---|---|---|
| Architecture | Utilizes a bidirectional Transformer architecture, meaning it processes the input text in both directions simultaneously. This allows BERT to capture the context around each word, considering all the words in the sentence. | Employs a unidirectional Transformer architecture, processing the text from left to right. This design enables GPT to predict the next word in a sequence but limits its understanding of the context to the left of a given word. |
| Training Objective | Trained using a masked language model (MLM) task, where random words in a sentence are masked, and the model predicts masked words based on the surrounding context. This helps in understanding the relationships between words. | Trained using a causal language model (CLM) task, where the model predicts the next word in a sequence. This objective helps GPT in generating coherent and contextually relevant text. |
| Pre-training | Captures the context from both the left and right of a word, providing a more comprehensive understanding of the sentence structure and semantics. | Pre-trained solely on a causal language model task, focusing on understanding the sequential nature of the text. |
| Fine-tuning | Can be fine-tuned for various specific NLP tasks like question answering, named entity recognition, etc., by adding task-specific layers on top of the pre-trained model. | Can be fine-tuned for specific tasks like text generation and translation by adapting the pre-trained model to the particular task. |
| Bidirectional Understanding | Captures the context from both left and right of a word, providing a more comprehensive understanding of the sentence structure and semantics. | Understands context only from the left of a word, which may limit its ability to fully grasp the relationships between words in some cases. |
| Use Cases | BERT is very good at solving sentence and token-level classification tasks. Extensions of BERT (e.g., sBERT) can be used for semantic search, making BERT applicable to retrieval tasks as well. Finetuning BERT to solve classification tasks is oftentimes preferable to performing few-shot prompting via an LLM. | Encoder-only models such as BERT cannot generate text. This is where we need decoder-only models such as GPT. They are suitable for tasks like text generation, translation, etc. |
| Real-World Example | Used in Google Search to understand the context of search queries, enhancing the relevance and accuracy of search results. | Models like GPT-3 are employed to generate human-like text responses in various applications, including chatbots, content creation, and more. |
BERT & GPT Neural Network Architectures
To truly understand the differences between BERT and GPT models, it is important to get a good understanding of how their neural network architectures look like.
BERT Neural Network Architectures
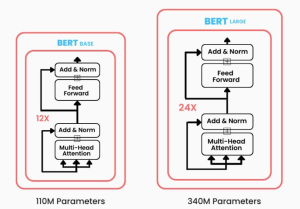
The neural network architecture of BERT is categorized into two main implementations: BERT (Base) and BERT (Large).
BERT (Base) consists of 12 encoder layers. Each encoder layer contains a multi-head self-attention mechanism and a position-wise fully connected feed-forward network. There are 12 bidirectional self-attention heads in each encoder layer, allowing the model to focus on different parts of the input simultaneously. BERT (Base) has a total of 110 million parameters, making it a sizable model, but still computationally more manageable than BERT (Large).
BERT (Large) is a more substantial model with 24 encoder layers, enhancing its ability to capture complex relationships within the text. With 16 bidirectional self-attention heads in each encoder layer, BERT (Large) can pay attention to even more nuanced aspects of the input. BERT (Large) totals 340 million parameters, making it a highly expressive model capable of understanding intricate language structures.
Both BERT (Base) and BERT (Large) have been pre-trained on the Toronto BookCorpus (800M words) and English Wikipedia (2,500M words), providing a rich and diverse linguistic foundation.
GPT Neural Network Architectures
The foundational GPT model (GPT-1) was constructed with a 12-level Transformer decoder architecture. Unlike the original Transformer model, which consists of both an encoder and a decoder, GPT-1 only utilizes the decoder part. The decoder is designed to process text in a unidirectional manner, making it suitable for tasks like text generation. Within each of the 12 levels, GPT-1 employs a 12-headed attention mechanism. This multi-head self-attention allows the model to focus on different parts of the input simultaneously, capturing various aspects of the sequential text.
Following the Transformer decoder, GPT-1 includes a linear layer followed by a softmax activation function. This combination is used to generate the probability distribution over the vocabulary, enabling the model to predict the next word in a sequence.
The following is the architecture diagram of the GPT foundational model:
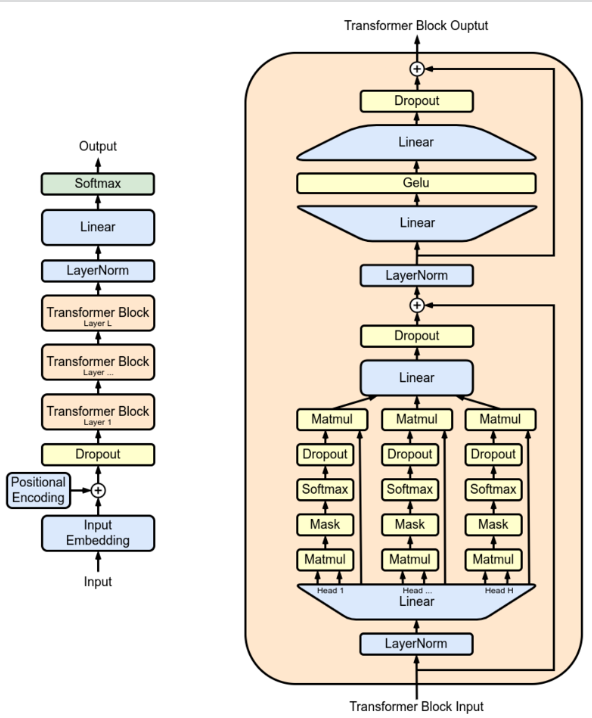
GPT-1 consists of a total of 117 million parameters. This size makes it a substantial model capable of understanding complex language structures, but still more manageable compared to later versions like GPT-2 and GPT-3.
GPT-1 was pre-trained on the BookCorpus, which includes 4.5 GB of text from 7000 unpublished books of various genres. This diverse and extensive dataset provided a rich linguistic foundation for the model.
Here is the summary of the differences in BERT & GPT neural network architectures:
- Architecture: BERT utilizes only the encoder part of the Transformer architecture, processing the text in a bidirectional manner. GPT-1, on the other hand, uses only the decoder part of the Transformer architecture, processing the text in a unidirectional manner from left to right.
- Directionality: BERT is bidirectional, meaning it processes text in both directions simultaneously, whereas GPT-1 is unidirectional, processing text from left to right.
- Attention Heads and Layers: Both models use multi-head attention, but they differ in the number of layers and heads. BERT has two versions with different configurations, while GPT-1 has a 12-level, 12-headed structure.
- Training Objective: BERT is trained using a masked language model task and next sentence prediction, while GPT-1 is trained to predict the next word in a sequence.
- Pre-training Data: Both models are pre-trained on extensive text corpora, but they differ in the specific datasets used.
- Output Layer: BERT is fine-tuned with task-specific layers, while GPT-1 uses a linear-softmax layer for word prediction.
Conclusion
In the ever-evolving landscape of natural language processing, BERT and GPT stand as two monumental models, each with its unique strengths and applications. Through our exploration of their architecture, training objectives, real-world examples, and use cases, we’ve uncovered the intricate details that set them apart. BERT’s bidirectional understanding makes it a powerful tool for tasks requiring deep contextual insights, while GPT’s unidirectional approach lends itself to creative text generation. Whether you’re a researcher, data scientist, or AI enthusiast, understanding these differences can guide your choice in model selection for various projects.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me