In the field of AI / machine learning, the encoder-decoder architecture is a widely-used framework for developing neural networks that can perform natural language processing (NLP) tasks such as language translation, text summarization, and question-answering systems, etc which require sequence-to-sequence modeling. This architecture involves a two-stage process where the input data is first encoded (using what is called an encoder) into a fixed-length numerical representation, which is then decoded (using a decoder) to produce an output that matches the desired format.
In this blog, we will explore the inner workings of the encoder-decoder architecture, how it can be used to solve real-world problems, and some of the latest developments in this field. Whether you are a seasoned data scientist or just starting your journey into the world of deep learning, this blog will provide you with a solid foundation to understand the encoder-decoder architecture and its applications.
What’s Encoder-Decoder Architecture & How does it work?
The encoder-decoder architecture is a deep learning architecture used in many natural language processing and computer vision applications. It consists of two main components: an encoder and a decoder.
- The encoder takes in an input sequence and produces a fixed-length vector representation of it, often referred to as a hidden or “latent representation.” This representation is designed to capture the important information of the input sequence in a condensed form.
- The decoder then takes the latent representation and generates an output sequence based on it. The most fundamental building block or component used to build the encoder-decoder architecture is the neural network.
Different kinds of neural networks including RNN, LSTM, CNN, and transformer can be used based on encoder-decoder architecture. Encoder-decoder architecture is found to be most suitable for the use cases where input is a sequence of data and output is another sequence of data (sequence-to-sequence modeling) like the popular text generation use case.
How does encoder-decoder architecture work?
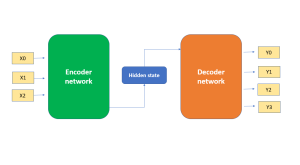
In this architecture, the input data is first fed through what’s called an encoder network. The encoder network maps the input data into a numerical representation that captures the important information from the input. The numerical representation of the input data is also called a hidden state. The numerical representation (hidden state) is then fed into what’s called the decoder network. The decoder network generates the output by generating one element of the output sequence at a time. The following picture represents the encoder-decoder architecture as explained here. Note that both input and output sequences of data can be of varying length as shown in the picture below.
A popular form of neural network architecture called autoencoder is a type of an encoder-decoder architecture. An autoencoder is a type of neural network architecture that uses an encoder to compress an input into a lower-dimensional representation, and a decoder to reconstruct the original input from the compressed representation. It is primarily used for unsupervised learning and data compression. The other types of encoder-decoder architecture can be used for supervised learning tasks, such as machine translation, image captioning, and speech recognition. In this architecture, the encoder maps the input to a fixed-length representation, which is then passed to the decoder to generate the output. So while the encoder-decoder architecture and autoencoder have similar components, their main purposes and applications differ.
Example: Encoder-Decoder Architecture with Neural Networks
We can use CNN, RNN & LSTM in encoder-decoder architecture to solve different kinds of problems. Using a combination of different types of networks can help to capture the complex relationships between the input and output sequence of data. Here are different scenarios or problem examples where CNN, RNN, LSTM, transformer, etc. can be used:
- CNN as Encoder, RNN/LSTM as Decoder: This architecture can be used for tasks like image captioning, where the input is an image and the output is a sequence of words describing the image. The CNN can extract features from the image, while the RNN/LSTM can generate the corresponding text sequence. Recall that CNNs are good at extracting features from images and this is why they can be used as the encoder in tasks that involve images. Also, RNNs/LSTMs are good at processing sequential data such as sequences of words, and can be used as the decoder in tasks that involve text sequences.
- RNN/LSTM as Encoder, RNN/LSTM as Decoder: This architecture can be used for tasks like machine translation, where the input and output are both sequences of words of varying length. The RNN/LSTM in the encoder can encode the input sequence of words into a hidden state or numerical representation, while the RNN/LSTM in the decoder can generate the corresponding output sequence of words in different languages. The picture below represents encoder-decoder architecture with RNN used in both encoder and decoder networks. The sequence of words as input is in English and the output is machine translation in German.
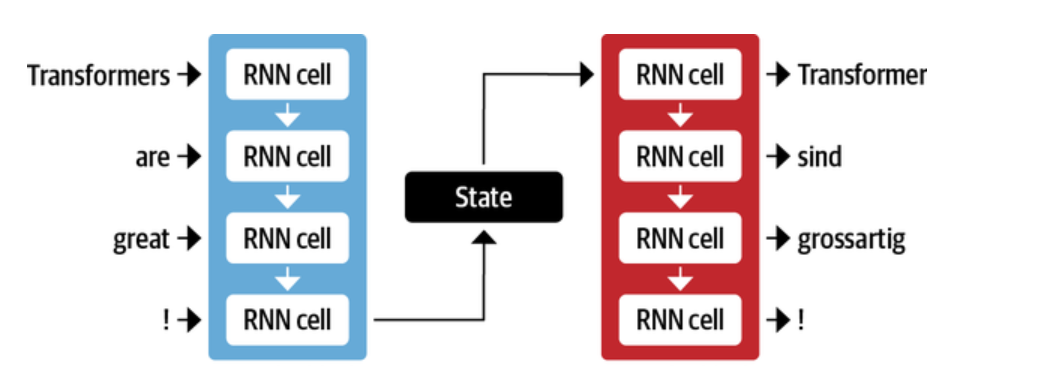
There is a disadvantage to using RNNs in encoder-decoder architecture. The final numerical representation or hidden state in the encoder network has to represent the entire context and meaning of a sequence of data. If the sequence of data is long enough, it may get challenging and the information about the start of the sequence might get lost in the process of compressing entire information in the form of numerical representation.
There are a few limitations one needs to keep in mind when using different types of neural networks such as CNN, RNN, LSTM, etc in encoder-decoder architecture:
- CNNs can be computationally expensive and may require a lot of training data.
- RNNs/LSTMs can suffer from vanishing/exploding gradients and may require careful initialization and regularization.
- Using a combination of different types of networks can make the model more complex and difficult to train.
Applications of Encoder-Decoder Neural Network Architecture
The following are some of the real-life/real-world applications of encoder-decoder neural network architecture:
- Transformer models: The Transformer model, as originally proposed in the paper “Attention Is All You Need” by Vaswani et al., consists of both an encoder and a decoder. Each part is composed of layers that use self-attention mechanisms. The encoder processes the input data (like text) and creates context-rich representations of it. The decoder uses these representations along with its inputs (like the previous word in a sentence) to generate an output sequence. T5 (Text-To-Text Transfer Transformer) utilizes an encoder-decoder architecture. Then, there is another example of BART (Bidirectional and Auto-Regressive Transformers) that combines a bidirectional encoder (like BERT) with an autoregressive decoder (like GPT).
- Make-a-Video: Recently introduced AI system by Facebook / Meta namely Make-a-Video is likely powered by deep learning techniques, possibly including an encoder-decoder architecture for translating text prompts into video content. This architecture, commonly used in sequence-to-sequence transformations, would use an encoder to convert input text into a dense vector representation, and a decoder to transform this vector into video content. However, given the complexity of creating video from text, the system might also employ advanced generative models like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), which excel in generating high-quality, realistic images. Further, to learn mappings from text to visuals and understand the dynamics of the world, it likely leverages large amounts of paired text-image data and video footage, possibly employing unsupervised learning or self-supervised learning techniques.
- Machine translation: One of the most common applications of the Encoder-Decoder architecture is Machine Translation. This is where a sequence of words in one language as shown above (encoder-decoder architecture with RNN) is translated into another language. The Encoder-Decoder model can be trained on a large corpus of bilingual texts to learn how to map a sequence of words in one language to the equivalent sequence in another language.
- Image captioning: Image captioning is another application of encoder-decoder architecture. This is where an image is processed by an encoder (using CNN), and the output is passed to a decoder (RNN or LSTM) that generates a textual description of the image. This can be used for applications like automatic image tagging and captioning.
Conclusion
In conclusion, the encoder-decoder architecture has become a popular and effective tool in deep learning, particularly in the fields of natural language processing (NLP), image processing, and speech recognition. By using an encoder to extract features and create a hidden state (numerical representation) and a decoder to use that numerical representation to generate output, this architecture can handle various types of input and output data, making it versatile for a range of real-world applications. Encoder-decoder architecture can be combined with different types of neural networks such as CNN, RNN, LSTM, transformers etc. to enhance its capabilities and address complex problems. While this architecture has its limitations, ongoing research and development will continue to improve its performance and expand its applications. As the demand for advanced machine learning solutions continues to grow, the encoder-decoder architecture is sure to play a crucial role in the future of AI. Please drop a message if you want to learn the concepts in more detail.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Coefficient of Variation in Regression Modelling: Example - November 9, 2025
- Chunking Strategies for RAG with Examples - November 2, 2025
- RAG Pipeline: 6 Steps for Creating Naive RAG App - November 1, 2025
[…] its operation. Let’s explore the Encoder-only Transformer, Decoder-only Transformer, and Encoder-Decoder Transformer architectures, uncovering their potential applications. To get a good understanding of this topic, you might want […]